This blog post was originally published at Intel's website. It is reprinted here with the permission of Intel.
In this blog series, we’re looking at one of Intel’s branches of AI research, neuromorphic computing. The goal of neuromorphic computing is to apply the fundamental properties of neural computation found in nature to breakthroughs in non-Von Neumann compute architectures and novel AI algorithms. These properties include fully integrated memory and computing, fine-grain parallelism, pervasive feedback and recurrence, massive network fan-outs, low precision, stochastic dynamics, and continuous adaptation. One widespread property of natural neural networks is their use of spikes. This blog series focuses on the question of whether spiking neural networks and hardware architectures optimized to run them, such as our Loihi research chip, offer advantages for future AI applications.
In part one of the series we covered a theoretical perspective on how spike-based computation fundamentally optimizes energy efficiency. In part two, I’ll turn to an important example that shows how a spiking neuromorphic processor such as our Loihi research chip can deliver surprising gains in performance and efficiency for a class of neural networks with activity rates encoded as sequences of spikes in time.
Spikes can efficiently compute important rate-based networks
Many neural algorithms, including all conventional deep networks, use a “rate-based” model of neural activity. In the biological interpretation of this model, neural network states are continuous, corresponding to the average spike rates of neurons. Intuitively, it may seem inefficient to compute the evolution of such a rate variable by transmitting many spike messages. Our intuition tells us that we should just send the rate values once to wherever they need to go and then update all neural state variables in a single synchronized update. This is what deep learning accelerators do today.
Surprisingly, we’ve found cases where computing such algorithms with spikes will produce results faster and with lower energy. The best and simplest example of this effect comes from a problem known as Lasso optimization, or l1-regularized feature representation. In words, Lasso tries to represent an input signal, such as an image, using the fewest possible features selected from a large dictionary of available features. Lasso is used across many areas of computing such as compressed sensing and signal de-noising. However, Lasso is conventionally very slow to compute. Researchers including Yann LeCun have been interested for some time in finding fast approximations for Lasso in order to perform sparse feature extraction for inference applications. The brain, in fact, performs sparse feature coding in a Lasso-like way in the V1 region of the visual cortex.
With Lasso, we can mathematically derive a rate-based neural network implementation, the Locally Competitive Algorithm (LCA), shown in Figure 1, and can continue transforming it with full mathematical rigor to a spike-based neural network. We can then compare the characteristics of a spiking LCA network running on Loihi to the characteristics of the best conventional Lasso solvers running on a CPU. Here we will consider the well-known FISTA solver, which is effectively an optimized implementation of the rate-based LCA formulation expressed as gradient descent.
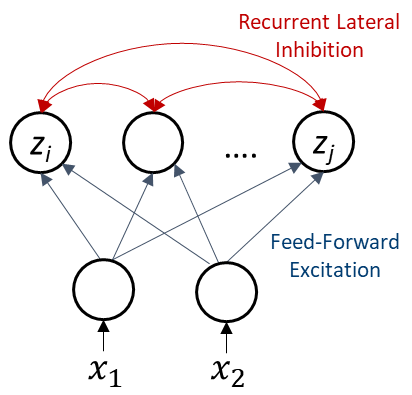
Figure 1. Recurrent neural network structure of the Locally Competitive Algorithm.
