
LETTER FROM THE EDITOR |
 |
|
Dear Colleague, Vision-language models are becoming widely used. How can engineers familiar with classical AI and vision techniques learn to leverage these new models in real world applications? We have two pieces today focused on getting started with VLMs, one focused on running them on the Jetson hardware family, and the other addressing VLM prompt engineering techniques. We’ll also look at two views of where ADAS compute is headed—hardware and architectures being built for tomorrow’s transformer/VLM-class workloads, even if most production stacks today are still using “classic” perception models. But first… If you’re an engineer, developer or engineering manager eager to take advantage of VLM technology, join us for two intensive three-hour training sessions taking place in Santa Clara, California on May 13, the final day of the 2026 Embedded Vision Summit. “Vision-Language Models for Computer Vision Applications: A Hands-On Introduction” will introduce VLM techniques and their integration with traditional computer vision methods. This course is tailored for professionals looking for the tools and knowledge to implement sophisticated AI solutions in your projects. “Vision-Language Models for Video Understanding and Agentic AI” is an advanced course, focused on reasoning approaches, model selection, grounding and other advanced topics. This course is tailored for engineers who want to build the next generation of video understanding applications, safety systems and agent-like multimodal products. Both courses will be led by Satya Mallick, CEO of OpenCV.org and founder of Big Vision LLC, and Phil Lapsley, Vice President of BDTI and the Edge AI and Vision Alliance. See here to learn more and register. And while you’re there, don’t forget to register for the Embedded Vision Summit main program, too! We look forward to seeing you there! Finally — we still have some space in our free webinar, “Why your Next AI Accelerator Should Be an FPGA,” coming up March 17th, and I hope you’ll join us. Without further ado, let’s get to the content. Erik Peters
|
BUILDING AND DEPLOYING REAL-WORLD ROBOTS |
GETTING STARTED WITH VLMS |
 |
|
Getting Started with Edge AI on NVIDIA Jetson: LLMs, VLMs, and Foundation Models for Robotics This primer walks developers through running today’s open-source LLMs, vision-language models (VLMs), and robotics foundation models directly on NVIDIA Jetson—so robots and smart cameras can “see, understand, and react” with low latency and without sending sensitive prompts or video off-device. It’s organized as two practical tutorials. Tutorial 1 shows how to stand up a local personal assistant: launch vLLM on Jetson (example Docker commands included), pair it with Open WebUI, and then add multimodal perception with VLMs such as VILA or Qwen2.5-VL via the Live VLM WebUI (Ollama/vLLM compatible) for real-time camera analysis. The article also maps realistic model-size ranges to Jetson tiers (Orin Nano, AGX Orin, AGX Thor) and points to extensions like NVIDIA’s Vision Search and Summarization for video retrieval. Tutorial 2 shifts to robotics: vision-language-action policies (e.g., Isaac GR00T) trained through imitation learning in Isaac Sim, validated with hardware-in-the-loop, and deployed with TensorRT for sub-30 ms control loops. |
 |
|
