By Eric Gregori
Senior Software Engineer and Embedded Vision Specialist
BDTI
The name OpenCV has become synonymous with computer vision, but what is OpenCV? OpenCV is a collection of software algorithms put together in a library to be used by industry and academia for computer vision applications and research (Figure 1). OpenCV started at Intel in the mid 1990s as a method to demonstrate how to accelerate certain algorithms in hardware. In 2000, Intel released OpenCV to the open source community as a beta version, followed by v1.0 in 2006. In 2008, Willow Garage took over support for OpenCV and immediately released v1.1.
Figure 1: OpenCV, an algorithm library (courtesy Willow Garage)
Willow Garage dates from 2006. The company has been in the news a lot lately, subsequent to the unveiling of its PR2 robot (Figure 2). Gary Bradski began working on OpenCV when he was at Intel; as a senior scientist at Willow Garage he aggressively continues his work on the library.

Figure 2: Willow Garage's PR2 robot
OpenCV v2.0, released in 2009, contained many improvements and upgrades. Initially, OpenCV was primarily a C library. The majority of algorithms were written in C, and the primary method of using the library was via a C API. OpenCV v2.0 migrated towards C++ and a C++ API. Subsequent versions of OpenCV added Python support, along with Windows, Linux, iOS and Android OS support, transforming OpenCV (currently at v2.3) into a cross-platform tool. OpenCV v2.3 contains more than 2500 algorithms; the original OpenCV only had 500. And to assure quality, many of the algorithms provide their own unit tests.
So, what can you do with OpenCV v2.3? Think of OpenCV as a box of 2500 different food items. The chef's job is to combine the food items into a meal. OpenCV in itself is not the full meal; it contains the pieces required to make a meal. But here's the good news; OpenCV includes a bunch of recipes to provide examples of what it can do.
Experimenting with OpenCV, no programming experience necessary
BDTI has created the OpenCV Executable Demo Package, an easy-to-use tool that allows anyone with a Windows computer and a web camera to experiment with some of the algorithms in OpenCV v2.3. You can download the installer zip file here. After the download is complete, double-click on the zip file to uncompress its contents, then double-click on the setup.exe file.
The installer will place various prebuilt OpenCV applications on your computer. You can run the examples directly from your Start menu (Figure 3). Just click on:
START -> BDTi_OpenCV_Executable_Demo_Package -> The example you want to run
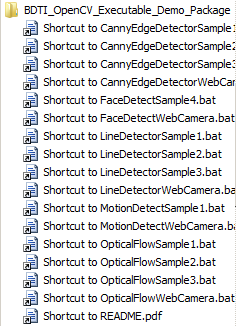
Figure 3. OpenCV examples included with the BDTI-developed tutorial tool
Examples named xxxxxxSample.bat will use a video clip as an input (example clips are provided with the installation), while examples named xxxxxWebCamera.bat will use a web camera as an input. Keep an eye on www.embedded-vision.com for additional examples in the future.
Computer vision involves classifying groups of pixels in an image or video stream as either background or a unique feature. Each of the following examples demonstrates various algorithms that separate unique features from the background using different techniques. Some of them use code derived from the book OpenCV 2 Computer Vision Application Programming Cookbook by Robert Laganiere (ISBN-10: 1849513244, ISBN-13: 978-1849513241) (Figure 4).

Figure 4: The source of the code used in some of the examples discussed in this article
Motion detection
As the name implies, motion detection uses the change of pixels between frames to classify pixels as unique features (Figure 5). The algorithm considers pixels that do not change between frames as being stationary and therefore part of the background. Motion detection or background subtraction is a very practical and easy-to-implement algorithm. In its simplest form, the algorithm looks for differences between two frames of video by subtracting one frame from the next. White pixels are moving, black pixels are stationary.