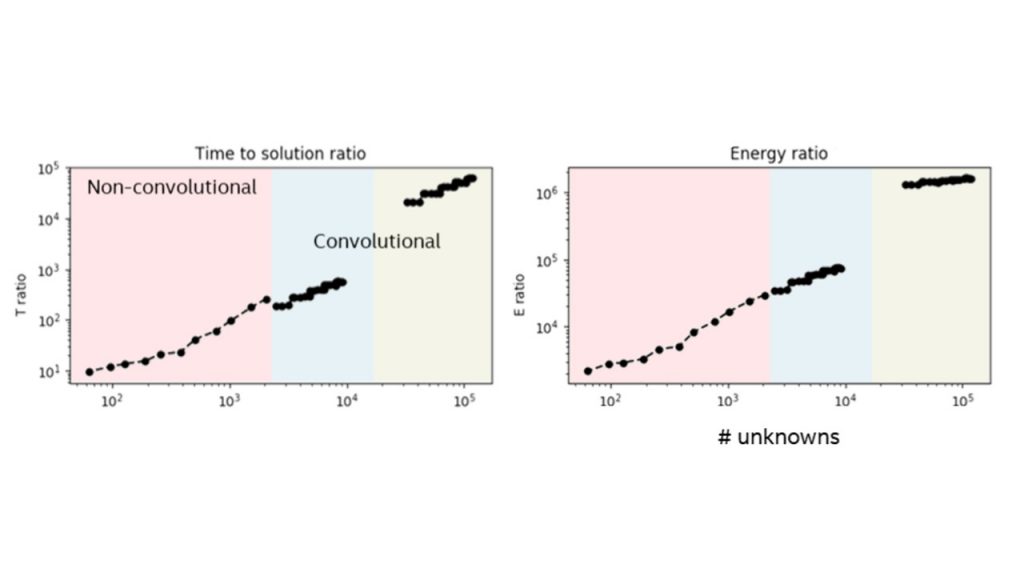
As shown in Figure 2, when we measure Loihi’s time and energy to solve a variety of Lasso problems spanning 60 to 120,000 unknowns, and compare them to the values obtained using FISTA on a high-end Intel® CoreTM i7 processor, we find Loihi solves the problems up to 10,000 times faster with up to a million times lower energy[1]. For these trials, we made sure that both Loihi and the CPU/FISTA solved the problems to precisely the same quality level. The CPU, with its use of floating point arithmetic, can continue computing even longer to find a better quality solution than Loihi can. Nevertheless, Loihi’s solutions are typically within 1 percent of the optimum, which is perfectly adequate for many applications, including AI applications.
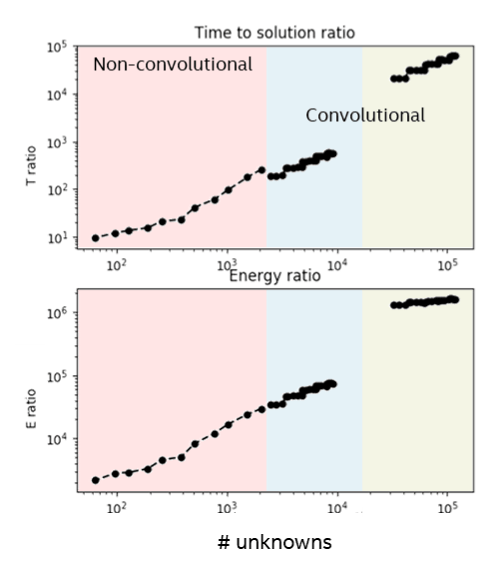
Figure 2. Time and Energy to solution ratios between over a range of Lasso problem sizes from 60 to 120,000 unknowns. The larger problems are convolutional image de-noising examples for which the conventional SPAMS solver is not optimized. Nevertheless, the general scaling trend from small to large problems is clear, with Loihi providing orders of magnitude improvement in performance and energy efficiency.
How can this be? There are several reasons. Partly, this is because Loihi’s integrated compute-in-memory architecture vastly reduces the cost of traversing distant memory hierarchies and thrashing caches. Another advantage comes from Loihi’s fine-grain parallelism. But a significant factor comes from its use of spikes. With spikes, Loihi can prioritize which neurons to update according to the timing of each neuron’s firing. Features that more strongly match the input image spike earlier than those that match less strongly. The recurrent “lateral inhibition” connections in this network cause the earlier spiking neurons to suppress the firing of other neurons, which means the other neurons never spike. The neurons that “lose” the competition never cause any computation, thereby saving both time and energy.
