
A version of this article was originally published at InTech Magazine. It is reprinted here with the permission of the International Society of Automation.
In order for manufacturing robots and other industrial automation systems to meaningfully interact with the objects they're assembling, as well as to deftly and safely move about in their environments, they must be able to see and understand their surroundings. Cost-effective and capable vision processors, fed by depth-discerning image sensors and running robust software algorithms, are transforming longstanding autonomous and adaptive industrial automation aspirations into reality.
By Michael Brading
Automotive and Industrial Business Unit Chief Technology Officer
Aptina Imaging
Brian Dipert
Editor-in-Chief
Embedded Vision Alliance
Tim Droz
Vice President and General Manager
SoftKinetic North America
Pedro Gelabert
Senior Member of the Technical Staff and Systems Engineer
Texas Instruments
Carlton Heard
Product Marketing Manager – Vision Hardware & Software
National Instruments
Yvonne Lin
Marketing Manager – Medical & Industrial Imaging
Xilinx
Thomas Maier
Sales & Business Development – Time-of-Flight Sensors
Bluetechnix
Manjunath Somayaji
Staff Imaging Scientist
Aptina Imaging
and Daniël Van Nieuwenhove
Chief Technical Officer
SoftKinetic
Automated systems in manufacturing line environments are capable of working more tirelessly, faster, and more exactly than do their human forebears. However, their success has traditionally been predicated on incoming parts arriving in fixed orientations and locations, thereby increasing manufacturing process complexity. Any deviation in part position and/or orientation will result in assembly failures. Humans use their eyes (along with other senses) and brains to understand and navigate through the world around them. Robots and other industrial automation systems should be able to do the same thing, leveraging camera assemblies, vision processors, and various software algorithms in order to skillfully adapt to evolving manufacturing line circumstances, as well as to extend vision processing's benefits to other areas of the supply chain, such as piece parts and finished goods inventory tracking.
Historically, such vision-augmented technology has typically only been found in a short list of complex, expensive systems. However, cost, performance and power consumption advances in digital integrated circuits are now paving the way for the proliferation of vision into diverse mainstream automated manufacturing platforms. Implementation challenges remain, but they're more easily, rapidly, and cost-effectively solved than has ever before been possible. And an industry alliance comprised of leading product and service suppliers is a key factor in this burgeoning technology success story.
Inventory Tracking
Embedded vision innovations can help improve product tracking through production lines and with enhanced storage efficiency. While bar codes and RFID tags can also help track and route materials, they cannot be used to detect damaged or flawed goods. Intelligent raw material and product tracking and handling in the era of embedded vision will be the foundation for the next generation of inventory management systems, as image sensor technologies continue to mature and as other vision processing components become increasingly integrated. High-resolution cameras can already provide detailed images of work material and inventory tags, but complex, real-time software is needed to analyze the images, to identify objects within them, to identify ID tags associated with these objects, and to perform quality checks.
The phrase “real-time” can potentially mean rapidly evaluating dozens of items per second. To meet the application’s real-time requirements, various tasks must often run in parallel. On-the-fly quality checks can be used to spot damaged material and can be used to automatically update an inventory database with information about each object and details of any quality issues. Vision systems for inventory tracking and management can deliver robust capabilities without exceeding acceptable infrastructure costs, through the integration of multiple complex real-time video analytics extracted from a single video stream.
Automated Assembly
Embedded vision is a key enabling technology for the factory production floor, in areas such as raw materials handling and assembly. Cameras find use in acquiring images of (for example) parts or destinations, and subsequent vision processing sends data to a robot, enabling it to perform functions such as picking up and placing a component. As previously mentioned, industrial robots inherently deliver automation benefits such as scalability and repeatability. Adding vision processing to the mix allows these machines to be far more flexible. The same robot, for example, can be used with a variety of parts, because it can see which particular part it is dealing with at any point in time and adapt accordingly.
Vision also finds use in applications that require high precision assembly; cameras can "image" components after they're picked up, with slight corrections in the robot position made to compensate for mechanical imperfections and varying grasping locations (Figure 1). Picking parts from a bin also becomes easier. A camera can be used to locate a particular part with an orientation that can be handled by the robotic arm, within a pile of parts.