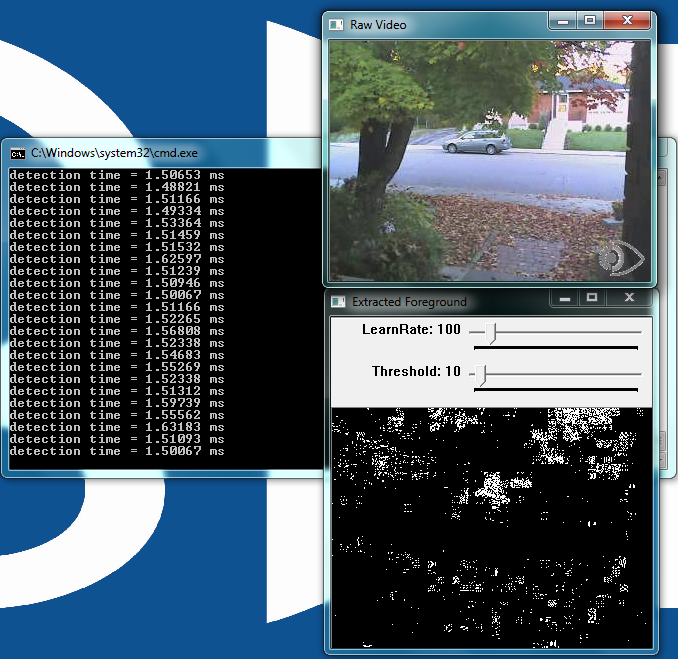
Figure 5: The user interface for the motion detection example
This example adds an additional element to the simple frame subtraction algorithm; a running average of the frames. Each frame averaging routine runs over a time period specified by the LearnRate parameter. The higher the LearnRate, the longer the running average. By setting LearnRate to 0, you disable the running average and the algorithm simply subtracts one frame from the next.
The Threshold parameter sets the level required for a pixel to be considered moving. The algorithm subtracts the current frame from the previous frame, giving a result. If the result is greater than the threshold, the algorithm displays a white pixel and considers that pixel to be moving.
LearnRate: Regulates the update speed (how fast the accumulator "forgets" about earlier images).
Threshold: The minimum value for a pixel difference to be considered moving.
Line detection
Line detection classifies straight edges in an image as features (Figure 6). The algorithm relegates to the background anything in the image that it does not recognize as a straight edge, thereby ignoring it. Edge detection is another fundamental component in computer vision.
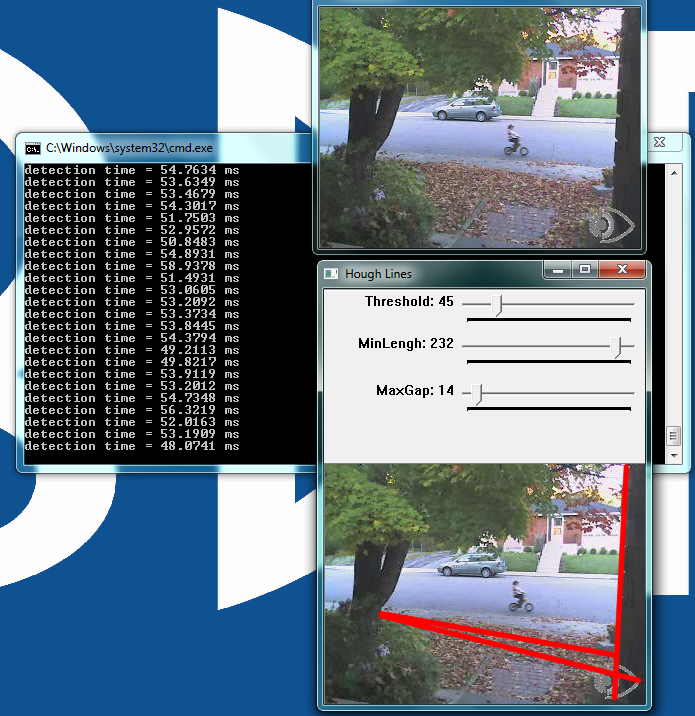
Figure 6: The user interface for the line detection example
Image processing determines an edge by sensing close-proximity pixels of differering intensity. For example, a black pixel next to a white pixel defines a hard edge. A gray pixel next to a black (or white) pixel defines a soft edge. The Threshold parameter sets a minimum limit on how hard an edge has to be in order for it to be classified as an edge. A Threshold of 255 would require a white pixel be next to a black pixel to qualify as an edge. As the Threshold value decreases, softer edges in the image appear in the display.
