This blog post was originally published at NVIDIA's website. It is reprinted here with the permission of NVIDIA.
Quality requirements for manufacturers are increasing to meet customer demands. Manual inspection is usually required to guarantee product quality, but this requires significant cost and can result in production bottlenecks, lowered productivity, and reduced efficiency.
Defect inspection for industrial applications has unique characteristics and challenges compared to other computer vision problems for consumer applications:
- Lack of labeled, annotated, and curated data
- Defects of interests are structures with low contrast
- Multi-scale defect sizes
- Highly asymmetric datasets with very low true defects.
The U-Net approach detailed in this blog avoids labor-intensive and potentially fragile feature engineering and instead allows data‑driven models to automatically learn robust feature representations to generate state-of-the-art detection and segmentation results.
The Problems with Traditional Quality Inspection
With increasing global competition, manufacturers are seeking to develop smart factory strategies that utilize advanced information technology (IT) and operational technology (OT) to facilitate and automate their manufacturing processes. To achieve this goal, manufacturing systems are often required to automatically see and understand the world.
Optical quality inspection remains one of the common methods to ensure quality control for high-precision manufacturing. However, this step remains a bottleneck to full automation and integration. The quality checks may include a series of manual operations — including visual confirmation to make sure components are the right color, shape, texture, and position — which are very challenging due to wide product variations. Quality inspectors must constantly adapt to different quality requirements for different products, which often leads to inaccuracy and a lack of consistent quality. With ever increasing production volumes, quality inspectors often suffer from eye fatigue and other health issues caused by repetitive product inspection over long hours, allowing more defective parts to pass, failing parts that should be passed. Human inspection is constrained by increasing cost, training time, and limited resources, making it a challenging solution to scale. Automating defect inspection with AI is beginning to revolutionize manufacturing.
Traditional computer vision methods that are typically used in production automated optical inspection (AOI) machines require intensive human and capital involvement.
Defects can be visually distinctive or subtle. This makes it very challenging to robustly detect all defects in various environments such as lighting conditions, surface textures.
Common type of industrial defects are local anomalies on homogeneous surfaces. Prior approaches to automate the detection and classification of these anomalies can be divided into four categories:
- Structural based on-defect morphology
- Statistical texture measure-based
- Hand-crafted transform filter-based
- Machine learning model-based
Most of these traditional approaches were designed with hand-crafted features, making them application dependent and not able to generalize or scale out to new applications. These traditional approaches also typically suffered from poor flexibility and often required expensive and time-consuming manual feature engineering by domain experts. In a production case at NVIDIA, a traditional AOI machine in PCBA manufacturing produced high false positives (failing PCBs) with low precision. For industrial applications, the cost of false positives and low precision can be extremely high. The tradeoff between low false positives and high precision makes traditional CV algorithm very challenging, thus ending with high false positives. Deep learning automatically finds the best decision boundary to strike a balance between false positives and precision, which can be of tremendous value.
How Deep Learning Addresses These Problems
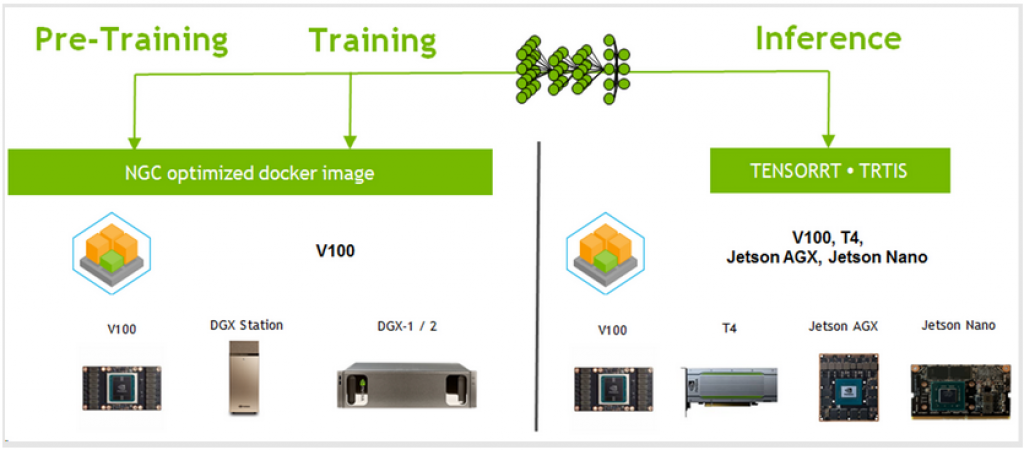
Deep learning, especially CNNs have proven to be very effective for image detection and classification, and are now being adopted to solve industrial inspection tasks. The NVIDIA DL platform, in Figure 1,has been successfully applied to detection and segment defects in an end-to-end fashion for fast development of automatic industrial inspection. All processes are built on top of NGC optimized docker images for fast iterations.

Figure 1: NVIDIA Deep Learning Platform
One popular and effective neural network architecture — originally proposed for biomedical image segmentation — is the U-Net architecture, which is composed of encoders, decoders and skip-connection layers. Particularly, the U-Net architecture and the DAGM 2007 dataset (Figure 2) was used for this demonstration. To deal with scarcity of true defect data, all six defect classes of DAGM dataset are unified and treated as a single class. This combined training set is used to demonstrate the generalization capability of U-Net. We built a single U-Net model that is able to segment all defect classes. This kind of process is common in defect inspection in real production. To prevent overfitting on a small DAGM dataset, we use the same architecture as U-Net, and experiment with the number of kernels to make the model fit into our dataset.