Figure 1. A pharmaceutical packaging line uses vision-guided robots to quickly pick syringes from conveyer belts and place them into packages.
Depth-discerning 3D vision is a growing trend that can help robots perceive even more about their environments. Cost-effective 3D vision is now appearing in a variety of applications, from vision-guided robotic bin-picking to high precision manufacturing metrology. Latest-generation vision processors can now adeptly handle the immense data sets and sophisticated algorithms required to extract depth information and rapidly make decisions. 3D imaging is enabling vision processing tasks that were previously impossible with traditional 2D cameras (Figure 2). Depth information can be used, for example, to guide robots in picking up parts that are disorganized in a container.

Figure 2. 3D imaging is used to measure the shape of a cookie and inspect it for defects.
Automated Inspection
An added benefit of using vision for robotic guidance is that the same images can also be used for in-line inspection of parts being handled. In this way, not only are robots more flexible, they can produce higher quality results. This outcome can also be accomplished at lower cost because the vision system can detect, predict, and prevent "jams" and other undesirable outcomes. If a high degree of accuracy is needed within the robot's motion, a technique called visual servo control can be used. The camera is either fixed to the robot or nearby it and gives continuous visual feedback (versus only a single image at the beginning of the task) to enable the robot controller to correct for small errors in movement.
Beyond robotics, vision has many uses and delivers many benefits in automated inspection, performing tasks such as checking for the presence of components, reading text and barcodes, measuring dimensions and alignment, and locating defects and patterns. Historically, quality assurance was often performed by randomly selecting samples from the production line for manual inspection, with statistical analysis then being used to extrapolate the results to the larger manufacturing run. This approach leaves unacceptable room for defective parts to cause jams in machines further down the manufacturing line or for defective products to be shipped. Automated inspection, on the other hand, can provide 100% quality assurance. And with recent advancements in vision processing performance, automated visual inspection is frequently no longer the limiting factor in manufacturing throughput.
The vision system is just one piece of a multi-step puzzle and must be synchronized with other equipment and I/O protocols in order to work well within an application (Figure 3). A common inspection scenario involves the sorting of faulty parts from correct ones as they transition through the production line. These parts move along a conveyer belt with a known distance between the camera and the ejector location that removes faulty parts. As the parts migrate, their individual locations must be tracked and correlated with the image analysis results, in order to ensure that the ejector correctly sorts out failures.

Figure 3: Production and assembly applications, such as the system in this winery, need to synchronize a sorting system with the visual inspection process.
Multiple methods exist for synchronizing the sorting process with the vision system, such as the use of timestamps with known delays, and proximity sensors that also keep track of the number of parts that pass by. However, the most common method relies on encoders. When a part passes by the inspection point, a proximity sensor detects its presence and triggers the camera. After a known encoder count, the ejector will sort the part based on the results of the image analysis.
The challenge with this technique is that the system processor must constantly track the encoder value and proximity sensors while simultaneously running image processing algorithms, in order to classify the parts and communicate with the ejection system. This multi-function juggling can lead to a complex software architecture, add considerable amounts of latency and jitter, increase the risk of inaccuracy, and decrease throughput. High-performance processors such as FPGAs are now being used to solve this challenge by providing a hardware-timed method of tightly synchronizing inputs and outputs with vision inspection results.
Workplace Safety
Humans are still a key aspect of the modern automated manufacturing environment, adding their flexibility to adjust processes "on the fly." They need to cooperate with robots, which are no longer confined in cages but share the workspace with their human coworkers. Industrial safety in this context is a big challenge, since increased flexibility and safety objectives can be contradictory. A system deployed in a shared workspace needs to have a higher level of perception of surrounding objects, such as other robots, work pieces and human beings.
3D cameras can greatly enhance the capability to create a reliable map of the environment around the robot. This capability allows for robust detection of people in safety and warning zones, enabling adaptation of movement trajectories and speeds for cooperation purposes, as well as providing collision avoidance. Vision-based safety ADAS (advanced driver assistance systems) are already widely deployed in automobiles, and the first vision-based industrial automation safety products are now entering the market. They aim to offer a smart and flexible approach to machine safety, necessary for reshaping factory automation.