After the algorithm detects an edge, it must make a difficult decision; is this edge part of a straight line? The Hough transform, employed to make this decision, attempts to group pixels classified as edges into a straight line. It uses the MinLength and MaxGap parameters to decide (i.e. "classify" in computer science lingo) a group of edge pixels into either a straight continuous line or ignored background information (edge pixels not part of a continuous straight line are considered background, and therefore not a feature).
Threshold: Sets the minimum difference between adjoining groups of pixels to be classified as an edge.
MinLength: The minimum number of "continuous" edge pixels required to classify a potential feature as a straight line.
MaxGap: The maximum allowable number of missing edge pixels that still enable classification of a potential feature as a "continuous" straight line.
Optical flow
Optical flow describes how a group of pixels in the current frame change position in the next frame of a video sequence (Figure 7). The "group of pixels" is a feature. Optical flow estimation finds use in tracking features in an image, by predicting where the features will appear next. Many optical flow estimation algorithms exist; this particular example uses the Lucas-Kanade approach. The algorithm's first step involves finding "good" features to track between frames. Specifically, the algorithm is looking for groups of pixels containing corners or points.
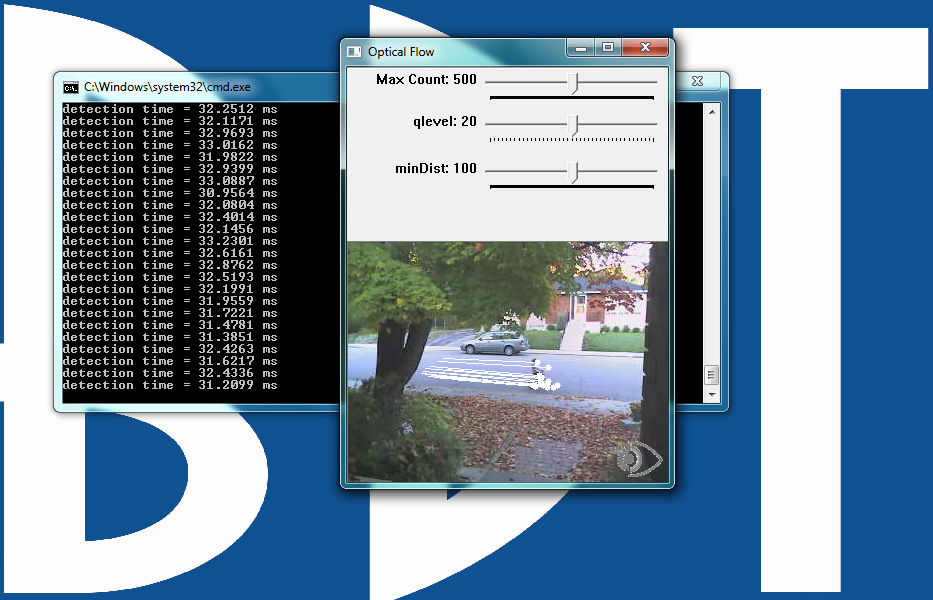
Figure 7: The user interface for the optical flow example
The qlevel variable determines the quality of a selected feature. Consistency is the end objective of using a lot of math to find quality features. A "good" feature (group of pixels surrounding a corner or point) is one that an algorithm can find under various lighting conditions, as the object moves. The goal is to find these same features in each frame. Once the same feature appears in consecutive frames, tracking an object is possible. The lines in the video represent the optical flow of the selected features.
