
This technical article was originally published at Basler's website. It is reprinted here with the permission of Basler.
A status report with a focus on deep learning and Convolutional Neural Networks (CNNs)
What are neural networks and why are they such a topic of interest for industrial image processing? They eliminate the need for developers to define differentiation criteria; neural networks instead learn the criteria on their own and apply that “knowledge“ to precision tasks. Yet they inherently cannot work reliably and unerringly out of the box. They must first receive in-depth training. This white paper describes in detail how this training can be conducted, the preparatory steps required for it and the individual development steps involved with setting up a neural network.
Introduction
Apples and Pears
They say you should never compare apples and oranges, but when it comes to machine vision systems, apples and pears aren‘t much better. Even so, there is strong demand for systems that can handle precisely that kind of task: differentiating between the two types of fruit based on image data.
Traditionally, developers were left to ponder which criteria were necessary to differentiate between the two fruits. One can imagine a relatively simple approach: while apples have reddish tones, pears are green. One criterion would hence be color information. Yet remember: some apples may have green tones as well, such as when they are unripe. Were color to be used as the sole criterion, then it can be expected that unripe apples would be misidentified as pears. To ensure better accuracy, it makes sense to add in an additional criterion: the shape. While apples tend to have a round form, pears are more elongated.
Figure 1: Visualization of the classification result of apples and pears through a camera-based machine learning system.
So in this classification case, differentiation is relatively simple. The criteria (typically called “Features“) aren‘t hard to determine. What do we do, however, when we‘re sorting between different types of apples? Color and shape aren‘t necessarily sufficiently different to make identification possible. Our self-defined (“hand-crafted“) features are pushed to their limits in this example.
The more difficult the classification between different classes of objects, the more crucial it becomes for developers to compose an algorithm capable of automatically detecting the features that can separate the classes from one another.
Machine Learning algorithms are one promising solution, especially Convolutional Neural Networks, or CNNs for short. CNNs can automatically learn criteria necessary to differentiate between objects. That makes them useful not just for the most difficult classification problems, but rather for any application case that requires tremendous flexibility.
Convolutional Neural Networks (CNNs): A Success Story
The concept behind CNNs is not new. Back in 1968, Canadian neurobiologist David Hubel worked together with Swedish neurophysiologist Torsten Wiesel on the visual cortex of felines. The visual cortex is the portion of the brain dedicated to processing visual data into usable information. Their goal was hence to answer questions about the way in which the brain generates contextually useful information about objects from the visual image information that passes into the brain via the eyes (“I see an apple“). The two researchers presented cats with bars of light in various orientations, determining in the process that different cells within the visual cortex were activated depending on how the bars were oriented. They were also able to demonstrate that complicated light patterns, such as eye shapes, led to activation of cells in deeper- situated sections of the visual cortex.
Hubel and Wiesel‘s efforts resulted in a model capable of describing the activation of cells and their forwarding of specific image information. This formed the basis for the modeling of computer-assisted image classification.
30 years later, French computer scientist Yann LeCun would be fascinated with Hubel and Wiesel‘s work. He overlaid the descriptions of the functionality of the visual cortex onto an algorithm — creating the first CNN in the process.
Despite his efforts, CNN remained unsuited for practical application for many years. The primary reason for this is because CNNs require an enormous amount of computational power. CPU processors that process the data using serial techniques, meaning one data record after the other, would require years before the network had learned enough to work.
It was on the advent of Graphical Processor Units (GPUs), which process data in parallel, that the CNN model once again became relevant — and in fact in recent years it has enjoyed a strong rebirth. Researchers are celebrating tremendous successes with handwriting recognition, medical diagnostics, early warning systems for autonomous vehicles, object identification in robotics and biometrics. CNNs have often produced better results in challenging applications than other competing learning technologies. The billions invested by large firms such as Google, IBM, Microsoft and Facebook show the enormous interest and potential for this technology.
