This blog post was originally published at Intel's website. It is reprinted here with the permission of Intel.
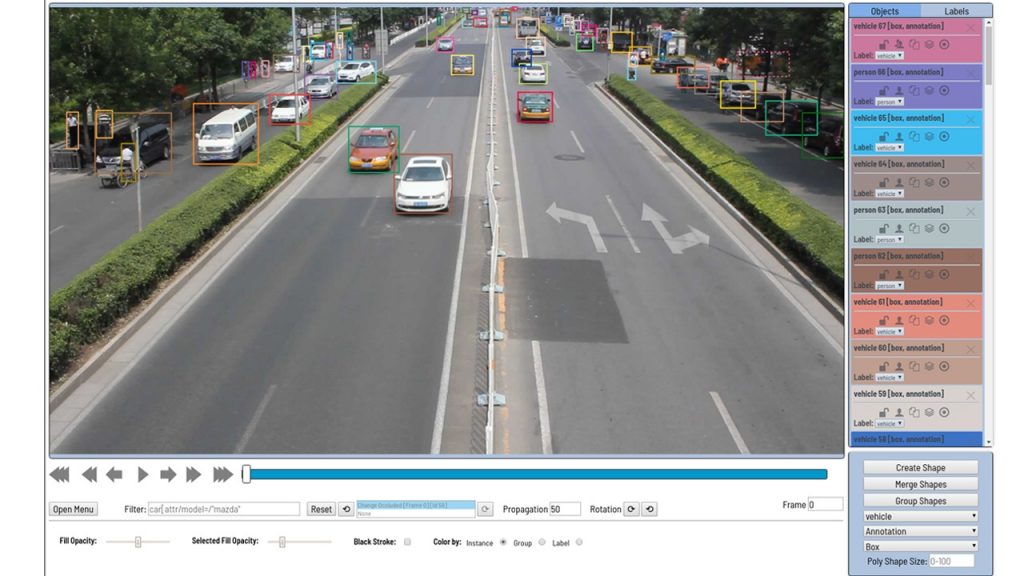
We began the Computer Vision Annotation Tool (CVAT) project a few years ago in order to speed up the annotation of digital images and videos for use in training computer vision algorithms. When we started, we didn’t have a unified approach to image annotation. Annotation tasks were done using our own set of tools, mainly written in C++ with the OpenCV library. These tools were installed on end-users’ local machines, and came with some obvious drawbacks: complex deployment in unconstrained environments, a difficult update process across many machines, difficult debugging and root-causing of bugs, limited collaboration abilities, etc.
History and Evolution
At the end of 2016, we started using VATIC (Video Annotation Tool from Irvine, California) for image annotation. This could be considered the beginning of the history of CVAT.
The VATIC tool was based on open-source code and a client-server application architecture, and introduced some great ideas, such as interpolation between key frames in video. However, it provided limited functionality for annotation, and we had to refine it a great deal. We implemented the image annotating functionality during the first half of 2017, as well as support for user-assigned object attributes, and a web page of existing tasks with the ability to add new ones through the web interface.
During the latter half of 2017, we implemented the TensorFlow Object Detection API as a method of obtaining pre-annotation of images. This involved many minor bug fixes on the client side, but negatively impacted performance. As the size of the tasks grew, the time required to open them increased in direct proportion to the number of frames and pre-annotation data. Also, the user interface (UI) response was slow due to inaccurate representation of annotated objects. The progress often caused us to lose hours of work. Basically, performance was reduced in image annotation tasks because the architecture was designed to work with video, not images. To solve this, we had to completely change the client architecture. We succeeded, and, at that time, most of the performance problems were fixed. The web interface became much faster and more stable, and there was an opportunity to annotate more tasks. During the same period, we attempted to implement unit testing and automatic checking of new changes, which was not fully completed. We set up QUnit, Karma, and Headless Chrome in the Docker container, wrote some tests, and ran it all in continuous integration. However, a huge part of the code still remained untested. Another improvement was a system of logging user actions with search and visualization based on the ELK Stack. This allowed us to inspect the annotation process and look for action scenarios that lead to program exceptions.
In the first half of 2018, we expanded our client functionality. We added an Attribute Annotation Mode that can effectively annotate attributes. We got the idea from our colleagues, and generalized it. Now you can filter objects by a variety of attributes, connect a shared repository for data upload when creating tasks, view the repository through a browser, and so on. Tasks once again became larger, and the problems with performance re-emerged.
At that time, a weak point was the tool’s server-side code. VATIC had a lot of hand-written code for tasks that could be easily solved using ready-made solutions, so we decided to use Django as a server framework because of its usability and its many out-of-the-box features. After modifying the server code, nothing remained of the VATIC tool, so we decided to share our work with the community and go open source.
Getting permission to go open source can be quite a difficult process in a large company. There was a large list of requirements. In particular, it was necessary to come up with a name. We outlined a few possible variants and interviewed our colleagues. As a result, our internal tool was named the Computer Vision Annotation Tool (CVAT), and on June 29, 2018 we published the initial version of our code (0.1.0) on GitHub in the OpenCV organization.
Further development took place in the public repository, and version 0.2.0 was released at the end of September 2018. There were a few bug fixes and changes included, but the main goal of this release was to add new annotation shapes: polygons, points, and a set of controls for annotation and validation of segmentation tasks. Now you can try all of these things in our tool.
Version 0.3.0 was released on December 29, 2018. One of the main additions to this version was the option to integrate the Deep Learning Deployment Toolkit as an element of the Intel® Distribution of OpenVINO™ Toolkit. Doing so can speed up the launch of the TensorFlow Object Detection API without a video card. Additionally, we added an analytics component to manage a data annotation team, monitor exceptions, and collect client and server logs. You can find more information about the history of CVAT changes in the GitHub changelog, and stay tuned to Intel.ai for the latest updates on our computer vision tool.
Boris Sekachev
Deep Learning Software Developer, Internet of Things Group, Intel
Nikita Manovich
Deep Learning Manager, Internet of Things Group, Intel
Andrey Zhavoronkov
Deep Learning Software Engineer, Intel