The MaxCount parameter determines the maximum number of features to look for. The minDist parameter sets the minimum distance between features. The more features used, the more reliable the tracking. The features are not perfect, and sometimes a feature used in one frame disappears in the next frame. Multiple features decreases the chances that the algorithm will lose track by not being able to find any features in a frame.
MaxCount: The maximum number of good features to look for in a frame.
qlevel: The acceptable quality of the features. A higher quality feature is more likely to be unique, and therefore to be correctly findable in the next frame. A low quality feature may get lost in the next frame, or worse yet may be confused with another point in the image of the next frame.
minDist: The minimum distance between selected features.
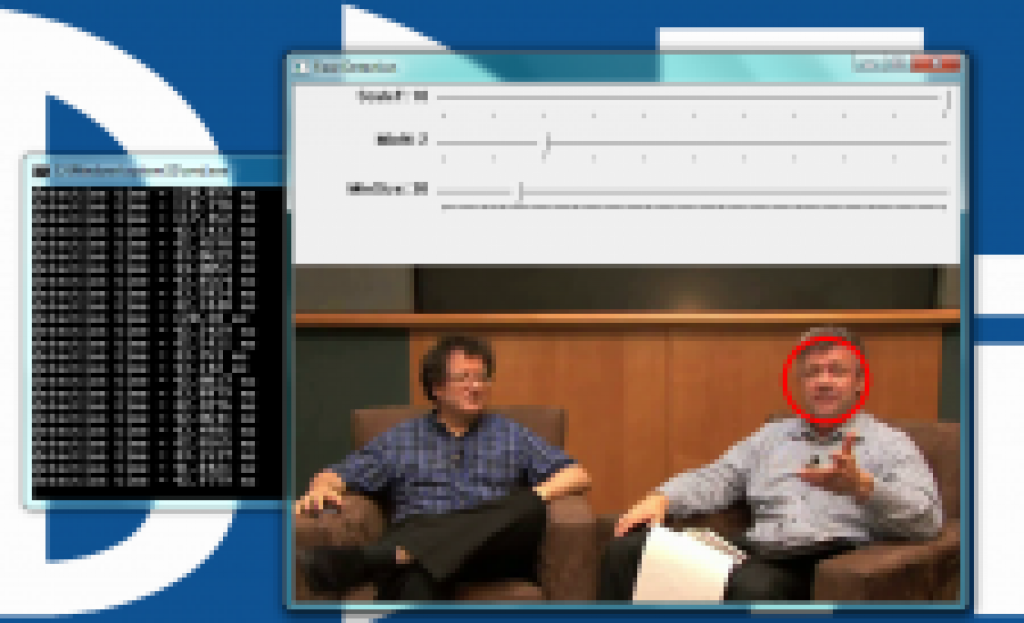
Face detector
The face detector used in this example is based on the Viola-Jones Haar-like feature detector algorithm (Figure 8). Throughout this article, we have been working with different algorithms for finding features; i.e. closely grouped pixels in an image or frame that are unique in some way. The motion detector used subtraction of one frame from the next frame to find pixels that moved, classifying these pixel groups as features. In the line detector example, features were groups of pixels organized in a straight line. And in the optical flow example, features were groups of pixels organized into corners or points in a image.