CNNs aren‘t just processor-intensive; they‘re also hungry for data. To train a CNN from scratch, huge amounts of already-classified image data are required. Developers today can acquire freely-accessible databases stocked with this information. One of the most popular image databases is ImageNet1. It contains over 14 million classified images. There are also a series of databases specialized in specific classification problems. For example, there is a database called German Traffic Sign Recognition Benchmark with more than 50,000 images of traffic signs. In that particular example, CNNs achieved a 99.46% success rate during a 2012 test — better than the 98.84% rate achieved by human classifiers. In practice however, developers are usually facing a highly specialized classification problem, so that there is no way around acquiring their own stock of image data. Fortunately, there is no need to collect millions of images. A technological trick known as “transfer learning“ allows the necessary volume to be reduced greatly, in some cases to just a few hundred or thousand images.
Major portions of the software stack are freely accessible to developers. There is a large number of frameworks for CNNs: Caffe, Torch and Theano – a long list of software libraries is dedicated to this topic. In November 2015, Google even open-sourced its own internal machine learning software, TensorFlow, which is an integral component of various Google products from image searches to Google Photo.
CNNs are also celebrating a growing role in the world of Machine Vision applications. According to the Embedded Vision Developer Survey2 conducted in 2016 by the Embedded Vision Alliance, 77% of respondents reported current or planned use of neural networks for the handling of classification tasks. This trend is rising: the same survey, conducted in 20153, found only 61%. That same 2016 study also found that 86% of CNN neural networks were being used for classification algorithms. The results show that companies no longer need the size and resources of a company like Google or Facebook to develop a product or service based on CNNs.
Development process of CNNs
Imagine you really did need to separate apples from pears, as part of an industrial-scale fruit-sorting line, and furthermore want automated sorting of the different fruit into batches based on its quality. The following process steps would be required:
- Collecting image data
- Design of the CNNs
- Execution of the self-learning algorithm
- Evaluation of the trained CNN (and reworking of steps 1, 2 or 3 as needed)
- Deployment of the trained CNNs
The following text presents the individual steps in detail.
Collecting image data
The basic principle of machine learning (or, to be precise, “supervised machine learning“), involves teaching the computer about the problem to be solved, using many examples. For the fruit sorting line, this would involve taking many pictures showing individual apples or pears of various types, qualities and sizes. One must also record a precise description of what can be seen on each image, meaning specific values (“labels“) for all three properties (see figure 2). This creates a set of input/output pairs which are then almost literally shown to the computer‘s eyes, instructing it which image should yield what answer (“Braeburn, Class I, Size M“).
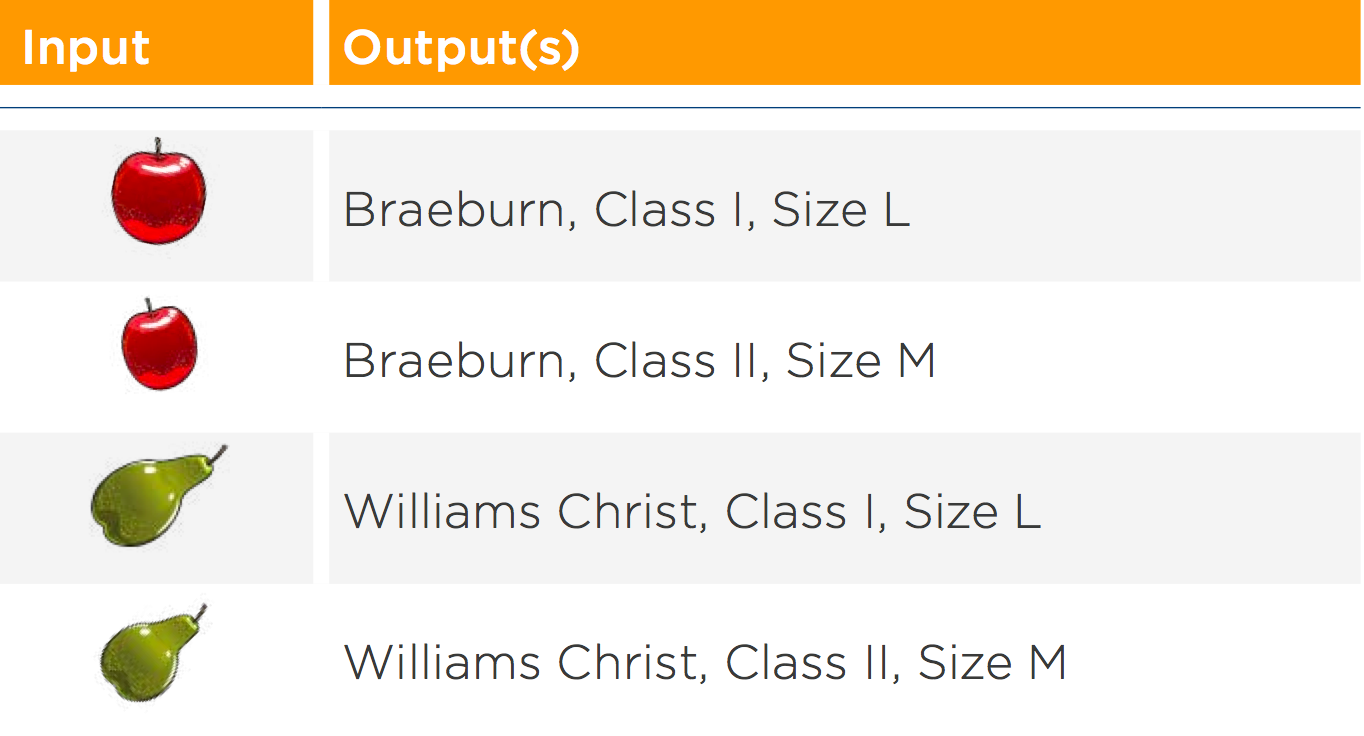
Fig. 2: Image data with appended text output. The neural network can use these input/output pairs to learn differentiation.
