
This blog post was originally published at Xailient’s website. It is reprinted here with the permission of Xailient.
In this post, we will look at the best methods for collecting a training dataset to train a custom detection model.
Use of deep learning in computer vision has increased in the last decade. In the past couple of years, computer vision applications such as face detection and vehicle detection have become mainstream. One of the reasons is the availability of pre-trained models.
Convinced by the success of deep learning on these applications, businesses have now started to solve their own problems using deep learning.
But what if the available pre-trained models are not suitable for your application?
A pre-trained model may be able to detect eggs, but it will definitely not differentiate between good and bad eggs because it has never been taught to do so.
So what do you do? Get lots of images of good and bad eggs and train a custom detection model.
A common challenge in creating a good custom computer vision model is training data. Deep learning models require a huge amount of data to train their algorithm – as we can see with benchmark models such as MaskRCNN, YOLO, and MobileNet, which were trained on existing large datasets COCO and ImageNet.
How Do You Get Data for Training a Custom Detection Model?
In this post, we will look at five ways of collecting data for training your custom model and solving your problems.
1. Publicly Available Open Labeled Datasets
If you are lucky, you might just get a labeled dataset you want online. Here is a list of free image datasets for computer vision that you can choose from.
ImageNet: The ImageNet dataset consists of around 14 million images in total, for 21,841 different categories of objects (data as of 12th Feb 2020). Some of the popular categories of objects in ImageNet are Animal (fish, bird, mammal, invertebrate), Plant (tree, flower, vegetable) and Activity (sport).

Example of images in ImageNet dataset
Common Objects in Context (COCO): COCO is a large-scale object detection, segmentation, and captioning dataset. It contains around 330,000 images, out of which 200,000 are labeled for 80 different object categories.

Images from the COCO dataset
Google’s Open Images: Open Images is a dataset of around 9M images annotated with image-level labels, object bounding boxes, object segmentation masks, and visual relationships. It contains a total of 16M bounding boxes for 600 object classes on 1.9M images, making it the largest existing dataset with object location annotations.
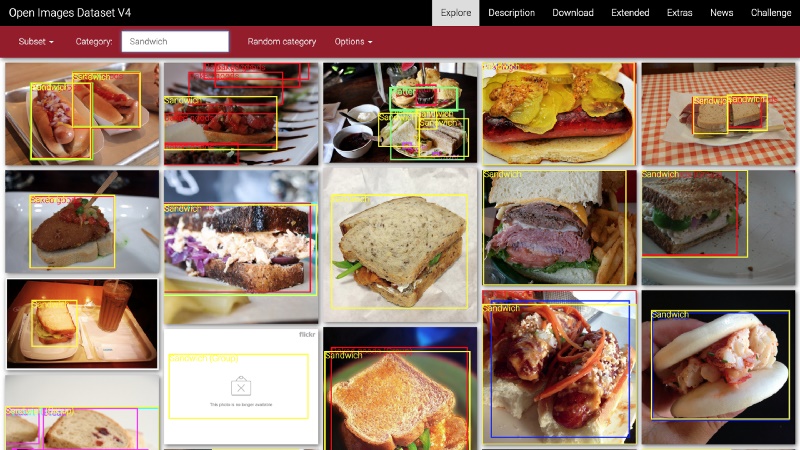
Examples of images from the Open Images Dataset
MNIST Handwritten Datasets: This dataset has a total of 70,000 images of handwritten digits and is a subset of a larger set available from NIST. The digits have been size-normalized and centered in a fixed-size image.

Example of images from the MNIST dataset
Cityscapes Dataset:This dataset focuses on semantic understanding of urban street scenes. It contains around 20,000 annotated images for 30 different classes.

