By Dong-Ik Ko (Lead Engineer, Gesture Recognition and Depth-Sensing) and Gaurav Agarwal (Manager, Gesture Recognition and Depth-Sensing)
Texas Instruments
This is a reprint of a Texas Instruments-published white paper, which is also available here (2.6 MB PDF).
Introduction
Over the past few years, gesture recognition has made its debut in entertainment and gaming markets. Now, gesture recognition is becoming a commonplace technology, enabling humans and machines to interface more easily in the home, the automobile and at work. Imagine a person sitting on a couch, controlling the lights and TV with a wave of his hand. This and other capabilities are being realized as gesture recognition technologies enable natural interactions with the electronics that surround us. Gesture recognition has long been researched with 2D vision, but with the advent of 3D sensor technology, its applications are now more diverse, spanning a variety of markets.
Limitations of (x, y) coordinate-based 2D vision
Computers are limited when it comes to understanding scenes, as they lack the ability to analyze the world around them. Key problems that computers have in understanding scenes include segmentation, object representation, machine learning and recognition. Because computers are limited by their 2D representation of scenes, a gesture recognition system has to apply various cues to acquire more accurate results and more valuable information. While the possibilities include whole-body tracking and other techniques that combine multiple cues, it is difficult to sense scenes using only 2D representation that do not include known 3D models of objects that they identify, such as human hands, bodies or faces.
“z” (depth) innovation
Depth information, or “z,” enables capabilities well beyond gesture recognition. The challenge in incorporating 3D vision and gesture recognition into technology has been obtaining this third “z” coordinate. The human eye naturally registers x, y and z coordinates for everything it sees, and the brain then interprets those coordinates into a 3D image. In the past, lack of image analysis technology prevented electronics from seeing in 3D. Today, there are three common technologies that can acquire 3D images, each with its own unique strengths and common use cases: stereoscopic vision, structured light pattern and time of flight (TOF). With the analysis of the 3D image output from these technologies, gesture-recognition technology becomes a reality.
Stereoscopic vision
The most common 3D acquisition system is the stereoscopic vision system, which uses two cameras to obtain a left and right stereo image. These images are slightly offset on the same order as the human eyes are. As the computer compares the two images, it develops a disparity image that relates the displacement of objects in the images. Commonly used in 3D movies, stereoscopic vision systems enable exciting and low-cost entertainment. It is ideal for 3D movies and mobile devices, including smartphones and tablets.
Structured light pattern
Structured light illuminates patterns to measure or scan 3D objects. Light patterns are created using either a projection of laser or LED light interference or a series of projected images. By replacing one of sensors of a stereoscopic vision system with a light source, structured-light-based technology basically exploits the same triangulation as a stereoscopic system does to acquire the 3D coordinates of the object. Single 2D camera systems with an IR- or RGB-based sensor can be used to measure the displacement of any single stripe of visible or IR light, and then the coordinates can be obtained through software analysis. These coordinates can then be used to create a digital 3D image of the shape.
Time of flight (TOF)
Relatively new among depth information systems, time of flight (TOF) sensors are a type of light detection and ranging (LIDAR) system that transmit a light pulse from an emitter to an object. A receiver determines the distance of the measured object by calculating the travel time of the light pulse from the emitter to the object and back to the receiver in a pixel format.
TOF systems are not scanners, as they do not measure point to point. Instead, TOF systems perceive the entire scene simultaneously to determine the 3D range image. With the measured coordinates of an object, a 3D image can be generated and used in systems such as device control in areas like manufacturing, robotics, medical technologies and digital photography. TOF systems require a significant amount of processing, and embedded systems have only recently provided the amount of processing performance and bandwidth needed these systems.
Comparing 3D vision technology
No single 3D vision technology can currently meet the needs for every market or application. Figure 1 shows a comparison of the different 3D vision technologies’ response time, software complexity, cost and accuracy.

Figure 1. 3D vision sensor technology comparison
Stereoscopic vision technology requires a large amount of software complexity for highly precise 3D depth data that can typically be processed and analyzed in real time by digital signal processors (DSPs) or multi-core scalar processors. Stereoscopic vision systems can be more cost effective and fit in a small form factor, making them a good choice for devices like smartphones, tablets and other consumer devices. However, stereoscopic vision systems cannot deliver the high accuracy and fast response time that other technologies can, so they are not the best choice for systems requiring high accuracy, such as manufacturing quality assurance systems.
