This blog post was originally published at Expedera’s website. It is reprinted here with the permission of Expedera.
Choosing the right inference NPU (Neural Processing Unit) is a critical decision for a chip architect. There’s a lot at stake because the AI landscape constantly changes, and the choices will impact overall product cost, performance, and long-term viability. There are myriad options regarding system architecture and IP suppliers. It can be daunting for even the most seasoned semiconductor veteran. After working with many customers, we’ve identified specific items a chip architect will want to consider when choosing an NPU.
Chip designers need to consider factors like the type of workload, including the architecture of the neural network and the algorithms, the size of the dataset, memory and bandwidth requirements, power consumption, performance, cost, and application-specific or market needs, such as battery life and environmental requirements. Often the deciding factor for choosing an accelerator for edge AI is whether it can meet very tight power and area requirements.
OEMs will often have unique concerns and may need a customizable solution. However, first let’s touch on some of the most common questions, including general purpose versus optimized architectures, network support, scalability, futureproofing, and market acceptance.
General Purpose vs. Application-configured Deployments
Early AI deployments most often involved general-purpose GPUs or NPUs. Those were designed without a focus on optimization for specific neural networks or network types. Which was fine for the time – the science of AI had not progressed to where custom or proprietary networks had made appearances. This is changing, and more on that later…
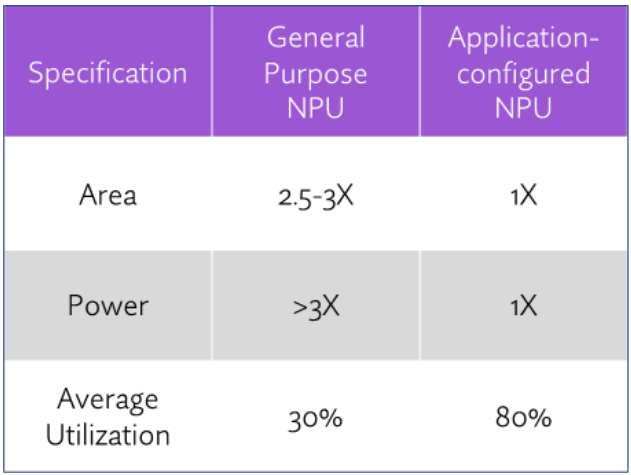
General purpose NPUs are good because while they aren’t tuned to support particular use cases, their wide-ranging network support enables the NPU to run many network types and models. OEMs can use a general-purpose NPU with the confidence that it’ll support different implementations—but not necessarily optimized support.
With the rapid evolution of AI have come more specialized NPUs that can better match OEM use cases. Suppliers like Expedera provide a custom-configured NPU that is optimized to deliver the best possible performance within the required power and area envelope for an OEM’s use cases. The downside with optimization, however, is that too much specialization could mean limited support for networks and use cases not captured in the initial design, or in the worst case simply not support them.
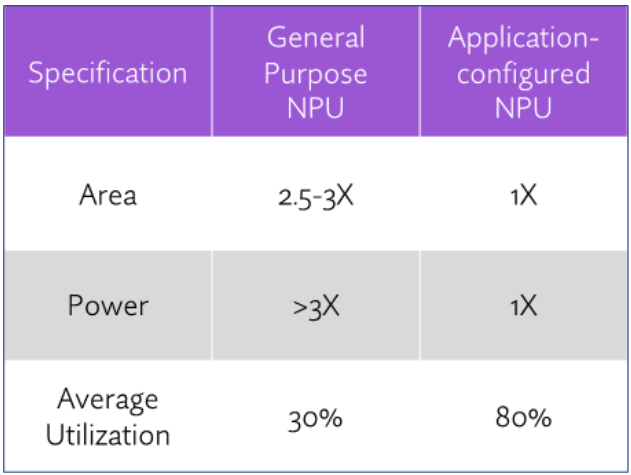
Not all NPU architectures can be application-configured and even if they can, the degree to which a supplier can fine-tune their NPU will vary extensively. Some can slightly optimize, while others, including Expedera, can modify almost every architectural building block. Chip architects will understand the needs of their device including its PPA and utilization targets and should explore to what degree the NPU supplier can adapt a solution to their needs.