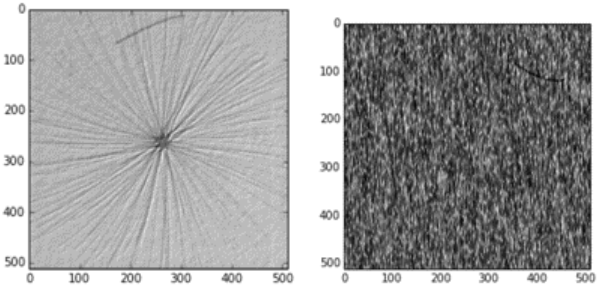
Figure 2: Examples of industrial manufacturing defects from the DAGM dataset.
The first step was to fit the dataset with U-Net model, i.e., eight kernel numbers in the first layer, then doubling the kernel number in the following hierarchy of layers. Then we observed the loss from the training learning curve and decided whether to increase further the model complexity. This step was to make sure that we had a model with enough capacity to recognize all defects. Once we gained the you confidence that the model was complex enough to fit the dataset, we then added regularization techniques, such as drop out layers, L1 or L2 regularization, or even attempting to augment the dataset. The modified U-Net was trained with binary cross entropy and Adam optimizer with a learning rate starting with 1e-3. In cases where there was a shortage of labeled data and fast performance was needed, we showed U-Net was successful at generalizing performance with regularization techniques and is a suitable model for defect segmentation for industrial inspection.
In a segmentation model, like U-Net, the output is a set of probabilities. By thresholding these probabilities for each pixel, defect class is assigned for each pixel and precision and recall for the dataset is determined. Determining the right threshold to bias towards precision or recall is entirely application dependent. In production cases, defects are much smaller, typically in the tens to hundreds of defect parts per million (DPPM) range. In this very skewed dataset, the precision-recall value is highly sensitive to the threshold value. This requires sweep experiments of precision and recall on the threshold of probability. If reducing false positives (increasing precision) is more important, the threshold on probability should be increased while balancing precision-recall tradeoff. The learned internal representations by U-net, allow decision boundaries to be defined that have been shown to drastically reduce the tradeoff between increasing sensitivity to true positives while significantly reducing the rate of false positives.
For industrial applications where the cost of false positives can be extremely high, this can be a source of tremendous value. Having a domain-expert tunable threshold value is also desirable to industrial inspection, leading to interpretable AI and avoiding mere input-output black-box relationship from DL. This two-step process with tunable thresholding after DL can be applied to many use cases, including medical imaging, video surveillance, and autonomous machines. The first step uses U-Net to extract information from the input, then the second step makes the final decision according to information from the previous step.
To ensure fast deployment of DL training and inferencing, NGC was used for Volta and Turing GPU optimized TensorFlow (TF) and TensorRT (TRT) docker containers, and for edge-based solutions Jetson AGX Xavier and Nano. Application software engineers or advanced users who are comfortable with the additional steps required to take a DL model into an environment which might not have TensorFlow framework, are encouraged to use native TRT for maximum performance. We used TensorRT NGC container for our experiments. Data scientists or users for rapid prototyping should run optimized accelerated inference without leaving TF framework. We use TF‑TRT inferencing based on TRT-integrated TensorFlow NGC container. The tradeoff for TF-TRT versus TRT is that TF-TRT is easy to use and integrates with TensorFlow workflows for fast prototyping. Once an idea is verified to work with TF-TRT, TRT can be used for maximum performance.
Summary
U-Net was utilized to build an end-to-end generic defect inspection model on a public dataset, using the NVIDIA DL platform for end-to-end training and inference. A recall rate of 96.38% and a 99.25% precision rate with a 0.11% false-alarm rate were achieved. On V100 GPUs and TensorRT 4, from a TensorFlow container with the NVIDIA TensorRT engine integrated, inference throughput increased by a factor of 2.1. With an optimized TRT container using the NGC, inference throughput was further improved by a factor of 8.6 compared to native TF. For energy efficient and small form factor inference deployment, T4 GPUs and TensorRT 5 was used. Compared to CPU-based inference performance, there is a performance boost of 11.9 times with TF-TRT and 23.5 times with INT8 precision of TRT5 by NVIDIA Turing Tensor Cores. The T4 GPU is packaged with an energy-efficient 70-watt, small PCIe form factor, optimized for scale-out servers and purpose built to deliver state-of-the-art AI.
For edge-based, embedded, and remote offline applications we took the same code and targeted the NVIDIA Jetson family of embedded GPUs. Jetson Nano platform throughput is 18 FPS and Jetson AGX Xavier platform throughput is 228.1 FPS — a performance boost of 12.7 times that of the Jetson Nano platform. These results were obtained using native TRT. With native TRT, a DL framework like Tensorflow does not need to be installed on edge devices. This is important for them since system power, system size, compute power and disk storage are limited. Furthermore, with automatic mixed precision (AMP), DNN graph optimization on FP16 and FP32 on Tensor Cores on Volta and Turing GPUs is fully automatic, easy to use, with great performance. With AMP, U-net performance was further boosted by 17% for training and 30% for testing.
For more detailed information, read the related white paper “Automatic Defect Inspection Using the NVIDIA End-to-End Deep Learning Platform“.
Dr. Peter K Pyun
Principal Solution Architect, NVIDIA
Andrew Liu
Senior Solution Architect, NVIDIA
Charles Cheung
Deep Learning Solution Architect, NVIDIA
Barrie Mullins
Director of Technical Product Marketing for Jetson, NVIDIA
Robert Sohigian
Technical Marketing Engineer, Enterprise Products Group, NVIDIA