Depth Sensing
As already mentioned, 3D cameras can deliver notable advantages over their 2D precursors in manufacturing environments. Several depth sensor technology alternatives exist, each with strengths, shortcomings and common use cases (Table A and Reference 1). Stereoscopic vision, combining two 2-D image sensors, is currently the most common 3-D sensor approach. Passive (i.e. relying solely on ambient light) range determination via stereoscopic vision utilizes the disparity in viewpoints between a pair of near-identical cameras to measure the distance to a subject of interest. In this approach, the centers of perspective of the two cameras are separated by a baseline or IPD (inter-pupillary distance) to generate the parallax necessary for depth measurement (Figure 4).
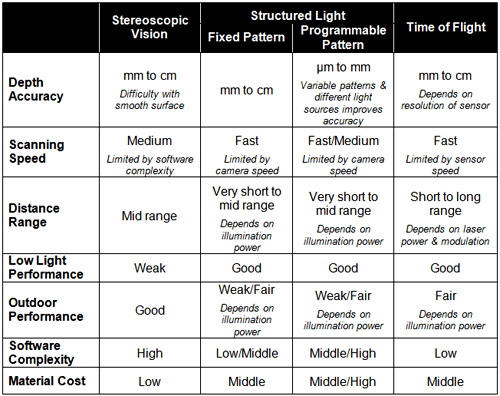
Table A: 3-D vision sensor technology comparisons.
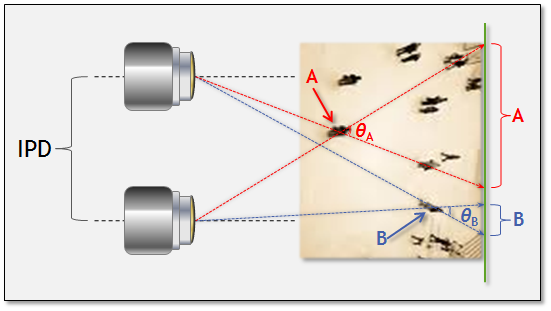
Figure 4: Relative parallax shift as a function of distance. Subject A (nearby) induces a greater parallax than subject B (farther out), against a common background.
Microsoft's Kinect is today's best-known structured light-based 3-D sensor. The structured light approach, like the time-of-flight technique to be discussed next, is an example of an active scanner, because it generates its own electromagnetic radiation and analyzes the reflection of this radiation from the object. Structured light projects a set of patterns onto an object, capturing the resulting image with an offset image sensor. Similar to stereoscopic vision techniques, this approach takes advantage of the known camera-to-projector separation to locate a specific point between them and compute the depth with triangulation algorithms. Thus, image processing and triangulation algorithms convert the distortion of the projected patterns, caused by surface roughness, into 3-D information (Figure 5).

Figure 5: An example structured light implementation using a DLP-based modulator.
An indirect ToF (time-of-flight) system obtains travel-time information by measuring the delay or phase-shift of a modulated optical signal for all pixels in the scene. Generally, this optical signal is situated in the near-infrared portion of the spectrum so as not to disturb human vision. The ToF sensor in the system consists of an array of pixels, where each pixel is capable of determining the distance to the scene. Each pixel measures the delay of the received optical signal with respect to the sent signal (Figure 6). A correlation function is performed in each pixel, followed by averaging or integration. The resulting correlation value then represents the travel time or delay. Since all pixels obtain this value simultaneously, "snap-shot" 3-D imaging is possible.
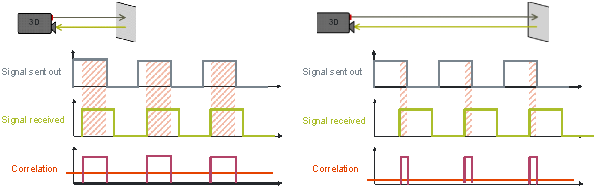
Figure 6: Varying sent-to-received delays correlate to varying distances between a time-of-flight sensor and portions of an object or scene.