Structured light technology is an ideal solution for 3D scanning of objects, including 3D computer aided design (CAD) systems. The highly complex software associated with these systems can be addressed by hardwired logics, such as ASICs and FPGAs, which require expensive development and materials costs. The computation complexity also results in a slower response time. At the macro level, structured light systems are better than other 3D vision technologies at delivering high levels of accuracy with less depth noise in an indoor environment.
Due to their balance of cost and performance, TOF systems are optimal for device control in areas like manufacturing and consumer electronics devices needing a fast response time. TOF systems typically have low software complexity. However, these systems integrate expensive illumination parts, such as LEDs and laser diodes, as well as costly high-speed interface-related parts, such as fast ADC, fast serial/parallel interface and fast PWM drivers, that increase material costs. Figure 1 provides a comparison of the three 3D sensor technologies.
How “z” (depth) impacts human- machine interfaces
The addition of the “z” coordinate allows displays and images to look more natural and familiar. Displays more closely reflect what people see with their own eyes, thus this third coordinate changes the types of displays and applications available to users.
Stereoscopic display
While using stereoscopic displays, users typically wear 3D glasses. The display emits different images for the left and right eye, tricking the brain into interpreting a 3D image based on the two different images the eyes receive. Stereoscopic displays are used in many 3D televisions and 3D movie theaters today. Additionally, we’re starting to see glasses-free stereoscopic-3D capabilities in the smartphone space. Users now have the ability to not only view 3D content from the palm of their hands, but also capture on-the-go memories in 3D and upload them instantly to the Web.
Multi-view display
Rather than requiring the use of special glasses, multi-view displays instead simultaneously project multiple images, each one slightly offset and angled properly so that a user can experience different projection of images for the same object for each viewpoint angle. These displays create a hologram effect that you can expect to see in the near future.
Detection and applications
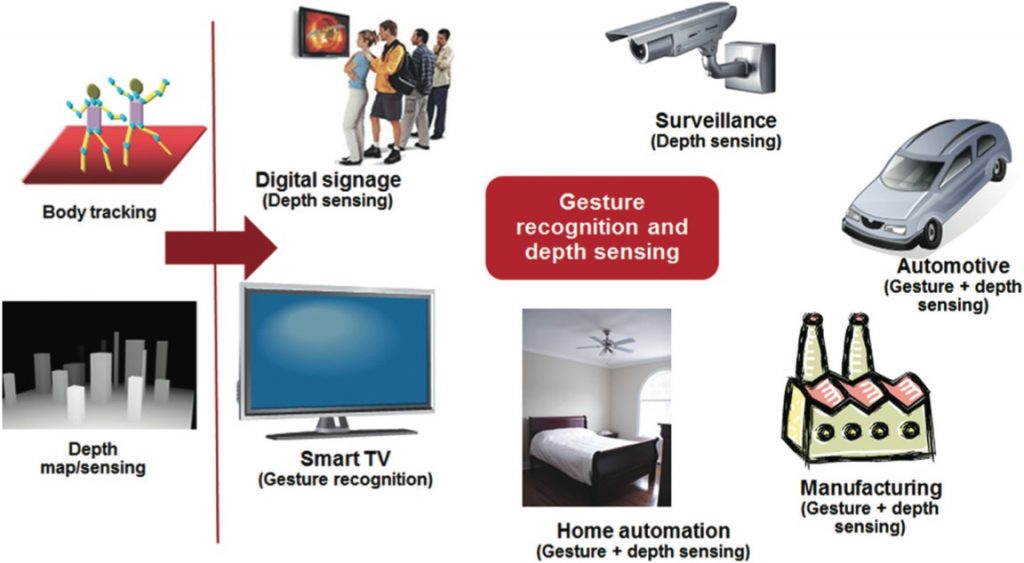
The ability to process and display the “z” coordinate is enabling new applications far beyond entertainment and gaming, including manufacturing control, security, interactive digital signage, remote medical care, automotive safety and robotic vision. Figure 2 depicts some applications enabled by body skeleton and depth map sensing.

Figure 2. 3D vision is enabling new applications in a variety of markets
Human gesture recognition for consumer applications
Human gesture recognition is a popular new way to input information in gaming, consumer and mobile devices, including smartphones and tablets. Users can naturally and intuitively interact with the device, leading to greater acceptance and approval of the products. These human-gesture-recognition products include various resolutions of 3D data, from 160 × 120 pixels to 640 × 480 pixels at 30–60 fps. Software modules such as raw-to-depth conversion, two-hand tracking and full-body tracking require parallel processing for efficient and fast analysis of the 3D data to deliver gaming and tracking in real time.