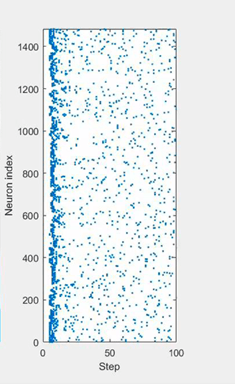
Figure 3. Spike raster plot for Spiking LCA as it solves an image de-noising problem.
The plot of neural spiking activity in Loihi is shown in Figure 3, in what we call the spike raster plot. The Y axis ranges over the particular feature neurons that are activated by the input, and the dots on the X axis correspond to spikes that the feature neurons produce over time. The solution, per dictionary feature, is measured as the final average firing rate of each feature neuron.
The first key observation is that nearly all of the computation occurs in an intense but brief burst of activity over the very earliest timesteps. This is when the feature neurons are competing to represent the input image. The Lasso objective value precipitously drops during this period from spike to spike – far faster than it does for FISTA over its iterations.
The second key observation is that Figure 3 only shows the ~2% of feature neurons in the LCA network that spike at least once. The other 98% never spike at all. Loihi so efficiently computes the solution of this network because it rapidly and asynchronously identifies each active neuron while skipping the inactive ones. It thereby naturally exploits the network’s spatial and temporal sparse activity. Conventional Von Neumann and matrix accelerator architectures, with their wide synchronous datapaths operating on continuous activity values, must iteratively update all of the network’s state variables. Without spikes, they can’t prioritize more active neurons over less active neurons.
The way to think about the spiking LCA network is that it’s a dynamical system that begins out of equilibrium. The flurry of competitive spiking rapidly moves the system to its equilibrium point, which corresponds to a steady, pseudo-random spiking pattern across the feature neurons, with the average rate of firing corresponding to each neuron’s solution value. Although the solution is read out over many timesteps as a steady-state spike rate, the actual computation happens over a brief window of time in which each individual spike time conveys great computational significance.
These results will get even more exciting once we implement LCA on Loihi. Currently, the dictionary of features that the LCA algorithm uses is constant and must be trained offline before being programmed into Loihi. Researchers at Harvard, Los Alamos, and Intel are working on implementing unsupervised spike-based learning algorithms for LCA that will allow Loihi to learn its dictionary from data with a modest extra cost in performance and power compared to its inference operation.
Conclusion
Counter to intuition, computing with spikes can be extremely efficient on neuromorphic hardware even when the problem being solved is mathematically formulated in terms of activity rates. The problem used as an example here, Lasso, may seem quite specialized, but many features of the LCA solution – lateral inhibition, balanced excitation and inhibition, and projection to higher dimensionality – are pervasive in the brain. This suggests that the gains we’ve measured could transfer to many other neural networks with similar properties, greatly accelerating a wide range of brain-inspired AI applications.
In the next blog in the series, we’ll investigate how spiking neural networks are well suited for real-time processing of temporal data. Stay tuned for part three, and, as always, follow us on @IntelAI and @IntelAIResearch for the latest news and information from the Intel AI team.
[1] CPU System: Intel Core i7-4790 3.6GHz, 32GB RAM. BIOS: AMI F5. OS: Ubuntu 16.04 with HyperThreading disabled, running FISTA from the SPAMS optimization toolbox (http://spams-devel.gforge.inria.fr/) Loihi System: Wolf Mountain running NxSDK 0.7.5. Performance results are based on testing as of December 2018 and may not reflect all publicly available security updates. No product can be absolutely secure.
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Test configurations:
CPU System: Intel Core i7-4790 3.6GHz, 32GB RAM. BIOS: AMI F5. OS: Ubuntu 16.04 with HyperThreading disabled, running FISTA from the SPAMS optimization toolbox (http://spams-devel.gforge.inria.fr/) Loihi System: Wolf Mountain running NxSDK 0.7.5.
Performance results are based on testing as of December 2018 and may not reflect all publicly available security updates. No product can be absolutely secure.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No product or component can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com.
Mike Davies
Director, Neuromorphic Computing Lab, Intel