Vision Processing
Vision algorithms typically require high compute performance. And unlike many other applications, where standards mean that there is strong commonality among algorithms used by different equipment designers, no such standards that constrain algorithm choice exist in vision applications. On the contrary, there are often many approaches to choose from to solve a particular vision problem. Therefore, vision algorithms are very diverse, and tend to change fairly rapidly over time. And, of course, industrial automation systems are usually required to fit into tight cost and power consumption envelopes.
Achieving the combination of high performance, low cost, low power, and programmability is challenging (Reference 2). Special-purpose hardware typically achieves high performance at low cost, but with little programmability. General-purpose CPUs provide programmability, but with weak performance, poor cost-effectiveness, and/or low energy-efficiency. Demanding vision processing applications most often use a combination of processing elements, which might include, for example:
- A general-purpose CPU for heuristics, complex decision-making, network access, user interface, storage management, and overall control
- A high-performance digital signal processor for real-time, moderate-rate processing with moderately complex algorithms, and
- One or more highly parallel engines for pixel-rate processing with simple algorithms
While any processor can in theory be used for vision processing in industrial automation systems, the most promising types today are the:
- High-performance CPU
- Graphics processing unit (GPU) with a CPU
- Digital signal processor with accelerator(s) and a CPU, and
- Field programmable gate array (FPGA) with a CPU
The Embedded Vision Alliance
The rapidly expanding use of vision technology in industrial automation is part of a much larger trend. From consumer electronics to automotive safety systems, we today see vision technology enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. We use the term “embedded vision” to refer to this growing practical use of vision technology in embedded systems, mobile devices, special-purpose PCs, and the cloud, with industrial automation being one showcase application.
Embedded vision can add valuable capabilities to existing products, such as the vision-enhanced industrial automation systems discussed in this article. And it can provide significant new markets for hardware, software and semiconductor manufacturers. The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower engineers to transform this potential into reality (Figure 7). Aptina Imaging, Bluetechnix, National Instruments, SoftKinetic, Texas Instruments and Xilinx, the co-authors of this article, are members of the Embedded Vision Alliance.
Figure 7: The embedded vision ecosystem spans hardware, semiconductor, and software component suppliers, subsystem developers, systems integrators, and end users, along with the fundamental research that provides ongoing breakthroughs.
First and foremost, the Alliance's mission is to provide engineers with practical education, information, and insights to help them incorporate embedded vision capabilities into new and existing products. To execute this mission, the Alliance maintains a website (www.embedded-vision.com) providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Alliance’s twice-monthly email newsletter (www.embeddedvisioninsights.com), among other benefits.
In addition, the Embedded Vision Alliance offers a free online training facility for embedded vision product developers: the Embedded Vision Academy (www.embeddedvisionacademy.com). This area of the Alliance website provides in-depth technical training and other resources to help engineers integrate visual intelligence into next-generation embedded and consumer devices. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCV. Access is free to all through a simple registration process (www.embedded-vision.com/user/register).
The Embedded Vision Summit
The Alliance also holds Embedded Vision Summit conferences in Silicon Valley (www.embeddedvisionsummit.com). Embedded Vision Summits are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Alliance member companies. These events are intended to:
- Inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations.
- Offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and
- Provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May, 2014, and a comprehensive archive of keynote, technical tutorial and product demonstration videos, along with presentation slide sets, is available on the Alliance website. The next Embedded Vision Summit will take place on April 30, 2015 in Santa Clara, California; please reserve a spot on your calendar and plan to attend.
References:
- www.embedded-vision.com/platinum-members/embedded-vision-alliance/embedded-vision-training/documents/pages/3d-sensors-depth-discernment
- www.embedded-vision.com/platinum-members/bdti/embedded-vision-training/documents/pages/processing-options-implementing-visio
Michael Brading is Chief Technical Officer of the Automotive Industrial and Medical business unit at Aptina Imaging. Prior to that, Mike was Vice President of Engineering at InVisage Technologies. Mike has more than 20 years of integrated circuit design experience, working with design teams all over the world. Michael was also previously the director of design and applications at Micron Technology, and the director of engineering for emerging markets. And before joining Micron Technology, he also held engineering management positions with LSI Logic. Michael has a B.S. in communication engineering from the University of Plymouth.