Industrial
A majority of industrial applications for 3D vision, including industrial and manufacturing sensors, integrate an imaging system from as few as 1 pixel to several million pixels. The 3D images can be manipulated and analyzed using DSP + general-purpose processor (GPP) system-on-chip (SoC) processors to accurately detect manufacturing flaws or choose the correct parts from a factory bin.
Interactive digital signage as a pinpoint marketing tool
Advertisements already bombard us on a daily basis, but with interactive digital signage, companies will be increasingly able to use pinpoint marketing tools to deliver the most applicable content to each consumer. For example, as someone walks past a digital sign, an extra message may appear on the sign to acknowledge the customer. If the customer stops to read the message, the sign can interpret that as interest in their prod- uct and deliver a more targeted message. Microphones allow the billboard to recognize significant phrases to further strategically pinpoint the delivered message.
Interactive digital signage systems integrate a 3D sensor for full body tracking, a 2D sensor for facial recognition and microphones for speech recognition. The systems require functionality like MPEG-4 video decoding. High-end DSPs and GPPs are necessary to run the complex analytics software for these systems.
Fault-free virtual or remote medical care
The medical field also benefits from the new and unprecedented applications that 3D vision offers. This technology will ensure that the best medical care is available to everyone, no matter where they are located in the world. Doctors can remotely and virtually treat patients by utilizing medical robotic vision enabled by high accuracy of 3D sensors.
Automotive safety
Recently, 2D sensors have enabled extensive improvements in automotive technology, specifically in traffic signal, lane and obstacle detection. With the proliferation of 3D sensing technology, “z” data from 3D sensors can significantly improve the reliability of scene analysis and prevent more accidents on the road. Using a 3D sensor, a vehicle can reliably detect and interpret the world around it to determine if objects are a threat to the safety of the vehicle and the passengers inside, ultimately preventing collisions. These systems will require the right hardware and sophisticated software to interpret the 3D images in a very timely manner.
Video conferencing
Gone are the years of videoconferences with grainy, disjointed images. Today’s video conferencing systems offer high-definition images, and newer systems leverage 3D sensors to deliver an even more realistic and interactive experience. With integrated 2D and 3D sensors as well as a microphone array, this enhanced video conferencing system can connect with other enhanced systems to enable high-quality video processing, facial recognition, 3D imaging, noise cancellation and content players, including Flash. Given the need for intensive video and audio processing in this application, a DSP + GPP SoC processor will offer the optimum solution with the best mix of performance and peripherals to deliver the required analytical functionality.
Technology processing steps
Many applications will require both a 2D and 3D camera system to properly enable 3D imaging technology. Figure 3 on the following page shows the basic data path of these systems. Moving the data from the sensors and into the vision analytics is more complex than it seems from the data path. Specifically, TOF sensors require up to 16 times the bandwidth of 2D sensors, causing a shortage of bandwidth for input/output (I/O). Another bottleneck occurs when processing the raw 3D data to a 3D point cloud. Identifying the right combination of hardware and software to mitigate these issues is critical for successful gesture recognition and 3D applications. Today, this data path is realized in DSP/GPP combination processors along with discrete analog components and software libraries.