Network Match
Early AI deployments primarily used general-purpose public models. But as AI has evolved, so has the ability of OEMs to build customized models specific to their use case(s). These custom models may be based on public models, but more often are private or fully proprietary models. Customized models allow the OEMs to offer better performance and, thus a better user experience. However, with custom models comes the uncertainty of support. Further, custom models are often treated as ‘state secrets’ by the OEM, and so the chip architect needs to understand how flexible the NPU supplier (and their toolsets) are regarding ‘black box’ deployments. Can a general-purpose NPU support and run the model(s) efficiently? Or is application-configured the better approach?
Another consideration: does the NPU need to support multiple concurrent models? Long gone are the days of an NPU running just a single model; OEMs now require that NPUs efficiently run multiple models and often run them concurrently. Chip architects need to balance their model needs against the capabilities of the NPU and be sure that if they require concurrent model support, the NPU can do so in a deterministic, power- and memory-friendly manner.
Future-Proofing
No one can predict the future, but often chip architects are asked to do so. AI is evolving so fast that the networks and use cases envisioned for a chip architect’s product today will likely change over the product’s lifetime, and maybe even during the development of the product. Consequently, the chip architect needs to think about what degree of future-proofing will be needed in the product. Can a chosen NPU handle new networks? How does it do that? What if a network isn’t supported; can the NPU hand off layers or complete networks to a local CPU or GPU instead? Chip architects must also balance this with a hard look at their product—how long will it be in the market? How quickly are the target markets changing? What is their company’s appetite for new network support?
Scalability
Your new chip design won’t be your last one to have an NPU. When a company chooses a computing architecture, whether a CPU, NPU, GPU, etc., they’re investing in learning the ins and outs of that architecture, from design to software. Switching architectures is not cheap, so most OEMs consider processing architectures not on a single design basis but with the long term in mind. Therefore, chip architects need to consider the scalability of an NPU architecture to determine fitness for future products.
For example, if the current design target is 10 TOPS, but the next generation is 25 TOPS, does the architecture even support 25 TOPS? If so, will a single engine suffice, or will the NPU need multiple cores or tiles to support increasing performance? If additional cores or tiles are required, how does the NPU architecture address memory sharing, power consumption, bandwidth, latency, and determinism, which are inherent concerns in multi-core architectures? Furthermore, can the same software used for the current 10 TOPS system be used with 25 TOPS system? Finally,—and this is a very important question—when you scale up, how do power, performance, area (PPA) and utilization change? Unfortunately, performance often does not scale in a linear fashion with area and power. Like all processors, NPUs have sweet spots of performance, and moving outside of those bounds can drastically affect PPA and utilization. Chip architects need to anticipate this and consider the ramifications.
Market Acceptance
The AI world is noisy and every NPU supplier, including Expedera, makes bold claims about their performance (Some even back up those claims with 3rd party data and transparency about how performance numbers are calculated.). Every NPU supplier claims to have market-leading performance, or the smallest NPU, or the most power-friendly design.
Perhaps the hardest part about choosing the right NPU is cutting through this noise. Chip architects need to bypass the hype—if an NPU maker does not (or cannot) provide silicon-based performance data, that should be telling. The proof is in the pudding—NPU suppliers should be able to provide specific, cycle-accurate PPA estimations. Even better, they should be able to say how many devices have shipped with their products, even if they are unable to share the names of customers per non-disclosure agreements.
Wrapping Up
While choosing the right NPU is not for the faint of heart, there are excellent solutions available and buying an NPU is almost always a faster, better, cheaper, and less risky approach than rolling your own.
Expedera offers chip designers an expertly design field-proven NPU solution with unique advantages including:
- NPUs that can be application-customized to any degree to suit OEM PPA and utilization targets with no time-to-market risk
- Support for standard and custom models with out-of-the-box tools capable of black-box integration
- Future-proofed with layer and network offload capabilities as necessary
- 3 GOPS to 128 TOPS in a single-engine architecture
- More than 10 million devices shipped worldwide