Brian Dipert is Editor-In-Chief of the Embedded Vision Alliance. He is also a Senior Analyst at BDTI, and Editor-In-Chief of InsideDSP, the company's online newsletter dedicated to digital signal processing technology. Brian has a B.S. degree in Electrical Engineering from Purdue University in West Lafayette, IN. His professional career began at Magnavox Electronics Systems in Fort Wayne, IN; Brian subsequently spent eight years at Intel Corporation in Folsom, CA. He then spent 14 years at EDN Magazine.
Tim Droz heads the SoftKinetic U.S. organization, delivering 3D TOF (time-of-flight) and gesture solutions to international customers, such as Intel and Texas Instruments. Prior to SoftKinetic, he was Vice President of Platform Engineering and head of the Entertainment Solutions Business Unit at Canesta, subsequently acquired by Microsoft. His pioneering work extends into all aspects of the gesture and 3D ecosystem, including 3D sensors, gesture-based middleware and applications. Tim earned a BSEE from the University of Virginia, and a M.S. degree in Electrical and Computer Engineering from North Carolina State University.
Pedro Gelabert is a Senior Member of the Technical Staff and Systems Engineer at Texas Instruments. He has more than 20 years of experience in DSP algorithm development and implementation, parallel processing, ultra-low power DSP systems and architectures, DLP applications, and optical processing, along with architecting digital and mixed signal devices. Pedro received his B.S. degree and Ph.D. in electrical engineering from the Georgia Institute of Technology. He is a member of the Institute of Electrical and Electronics Engineers, holds four patents and has published more than 40 papers, articles, user guides, and application notes.
Carlton Heard is a Product Manager at National Instruments, responsible for vision hardware and software. He has been with the company since 2007 and has led company initiatives in vision-guided robotics and FPGA-based embedded control. Carlton has a Bachelors degree in aerospace and mechanical engineering from Oklahoma State University.
Yvonne Lin is the Marketing Manager for medical and industrial imaging at Xilinx. She has been successfully championing FPGA adoption across multiple market segments for the past 14 years. Prior to joining Xilinx, she worked at Actel (now Microsemi) and Altera, contributing to system-on-chip product planning, software benchmarking and customer applications. Yvonne holds a Bachelor Electrical Engineering from the University of Toronto.
Thomas Maier is a Sales and Field Application Engineer at Bluetechnix, and been working on embedded systems for more than 10 years, particularly on various embedded image processing applications on DSP architectures. After completing the Institution of Higher Education at Klagenfurt, Austria in the area of telecommunications and electronics, he studied at the Vienna University of Technology. Thomas has been at Bluetechnix since 2008.
Manjunath Somayaji is the Imaging Systems Group manager at Aptina Imaging, where he leads algorithm development efforts on novel multi-aperture/array-camera platforms. For the past ten years, he has worked on numerous computational imaging technologies such as multi-aperture cameras and extended depth of field systems. He received his M.S. degree and Ph.D. from Southern Methodist University (SMU) and his B.E. from the University of Mysore, all in Electrical Engineering. He was formerly a Research Assistant Professor in SMU's Electrical Engineering department. Prior to SMU, he worked at OmniVision-CDM Optics as a Senior Systems Engineer.
Daniël Van Nieuwenhove is the Chief Technical Officer at SoftKinetic. He co-founded Optrima in 2009, and acted as the company's Chief Technical Officer and Vice President of Technology and Products. Optrima subsequently merged with SoftKinetic in 2010. He received an engineering degree in electronics with great distinction at the VUB (Free University of Brussels) in 2002. Daniël holds multiple patents and is the author of several scientific papers. In 2009, he obtained a Ph.D. degree on CMOS circuits and devices for 3-D time-of-flight imagers. As co-founder of Optrima, he brought its proprietary 3-D CMOS time-of-flight sensors and imagers to market.