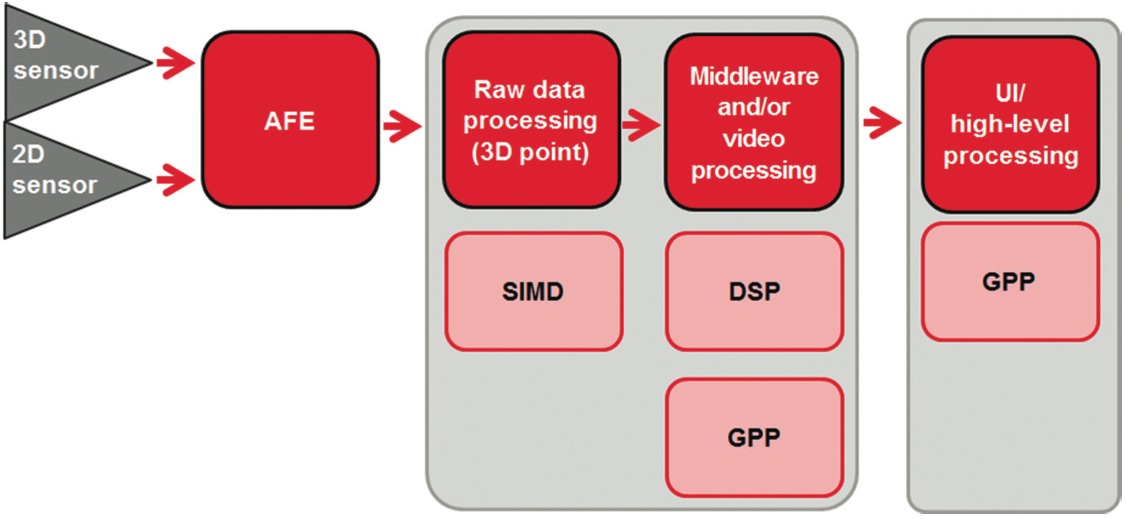
Figure 3. Data path of 2D and 3D camera systems
Challenges for 3D vision embedded systems
Input challenges
As discussed, input bandwidth constraints are a challenge, specifically for TOF-based 3D vision embedded systems. Due to the lack of standardization for the input interface, designers can choose to work with different input options, including serial and parallel interfaces for 2D sensor as well as general-purpose external- memory interfaces. Until a standard input interface with optimum bandwidth is developed, designers will have to work with the unstandardized options available today.
Two different processor architectures
In Figure 3, 3D depth map processing can be divided into two categories: 1) vision-specific, data-centric processing [low-level processing] and 2) application upper-level processing [mid- to high-level processing]. Vision specific, data-centric processing requires a processor architecture that can perform single instruction, multiple data (SIMD), fast floating-point multiplication and addition, and fast search algorithms. A DSP (SIMD+VLIW) or SIMD-based accelerator is an ideal candidate for quickly and reliably performing this type of processing. High-level operating systems (O/Ss) and stacks can provide the necessary features for the upper layer of any application.
Based on the requirements for vision-specific, data centric processing as well as application upper-level processing, an SoC that provides a GPP+DSP+SIMD processor with a high data rate I/O is well suited for 3D vision processing.
Lack of standard middleware
The world of middleware for 3D vision processing encompasses many different pieces from multiple sources, including open source (e.g., OpenCV) as well as proprietary commercial sources. Several commercial libraries are targeted toward body-tracking applications. However, no company has yet developed a middleware interface that is standardized across all the different 3D vision applications. When standardized middleware is available, development will become much faster and easier, and we can expect to see a huge proliferation of 3D vision and gesture recognition technologies across a variety of markets.
Opportunities abound with the proliferation of 3D vision and gesture recognition technologies, and Texas Instruments Incorporated (TI) and its partners are leading the charge in bringing 3D capabilities to new markets and in providing the hardware and middleware our customers need to innovate groundbreaking and exciting analytical applications.
3D vision software architecture
In this section, we will explore some of the more specific TI technologies used to implement the 3D vision architecture necessary to power these new applications. The following information is based on TI’s DaVinciTM video processor and OMAPTM application processor technology.
As stated earlier, TI’s integrated system allows low-level, mid-level and high-level processing to be distributed across multiple processing devices. This enables optimal performance with the most fitting processors. One possible case of 3D vision application process loads can be seen in Figure 4. We can see that low-level processing covers about 40 percent of the processing load for extracting the depth map and filtering. In addition, more than 55 percent of the load is dedicated toward mid- and high-level processing for motion flow, object segmentation and labeling, and tracking.
Figure 4. 3D vision application processing loads (case 1)
Figure 5 shows another case of 3D vision application processing loads where low-level processing for the calculation of segmentation, background and human body covers 20 percent of the total loads, and mid- to high-level processing takes 80 percent.

Figure 5. 3D vision application processing loads (case 2)
Here, detailed methods and algorithms applied could be different for similar processing cells. Thus, same or similar processing cells in Figures 4 and 5 are categorized to different processing levels. The approach in case 1 analyzes the entire scene block by block and then extracts foreground objects. Thus, object segmentation cell is heavier because it touches all pixels. The advantage of this approach is that it can label all objects in the background (such as furniture, non-moving people) and foreground (usually moving objects like people) whether or not objects in the scene are static or dynamic. This approach will be not only be used in gesture applications, but also in surveillance applications. The approach in case two analyzes only moving pixels and connects pixels by analyzing contours and labeling them. The advantage is that fewer computation cycles are required compared to case 1. However, a person must move at least slightly to be detected.