Cityscapes Dataset
NOTE: These are just a few that I found, and there are a lot of other datasets you can find online. Also, make sure you check the license of these datasets before using them.
2. Scraping the Web
Another option is to do an image search on the web, and hand-pick images to download manually. As a large volume of data is required, this method is not efficient.
NOTE: The images on the web may be subject to copyright. Always remember to check the copyright of the images before using them.
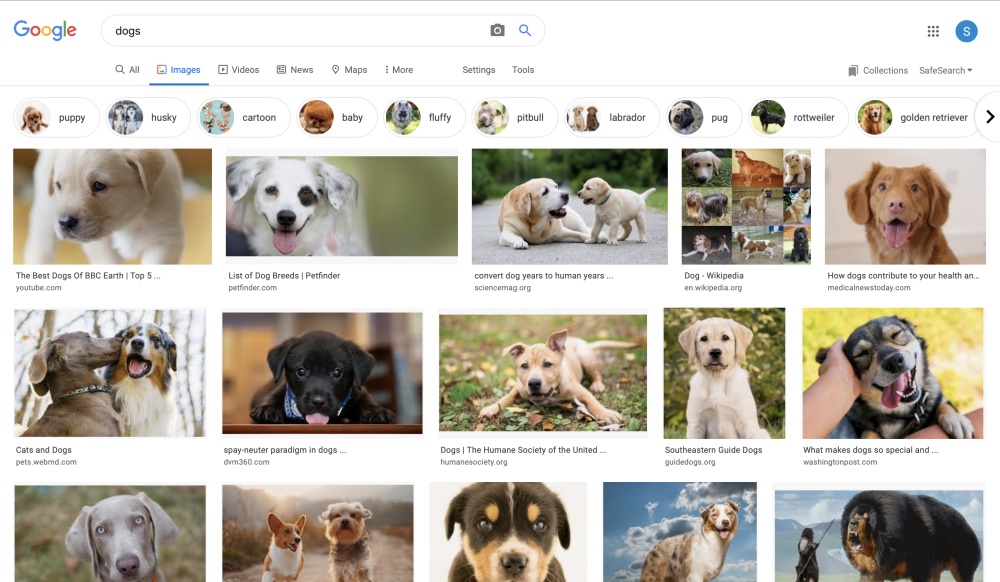
Example of an image search in Google Images
An alternative to this is to write a program to scrape the web and download the images that you want. One such program is Download All Images – a Google Chrome extension that allows you to download a bunch of images at once. In this blog post, Arun Ponnusamy explains how you can use Download All Images to download images of people wearing a helmet.
NOTE: The copyright usage rights of images may not allow for using bulk-downloaded images. Always check the copyright of each image before using them.
Taking Photographs
If you cannot find images of the object you want, you can collect them by taking photographs. This can be done manually, that is by taking each image yourself or by crowdsourcing – hiring other people to take photographs for you. Another way to collect real-world images is to install a programmed camera in your environment.

Photo by Miss Zhang on Unsplash
4. Data Augmentation
We know that deep learning models require a large amount of data. When you only have a small dataset, it may not be enough to train a good model. In such cases, you can use data augmentation to generate more training data.
Geometric transformations such as flipping, cropping, rotation, and translation are some commonly used data augmentation techniques. Applying image data augmentation not only expands your dataset by creating variation but also reduces overfitting.

Original image of a dog on the left, horizontally flipped image about center on the right
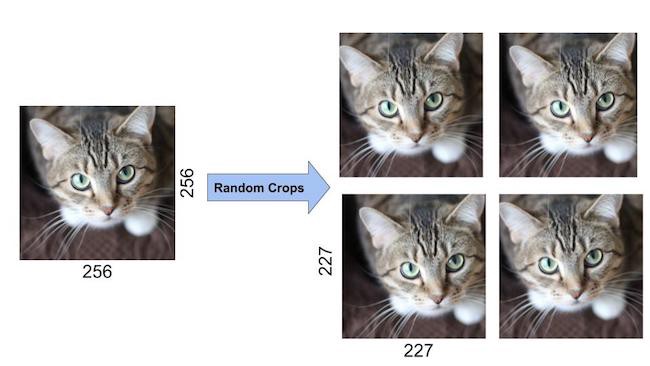
Original and randomly cropped images of a cat

Original and rotated images of a cat

Original and translated images of a tennis ball
5. Data Generation
Sometimes, real data may not be available. In such cases, synthetic data can be generated to train your custom detection model. Due to its low cost, the use of synthetic data generation has been increasing in machine learning.
Generative Adversarial Networks (GANs) is one of many techniques which is used for synthetic data generation. GAN is a generative modeling technique, where artificial instances are created from a dataset in such a way that similar characteristics of the original set are retained.

Modern art generated by GAN
Summary
Collecting a training dataset is the first step towards training your own custom detector model. In this post, we looked at some of the techniques used for collecting image data, which include searching through public open labeled datasets, scraping the web, taking photographs manually, or using a program, using data augmentation techniques, and generating synthetic datasets.
In the next post, we will look at the next step in training your custom detector, that is, labeling your dataset.
Sabina Pokhrel
Customer Success AI Engineer, Xailient