It is essential that during this recording of the data all possible combinations of the properties to be measured (in this case the types, qualities and sizes) are present in the images. In general, it must be taken care of that the visual variations of the application (not just the fruit types, but also the various lighting conditions, backgrounds and position of the fruit in the image) are represented with the sample images. From a practical standpoint, it is very advisable to take the images in precisely the same manner in which they will be photographed in the final productive environment. Recording the properties of the type, quality and size of the fruit in each image should be undertaken by trained specialists; only the actual fruit salesperson, not the system programmer, will be able to properly assess the quality of the goods.
One extremely important question during data collection is the number of sample images required: as one can imagine, the greater the variance in the images, the higher the number of sample images required. As mentioned in the introduction, applications such as ImageNet can quickly need millions of images. Such a data acquisition operation is rarely economical, however, there are different options to solve this. As with traditional image processing systems, the production environment can be more strictly controlled. In addition, the collected data volume can also be artificially enlarged (data augmentation) by applying systematic changes to the color tones, image skew and scaling of already captured images and then use them in as new samples. It is also possible to work with service partners using crowdsourcing approaches to achieve highly affordable data collection.
Design of the CNN
State-of-the-art CNNs stand out thanks to a variety of layers with various functionality. Unlike the old-fashioned fundamental multilayer perceptrons4, current networks are formed from a sequence of alternating convolutional and pooling layers (see figure 3).
Fig. 3: Setup of a state-of-the-art CNN. The input (an image) is processed in a series of different layers up through output.
The convolution layers are turning the pixel values for adjacent regions of the input image into one single value by applying a mathematical “convolution“ operation. The convolution operation acts like a feature detector that only looks for specific properties in the image (such as recognizing a horizontally oriented edge). A pooling layer is established further along in the processing chain, summarizing the amplitudes of these feature detectors for a larger image region. These layers form a pyramid, leading to increasingly specialized feature detectors that evaluate larger and larger regions of the image. Returning to the example of the fruit sorting line, one can imagine that the first layers of the network respond to the spot patterns that are characteristic for pears; the upper layers by contrast verify that the visual coherence of stem, its shadow and the upper portion of a specific apple type are all in agreement to allow the network to calculate which fruit type, quality and size is visible.

Figure 4: A trained network has so-called feature detectors that react to specific structures in the image. While the first layers of thenetwork react more to the spot patterns that are characteristic for pears, higher-level layers react to the visual coherence of stem and shadows.
