This blog post was originally published at Cadence's website. It is reprinted here with the permission of Cadence.
We’re not yet riding in driverless cars, yet today’s vehicles are doing more for us than perhaps Henry Ford could have imagined. From pedestrian detection to driver monitoring, parking assistance and infotainment systems, these features are making our rides safer, smoother, and more interesting. And, they all have at least one thing in common: their reliance on image and video data.
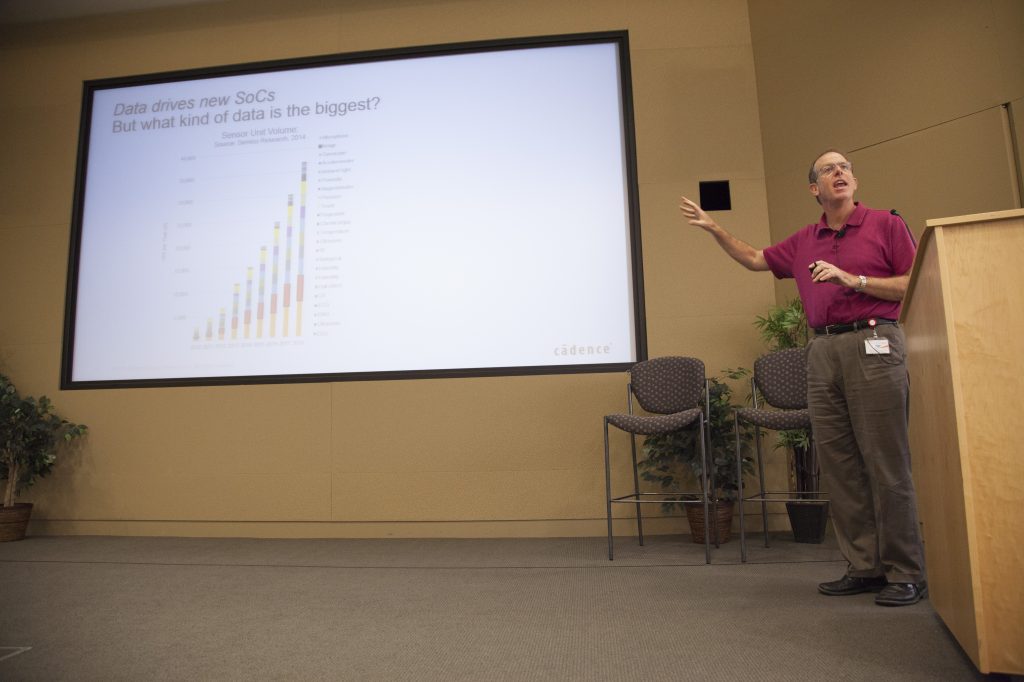
Indeed, the single biggest driver of modern electronics is vision and image processing. And automotive applications like advanced driver assistance systems (ADAS) are among the highest profile users of this type of processing, noted Dr. Chris Rowen, CTO of Cadence’s IP Group and a Cadence Fellow.
Cadence Fellow Chris Rowen discusses automotive vision applications during a lunchtime talk at the company's San Jose headquarters.
During a recent lunchtime talk at the company’s San Jose auditorium, Rowen traced the evolution of image and vision processing systems. This evolution began with the growing ubiquity of image sensors, due to their low cost, speed, and high resolution levels. Image-processing algorithms are also evolving quickly. Capabilities such as object detection, tracking, and identification are leading to functions such as scene analysis and decision making. Neural networks are universally trainable and fast to execute. Integrated systems, in turn, are becoming easier to implement—consider multi-sensor types, electro-mechanical systems, and cloud-distributed software.
All of this, said Rowen, has given rise to new applications in areas such as ADAS, drones and robots, security, and mobile. ADAS represents the largest growth opportunity within automotive electronics and is a huge driver of overall vision SoC development, Rowen noted.
People Aren’t the Best at Real-Time Recognition
The real-time recognition that is critical for ADAS and other applications to function properly is no easy task. Consider the traffic signs you see on the road—often, these signs are obscured by shadows, bad lighting or graffiti, or they’re bent. For a machine to achieve this type of recognition, the layered, methodical approach of convolutional neural networks (CNN] comes into play. With 99.4% accuracy, “CNN now routinely is doing better than human recognition,” said Rowen.
CNN takes a set of inputs (like the capture of a traffic sign), applies a convolution (a multiply-add), and calculates several different features to generate primitive features. The process is then repeated: the input now begins with the primitive features, another layer of convolutions is applied, and then another to identify all of the building blocks of a visual element (in this case, our traffic sign).
Given the data-intensive processing required for CNN, Tensilica processors and DSPs are well equipped to execute these demanding algorithms. Rowen then provided a detailed discussion of Cadence’s recently announced Tensilica Vision P5 DSP. A fourth-generation SIMD VLIW imaging and vision processor, the Tensilica Vision P5 DSP delivers 4X to 100X the performance of traditional mobile CPU plus GPU systems at a fraction of the power/energy. You can learn more about the Tensilica Vision P5 DSP from this white paper.
Vision processing, noted Rowen, is certainly becoming a central reason for organizations to invest in advanced process nodes. Concluded Rowen, “The Vision P5…is a quantum step in performance from what we’ve done before in the vision space. It is driving us to have much more specific image libraries, tools, and development environments, driven in part by heavy involvement with third parties and customers doing in-house development of software.”