This blog post was originally published in the September 2015 edition of BDTI's InsideDSP newsletter. It is reprinted here with the permission of BDTI.
"The economy, stupid" was one of the phrases that strategist James Carville hung on a sign in Bill Clinton's 1992 presidential campaign headquarters – a reminder to focus on what's most important. In a similar vein, the reminder "It's the memory bandwidth, stupid" should probably be prominently displayed wherever computer vision software developers work.
As I've written about before, it has recently become feasible to implement sophisticated computer vision algorithms on embedded and mobile processors, which enables functions as diverse and face recognition, collision avoidance and automated inspection. But "feasible" doesn't mean "easy". Computer vision algorithms typically apply complex algorithms to video data in real-time, which means they consume lots of computing power. How much? Well, the range is vast, considering the diversity of applications and algorithms, but I find that most interesting applications consume 10s of billions of compute operations per second.
These days, many high-end embedded and mobile processors are capable of delivering this level of performance, but coaxing them to do so can be a significant challenge. Things get even more difficult if you're trying to minimize power consumption – which usually means moving work off the CPU and onto more specialized parallel co-processors.
The combination of high data rates (for example, a 720p 60 frame-per-second video stream comprises 166 million pixel color components per second), complex algorithms and specialized parallel processors means that, often, software must be carefully optimized to create competitive products. Of course, developers of embedded software for applications like hearing aids and wireless modems are accustomed to employing aggressive optimization techniques to squeeze demanding algorithms into minimal cost and power consumption. But the situation is qualitatively different with computer vision algorithm software, due to the massive amounts of data involved and the use of heterogeneous processors.
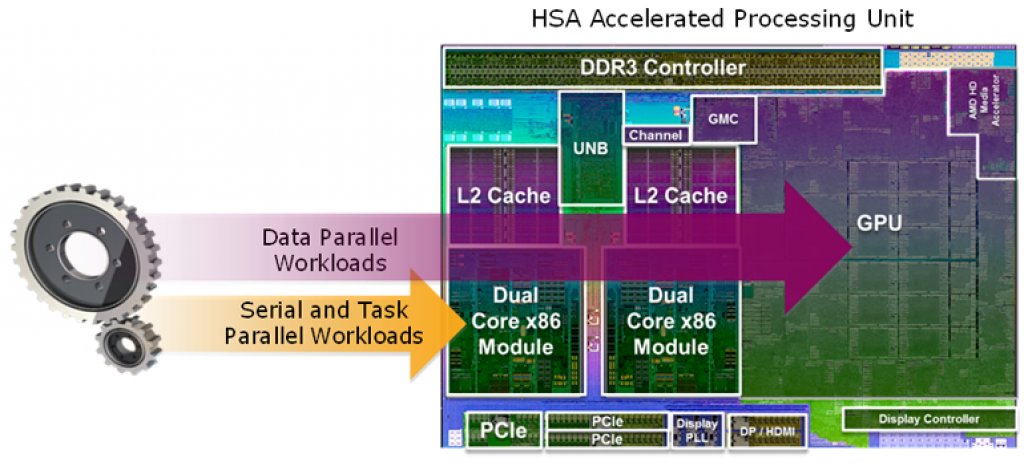
Today, for example, one of the most common forms of heterogeneous processing for computer vision applications is the combination of a CPU and a GPU. In this scenario, rather than being used for 3D graphics, the GPU is pressed into service as a parallel processing accelerator. This approach has been popular in server and PC applications for years, and is starting to become common in mobile and embedded systems as well.
These so called "general-purpose GPUs" (or GPGPUs) excel at data-parallel operations, such as filtering, where the same basic operation is applied to a large set of inputs. They are less suited for algorithms where math operations are interleaved with complex decision-making.
As a consequence, it's common to find that in a given computer vision algorithm, there are a few processing steps that are very well suited to the GPU, interleaved with others that should clearly remain on the CPU. The obvious thing to do is parse the algorithm so that the GPU performs the steps that it's good at, while the CPU does the rest. However, the cost of moving large amounts of data back and forth between the CPU and the GPU can easily cancel out the speed advantage gained from using the GPU.
This issue can often be overcome with clever engineering: modifying algorithms, allocating larger chunks of processing steps to the GPU (even including some that would run faster on the CPU), dividing image frames into smaller chunks, and so on. But recent experience with several projects of this type has highlighted for me that the critical optimization challenges in such applications are fundamentally different from those in other, less data-intensive applications. This suggests the need for different tools and techniques to aid in optimization – indeed, different ways of thinking about optimization. As a simple example, it may be more important to understand the performance characteristics of the chip's DMA controllers and DRAM interface than the details of its parallel math instructions.
We do have some tools, techniques and paradigms optimizing memory-intensive streaming applications today, but in general they are not widely known and used. This gap presents both threats and opportunities. The threats include the possibility that most developers won't be able to obtain anything close to the full potential performance of today's sophisticated SoCs (which often include not only multicore CPUs and GPUs, but also DSPs, FPGAs and other co-processors). The opportunities include the chance for chip companies to gain significant competitive advantage by providing developers with better tools and techniques to address the distinctive optimization challenges of vision applications. And system companies able to master these challenges will be able to bring products to market with amazing capabilities.
For more on this topic, check out the videos of the recent Embedded Vision Summit presentations from Roberto Mijat of ARM and Harris Gasparakis of AMD. (Registration is required to access these videos on the Embedded Vision Alliance website, but it’s free and painless.)