Unlocking Visual Intelligence: Advanced Prompt Engineering for Vision-language Models Imagine a world where AI systems automatically detect thefts in grocery stores, ensure construction site safety and identify patient falls in hospitals. This is no longer science fiction, as companies today are building powerful applications that integrate visual content with textual data to understand context and act intelligently. In this talk, Alina Li Zhang, Senior Data Scientist and Tech Writer at LinkedIn Learning, delves into vision-language models (VLMs), the core technology behind these intelligent applications, and introduces the Pentagram framework, a structured approach to prompt engineering that significantly improves VLM accuracy and effectiveness. Zhang shows, step-by-step, how to use this prompt engineering process to create an application that uses a VLM to detect suspicious behaviors such as item concealment in grocery stores. She also explores the broader applications of these techniques in a variety of real-world scenarios. You’ll discover the possibilities of vision-language models and learn how to unlock their full potential. |
AUTONOMOUS VEHICLE COMPUTE |
 |
|
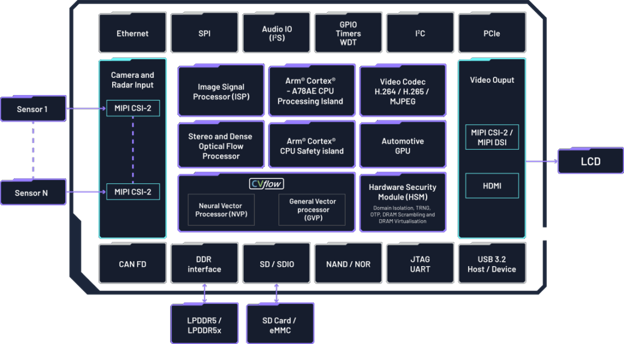
Ambarella’s CV3-AD655 Surround View with IMG BXM GPU: A Case Study A case study of Ambarella’s CV3-AD655 shows how next-generation ADAS is driving a shift from many small vehicle controllers to centralized AI “domain controllers” that consolidate perception, sensor fusion, and planning while controlling cost and power. The CV3-AD655 targets mass-market L2++/L3 features such as enhanced autopilot and automated parking, and pairs Ambarella’s efficient compute engines with an Imagination IMG BXM GPU to power real-time surround-view and bird’s-eye visualization. Beyond convenience, high-quality 360° visualization helps prevent low-speed accidents and, at higher automation levels, makes the system’s perception and intent more transparent—an important ingredient for driver awareness and trust. The discussion highlights why GPU IP matters in this class of SoC: efficient graphics for stitched multi-camera views, programmable compute for image processing tasks, multitasking to handle mixed 2D/3D/compute workloads, and safety-oriented design practices suitable for automotive requirements. |
 |
|
Why Scalable High-Performance SoCs are the Future of Autonomous Vehicles As automakers move from today’s widespread Level 1–2 driver assistance toward more capable Level 3 functions, vehicle electronics are shifting from many distributed ECUs to centralized computing platforms in software-defined vehicles (SDVs). This architecture supports over-the-air updates and feature upgrades over a vehicle’s lifetime, but it also raises the bar for onboard AI performance, real-time determinism, and functional safety. This article argues that heterogeneous, scalable SoCs—combining CPUs, high-performance NPUs, vision processing, and dedicated memory—are better suited than single-element, GPU-centric designs because workloads can be offloaded to specialized blocks for higher efficiency. Texas Instruments’ TDA5 family is used as an example: integrated C7 NPU/DSP technology targets a wide performance range intended to span entry ADAS through conditional autonomy, with headroom for transformer-based perception and even multi-billion-parameter models. Safety is emphasized via cross-domain hardware monitoring, ASIL-D oriented design and lockstep cores, alongside a “chiplet-ready” roadmap using UCIe for future modular expansion. |
UPCOMING INDUSTRY EVENTS |
|
Why your Next AI Accelerator Should Be an FPGA – Efinix Webinar: March 17, 2026, 9:00 am PT Intelligent Driver Development with LLM Context Engineering – Boston.AI Webinar: March 19, 2026, 10:00 am PT Embedded Vision Summit: May 11-13, 2026, Santa Clara, California Newsletter subscribers may use the code 26EVSUM-NL for 25% off the price of registration until March 13. |
FEATURED NEWS |
|
Vision Components has unveiled its all-in-one VC EvoCam with a MediaTek processor Andes Technology and 10xEngineers are enabling high-performance AI compilation for RISC-V AX46MPV cores e-con Systems has launched the DepthVista Helix 3D CW iToF camera for robotics and industrial automation Chips&Media is expanding its WAVE-N ecosystem of customized NPU architecture Ambarella will showcase a scalable AI SoC portfolio as well as its Developer Zone at Embedded World 2026 |