It is important to understand what type of processing is needed for each step in the application in order to properly allocate to the correct processing unit. As demonstrated by Figures 4 and 5, 3D vision architecture should support optimized and balanced hardware IPs for low- to high-level processing of 3D vision software stack.
3D vision hardware architectures
There are various hardware architecture options for 3D vision applications, each with pros and cons.
ISP (Image signal processing)
Due to differences in requirements of 3D vision’s depth acquisition methods (stereoscopic vision, structured light, TOF), it is difficult to define a universal interface for all three technologies. Standard sensor interface formats for 2D, such as CSI2 and parallel ports, can seamlessly support stereoscopic vision and structured light technology up to 1080p resolution. However, TOF technology requires much higher (up to 16 times) data interface bandwidth, has a unique data width per pixel and has additional metadata compared to other two 3D vision depth technologies. Currently, no standard data interface for TOF has been defined. Thus, multiple CSI2 interfaces or CSI3 or parallel interface are considered depending on TOF sensor resolution. These interfaces, originally designed for artifacts of 2D sensors, do not fully utilize 3D sensor (structured light and TOF)’s specifics.
Besides data interface issue for 3D sensor technology, 3D vision specific digital signal processing (lens correction, noise filtering, resizing, compression and 3A: auto exposure, auto focus, auto white balance) can be defined in ISP along with 2D sensor-specific image processing. Some functional logics for 2D sensor can be reused for improving 3D sensor depth quality, but 3D-specific processing is necessary for specific functions. For example, a TOF sensor’s noise pattern is different than a 2D sensor’s one. In structured light technology, noise-handling methods can be different depending on depth accuracy and interested depth coverage.
SIMD (single instruction multiple data) and VLIW (very long instruction word)
-
Pros
- Flexible programming environment
- Algorithms with dependencies on neighboring elements
- Data parallelism and throughput
-
Cons
- Depend too much on compiler’s performance and efficiency in fast prototyping
- Need effort (manual optimization depending on algorithms) to acquire fair performance improvement
- Poor utilization of parallelism for high-level processing vision algorithms.
Graphics processing unit (GPU)
-
Pros
- Easy programming environment
- Fast prototyping and optimization
- Data and task parallelism and throughput
- MIMD (multiple instruction and multiple data) friendly
-
Cons
- Inefficient hardware architecture for utilizing vision algorithms’ operational features
- High power consumption and area size
- Inefficient memory access and inter-processor communication (IPC)
- Limitation in algorithm complexity per kernel
GPP (single- and multi-core)
-
Pros
- Most flexible programming environment
- Fast prototyping and quick optimization
- High portability
-
Cons
- Poor utilization of parallelism
- Low throughput
- High power consumption due to a high clock cycle
- Area size
Hardware accelerator
-
Pros
- Highly optimized area and power consumption
- Data parallelism and throughput
- Block processing friendly architecture (low- and mid-level processing friendly)
- One-at-a-time optimization. In other words, “what you program is what you get.” At the programming stage, the actual cycles required at runtime can be obtained because there is no dependency on compiler tuning, runtime memory hierarchy associated delay and data & control hazard.
-
Cons
- Poor programming environment
- Much more software engineering effort is required to acquire a fair optimization
- Inefficient in context switch of algorithms
- Poor portability
TI’s 3D vision hardware IPs
Below is a brief overview of the hardware IPs available from TI and where they traditionally lie in the low-, mid- and high-level processing usage.
Vision accelerator
-
Architecture
- Hardware accelerator
-
Vision application mapping
- Low- to mid-level processing
DSP
-
Architecture
- SIMD & VLIW
-
Vision application mapping
- Mid- to high-level processing
ARM®
-
Architecture
- GPP
-
Vision application mapping
- Low-, mid- and high-level processing
TI’s 3D vision hardware and software stack
TI’s 3D vision hardware and software stack shows how TI’s hardware IPs are leveraged for optimizing 3D vision systems. TI’s 3D processor options include vision accelerators and DSPs. These IPs are integrated into TI’s embedded chips depending on the targeted application’s requirements. These optimized 3D processors boost system performance when processing 3D vision middleware and the 3D Vision Low-Level Library (3DV Low Lib). 3D application software, which utilizes accelerated 3D vision middleware, is ported on the GPP (ARM). The 3D application software layer offers an innovative human-machine user experience on top of the underlying vision analytics algorithms. It also communicates with the 3D sensor device to send 3D depth data and 2D RGB data to the vision analytics algorithms associated with the system software layers. The LinuxTM platform provides system-associated functions over GPP (ARM). TI’s 3D vision hardware and software stack is illustrated in Figure 6.