The precise structure of a CNN is in practice typically a variation on networks developed by researchers, such as AlexNet5, VGG Net6 or GoogLeNet7. Adjustments are typically needed, as the specific task to be solved can have specific requirements in terms of resolution of the input image or available computational power. These networks are programmed using the aforementioned open source deep learning frameworks, which provide all various core elements, including the convolution layer, as software functions. Depending on the requirements, a fair degree of specialized knowledge is needed. An initial feasibility study can typically be implemented with just a few customizations, while a true 100%-optimized solution requires intensive work from highly-experienced experts.
Execution of the self-learning algorithm
Once the data and design of the CNN are established, a so-called self-learning algorithm must be executed. It, in its different variants, always comes as part of the deployed deep learning framework. These algorithms are based on the “back propagation algorithm“ concept, which at its core is a (stochastic) optimization process. These algorithms are responsible for configuring the free parameters (“weights“) of the CNNs so that the network works for the provided data. The self-learning algorithm is hence used to “train“ the network.
Executing this kind of self-learning algorithm is the most processor-intensive step in the entire development process for an application solution: if you must use millions of sample images, then you inherently need one or more better GPU servers (more details on this in the next section), which can often take from several days to weeks to process the data. There is only one way to avoid this extra complication: using the transfer learning trick for your application.
As with the design of the networks, different levels of quality expectations can necessitate different levels of specialized knowledge: every available self-learning algorithm will have different parameters (such as learning or decay rate, batch size) that affect its performance. There are also certain tricks such as the Dropout, Batch and Layer Normalization procedure, each of which helps make the ultimate CNN more robust. One must also be clear that no self-learning algorithm can be deterministic; it must also always contain a stochastic component. This means that developers must typically evaluate interim results and make manual changes over the execution of the algorithm.
Evaluation of the network
The trained CNN resulting from the self-learning algorithm must be statistically evaluated. This involves taking a set of sample images where one already knows what they show and comparing them with the values calculated by the network. This produces the error rate, which typically indicates what percentage of the image content properties have been correctly identified by the network. If the results do not satisfy the pre-defined quality requirements — for example, identifying 5% of Braeburn apples as Granny Smiths is surely unacceptable— then one must return to the prior three steps of development and improve them.
In principle, the data required for this evaluation is always on hand, since precisely that data was collected for training the networks. The key thing is never to test the network using images that it has already seen during training. Doing so would automatically lead to underestimation of the system“s true performance, and the real errors will then only show up during production. In an extreme case, namely, if test and training data are completely identical, then the network learns those images by heart, earns a perfect score during evaluation, then fails spectacularly when new images are entered into the production system. To avoid this problem, it is important to deploy procedures such as cross-validation, whereby data is systematically separated during the training and evaluation phases.
Deployment of the trained CNNs
Once the results of the last step are satisfactory, then the next step is transferring the trained network into a productive system. The popular deep learning frameworks offer plentiful tools to package the various necessary elements of the network into software libraries so that they can be linked to other components of the system, such as to a connected camera or to control the reactions to the detected image content.
Additional work can arise if there are specific requirements for runtime performance during the assessment of the image by the CNN. This typically occurs because the hardware setup when training the network (GPU server) can be very different from the production environment. One might potentially be forced to use special methods (such as quantization) to reduce the already-trained network to fit on the target system. This technically- challenging activity can however by avoided through good network design.
Transfer Learning
As already mentioned, the CNNs are highly data-hungry in their pure form, and equally processor-intensive during training. Fortunately there is frequently a good option for simplifying life (as a developer), specifically by using the method known as transfer learning. This makes it possible to take a network that has been trained using a high number of general images — such as those found in the ImageNet database — and adapting it to the concrete application at hand with just a few domain-specific images. The developer “shows“ a network such as AlexNet, VGG Net or GoogLeNet the application-specific training images and then stores the resulting values in one of the last layers of the network as feature vectors. These vectors represent the images presented to the network in a highly compact manner and can be classified through standard machine learning procedures such as logistical regression, support vector machines or “simple“ multilayer perceptrons. This way the CNN replaces traditional image processing tools such as Hough transformation, SIFT Feature, Harris Corner or Canny Edge detectors. In recent years, comparative scientific studies and numerous practical applications have shown clearly that the learned feature vectors in the CNNs are significantly more applicable than the traditional, handcrafted feature detectors.