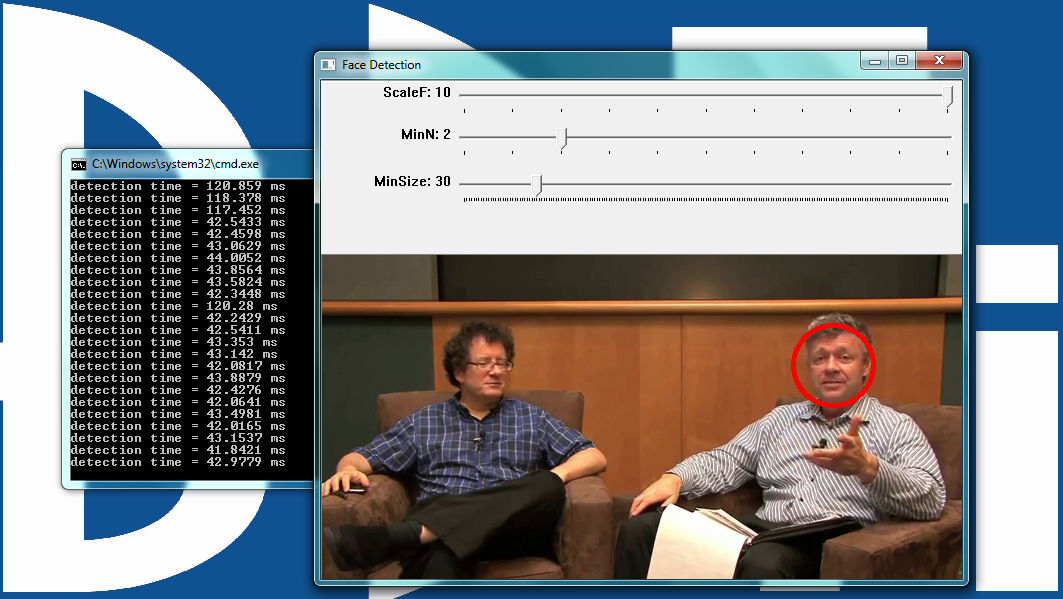
Figure 8: The user interface for the face detector example
The Viola-Jones algorithm uses a Haar-like discrete set of six features (the OpenCV implementation adds additional features). Haar-like features in a 2-D image include edges, corners, and diagonals. They are very similar to features in the optical flow example, except that detection of these particular features occurs via a different method. The purpose of this article is not to go into details of each algorithm; look for future articles covering in detail each of the algorithms used in these examples. For now, let’s get to the example.
As the name implies, the face detector example detects faces. Detection occurs within each individual frame; the detector does not track the face from frame to frame. The face detector can also detect objects other than faces. An XML file "describes" the object to detect. OpenCV includes various Haar cascade XLM files that you can use to detect various object types. OpenCV also includes tools to allow you to train your own cascade to any object you desire and save it as an XML file for use by the detector.
MinSize: The smallest face to detect. As a face gets further from the camera, it appears smaller. This parameter also defines the furthest distance a face can be from the camera and still get detected.
MinN: The minimum neighbor parameter groups faces that are detected multiple times into one detection. The face detector actually detects each face multiple times in slightly different positions. This parameter simply defines how to group the detections together. For example, a MinN of 20 would group all detection within 20 pixels of each other as a single face.
ScaleF: Scale factor determines the number of times to run the face detector at each pixel location. The Haar cascade XML file that determines the parameters of the to-be-detected object is designed for an object of only one size. In order to detect objects of various sizes (faces close to the camera as well as far away from the camera, for example) requires scaling the detector. This scaling process has to occur at every pixel location in the image. This process is computationally expensive, but a scale factor that is too large will not detect faces between detector sizes. A scale factor too small, conversely, can use a huge amount of CPU resources. You can see this phenomenon in the example if you first set the scale factor to its max value of 10. In this case, you will notice that as each face moves closer to or away from the camera, the detector will not detect it at certain distances. At these distances, the face size is in-between detector sizes. If you decrease the scale factor to its minimum, on the other hand, the required CPU resources skyrocket, as shown by the extended detection time.
Canny Edge Detector
Many algorithms exist for finding edges in an image. This example focuses on the Canny algorithm (Figure 9). Considered by many to be the best edge detector, the Canny algorithm was developed in 1986 by John F. Canny of U.C. Berkeley. In his paper, "A computational approach to edge detection," Canny describes three criteria to evaluate the quality of edge detection:
- Good detection: There should be a low probability of failing to mark real edge points, and low probability of falsely marking non-edge points. This criterion corresponds to maximizing signal-to-noise ratio.