Figure 6. TI’s 3D vision hardware and software stack
Additionally, TI provides a range of libraries, including DSP Lib, Image Lib, Vision Lib and OpenCV kernels. These libraries, shown in Figure 7, enable customers to reduce their time to market and enhance performance on TI devices. Customers can also tap into TI’s network of third-party designers for additional software and hardware tools to aid development of 3D vision and gesture recognition applications.
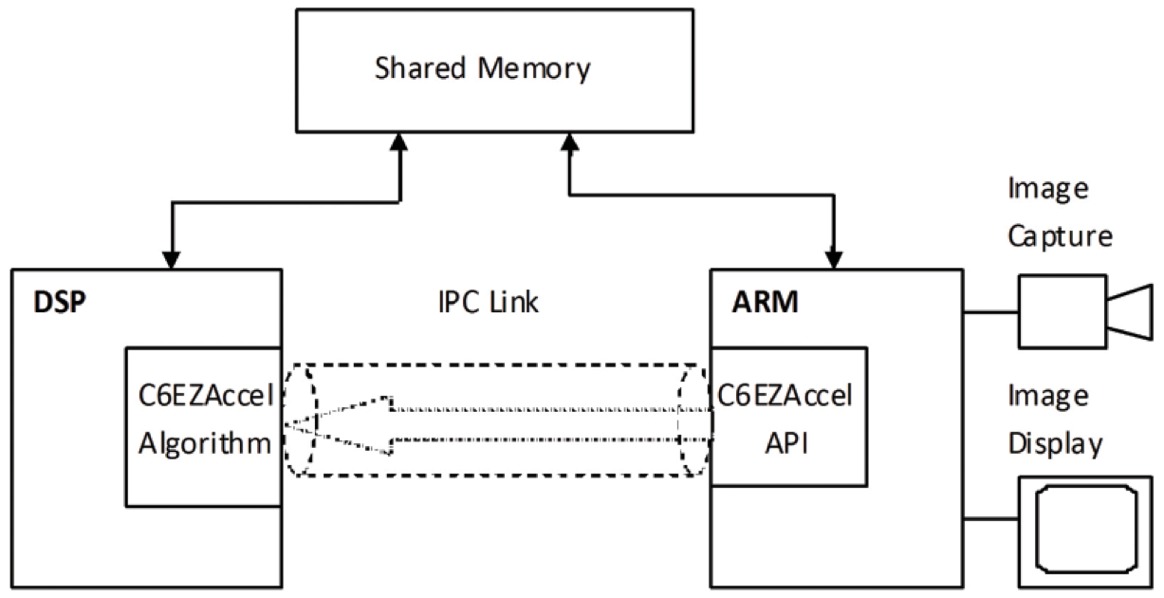
Figure 7. TI vision software solutions
Figure 8 shows TI’s broad processor portfolio for 3D vision, including the DaVinci DM36x video processors hand-tracking-based solutions; the DM385 processors for hand-tracking or upper- body-tracking solutions with SkypeTM solutions; the OMAP 3 processors and the DM3730 processor for body- tracking solutions; and the OMAP 4, OMAP 5 and DM8148 processors for integrated voice and Skype together with gesture and body tracking, face detection, and augmented reality. In addition, the SitaraTM AM335x and AM37x ARM® microprocessors (MPUs) can perform 2D vision for hand tracking and face detection.
Figure 8. TI’s 3D vision processor roadmap
Optimized hardware architecture may lead to more engineering effort on the software side. Thus, delivering optimized architectures always should go hand in hand with offering handy development tools. TI provides graphical-user-interface- and integrated-development-environment-based development tools for 3D processors (DSPs and accelerators), which can accelerate customers’ development cycles and can help them accelerate time to market. TI’s Code Composer StudioTM integrated development environment (IDE) and Eclipse-compliant plugins to the IDE for accelerators are popular options.
Conclusion
Despite several challenges, 3D vision and gesture tracking are getting attention and gaining traction in the market. TI offers a complete solution, including a range of processors, tools and comprehensive software, to enable customers to quickly and easily bring leading 3D vision products to market. TI continues to innovate to meet market challenges, leading to even greater adoption of gesture and 3D applications beyond the consumer electronics market. When it comes to applications that make interactions between humans and their devices more interactive and natural, the sky is the limit.