Processors for CNNs
During the development of CNNs, differentiation is made as indicated above between the training and the application process. The hardware requirements for these two steps are quite different.
Fig. 5: Graphical Processor Units (GPUs) are the preferred hardware for the CNN training process. For integration and application in an embedded vision system, Field Programmable Gate Arrays (FPGAs) are used as the processing units within which the trained network runs.
Where possible, high-performance GPU processing units should be used for the CNN training process. Manufacturers like NVIDIA offer AI supercomputers such as the DGX-1 that have been specially tailored for this task; it is also possible to use the significantly more affordable NVIDIA Titan X cards. NVIDIA reports that these can train CNNs up to 80x quicker than common CPUs.
Once the network has been trained, it can be transferred to an embedded vision system with low hardware requirements and a processing unit. Field-Programmable Gate Arrays (FPGAs) are recommended for the processing units, as these can process image data in parallel and at high speeds.
The key components for this kind of embedded vision system are hence a camera that can record the image data to be classified; a cable to transfer that image data; and a processing unit used by the CNN to classify the image data.

Fig. 6: Embedded Vision System for practical application of CNNs. The embedded camera (Basler dart BCON) is connected via a flexible ribbon cable to a processing unit with FPGA (Xilinx Zynq). The classification of the image data runs on the FPGA and can thus be calculated in real time.
Embedded vision systems with FPGAs offer a series of benefits that make them perfect for use with CNNs:
- FPGAs are capable of executing convolution operations and other mathematical operations needed by the network to classify an image, all in parallel and at high speeds. This setup offers image analysis and classification in real time.
- FPGAs require less power than GPUs and are hence more suited for low-power embedded systems. One recently published report from Microsoft Research8 declared that FPGAs are up to 10x more energy- efficient than GPUs.
- The large on-chip storage and bandwidth of FPGAs make it possible for CNNs to classify even high-resolution images in real time.
- Cameras with direct FPGA connections (such as Basler‘s dart BCON) deliver the data directly to the FPGA. This is a key advantage in processor-intensive applications such as CNNs, as data transferred via USB, for example, must run through various hardware components (such as a host controller) before arriving at the FPGA. A direct camera/FPGA connection thus promotes a high-efficiency implementation.
Brief Summary
- While developers working on traditional classification problems had to work out their own hand-crafted “features“ or criteria, a CNN learns these criteria for differentiation on its own.
- The networks learn these differentiation criteria automatically using a set of images where it is known what is being shown. This learning process is highly resource-intensive both in terms of the volume of images required as well as in terms of processing power.
- Nevertheless, the principle of transfer learning makes it possible to implement production-ready solutions with a low volume of images and processing power.
- Embedded vision systems with a direct camera FPGA connection (such as Basler BCON) are outstandingly well suited for use with CNNs.
- According to the Embedded Vision Developer Survey9 conducted in 2016 by the Embedded Vision Alliance, 77% of respondents reported current or planned use of neural networks for handling of classification tasks within a machine vision application.
By Peter Behringer
Product Market Manager, Basler
Dr. Florian Hoppe
Co-Founder and Managing Director, Twenty Billion Neurons GmbH (TwentyBN)
1 http://image-net.org/
2 Embedded Vision Developer Survey Results Report. Embedded Vision Alliance, September 2016
3 Embedded Vision Developer Survey Results Report. Embedded Vision Alliance, September 2015
4 https://de.wikipedia.org/wiki/Perzeptron#Mehrlagiges_Perzeptron
5 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
6 https://arxiv.org/pdf/1409.1556.pdf
7 https://www.cs.unc.edu/~wliu/papers/GoogLeNet.pdf
8 K.Ovtcharov, O.Ruwase, J.-Y.Kim, J.Fowers, K.Strauss, E.Chung. Accelerating Deep Convolutional Neural Networks Using Specialized Hardware. February, 2015.
9 Embedded Vision Developer Survey Results Report. Embedded Vision Alliance. September 2016