- Good localization: The points marked as edge points by the operator should be as close as possible to the center of the true edge.
- Only one response to a single edge: This criterion is implicitly also captured in the first one, since when there are two responses to the same edge, one of them must be considered false.

Figure 9. The user interface for the Canny edge detector example
The example allows you to modify the Canny parameters on the fly using simple slider controls.
Low Thres: Canny Low Threshold Parameter (T2) (LowThres)
High Thres: Canny High Threshold Parameter (T1) (HighThres)
Gaus Size : Gaussian Filter Size (Fsize)
Sobel Size: Sobel Operator Size (Ksize)
The example also opens six windows representing the stages in the Canny edge detection algorithm. All windows are updated in real-time.
Gaussian Filter: This window shows the output of the Gaussian filter.
GradientX: The result of the horizontal derivative (Sobel) of the image in the Gaussian Filter window.
GradientY: The result of the vertical derivative (Sobel) of the image in the Gaussian Filter window.
Magnitude: This window shows the result of combining the GradientX and GradientY images using the equation G = |Gx|+|Gy|
Angle: Color-coded result of the angle equation, combining GradientX and GradientY using arctan(Gy/Gx).
Black = 0 degrees
Red = 1 degrees to 45 degrees
White = 46 degrees to 135 degrees
Blue = 136 degrees to 225 degrees
Green = 226 degrees to 315 degrees
Red = 316 degrees to 359 degrees
The 0-degree marker indicates the left to right direction, as shown in figure 10.
Canny: The Canny edgemap
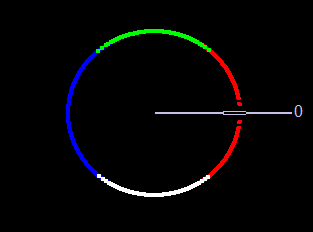
Figure 10. The direction color code for the angle window in the Canny edge detector example. Left to right is 0 degrees
Detection time
Each of these examples outputs the detection time to the console while the algorithm is running (Figure 9). This time represents the number of milliseconds the particular algorithm took to execute. A larger amount of time represents higher CPU utilization. The OpenCV library as built in these examples does not have hardware acceleration enabled, so the resultant detection times represent worst-case scenarios. OpenCV currently supports CUDA and NEON acceleration capabilities.
Figure 11: Console output of detection time during algorithm execution
Conclusion
The intent of this article and accompanying software is to help the reader understand the uses of some fundamental computer vision algorithms. These examples represent only a miniscule subset of algorithms in OpenCV; I chose them because at a high level they represent a broad usage model of computer vision. Leveraging these fundamental algorithms in combination with, or alongside, other available algorithms in the field of computer vision can help you solve various industrial, medical, automotive, and consumer electronics design problems.
Appendix: for advanced users
You can find all of the source code for the examples installed at:
C:\Program Files (x86)\BDTI\BDTI_OpenCV_Executable_Demo_Package\BDTI_OpenCV_Executable_Demo_Package\VS2009_VS2010_SourceProjects.zip
I've "wrapped" the source code with a Visual Studio 2008 project. If you have VS2008 installed on your computer, simply click on the .sln file located in the directory of the example you want to modify.
Each example project is built around a framework created to make writing OpenCV applications easy. The framework includes support for reading a stream from a AVI file or a web camera.
Appendix: references
OpenCV2.3 Programmers Reference Guide
Viola-Jones Object Detector (PDF)
Good Features to Track (PDF)
Lucas-Kanade Optical Flow (PDF)
Revision History
| November 25, 2011 | Initial version of this document |
| May 3, 2012 | Added Canny edge detection example, changed toolset name to "BDTI OpenCV Executable Demo Package" |