
A version of this article was originally published at EE Times' Embedded.com Design Line. It is reprinted here with the permission of EE Times.
Moving beyond the research lab, embedded vision is rapidly augmenting traditional law enforcement techniques in real world surveillance settings. Technological gaps are rapidly being surmounted as automated surveillance systems' various hardware and software components become richer in their feature sets, higher in performance, more power efficient, and lower priced.
By Brian Dipert
Editor-in-Chief
Embedded Vision Alliance
Jacob Jose
IP Camera Product Marketing Manager
Texas Instruments
and Darnell Moore
Senior Member of the Technical Staff, Embedded Vision Team
Texas Instruments
Recent events showcase both the tantalizing potential and the current underwhelming reality of automated surveillance technology. Consider, for example, the terrorist bombing at the finish line of the April 15, 2013 Boston Marathon. Bolyston Street was full of cameras, both those permanently installed by law enforcement organizations and businesses, and those carried by race spectators and participants. But none of them was able to detect the impending threat represented by the intentionally abandoned backpacks, each containing a pressure cooker-implemented bomb, with sufficient advance notice to prevent the tragedy. And the resultant flood of video footage was predominantly analyzed by the eyes of the police department and FBI representatives attempting to identify and locate the perpetrators, due to both the slow speed and low accuracy of the alternative computer-based image analysis algorithms.
Consider, too, the ongoing military presence in Afghanistan and elsewhere, as well as the ongoing threat to U.S. embassies and other facilities around the world. Only a limited number of human surveillance personnel are available to look out for terrorist activities such as the installation of IEDs (improvised explosive devices) and other ordinances, the congregation and movement of enemy forces, and the like. And these human surveillance assets are further hampered by fundamental human shortcomings such as distraction and fatigue.
Computers, on the other hand, don't get sidetracked, and they don't need sleep. More generally, an abundance of ongoing case studies, domestic and international alike, provide ideal opportunities to harness the tireless analysis assistance that computer vision processing can deliver. Automated analytics algorithms are conceptually able, for example, to sift through an abundance of security camera footage in order to pinpoint an object left at a scene and containing an explosive device, cash, contraband or other contents of interest to investigators. And after capturing facial features and other details of the person(s) who left the object, analytics algorithms can conceptually also index image databases both public (Facebook, Google Image Search, etc.) and private (CIA, FBI, etc.) in order to rapidly identify the suspect(s).
Unfortunately, left-object, facial recognition and other related technologies haven't historically been sufficiently mature to be relied upon with high confidence, especially in non-ideal usage settings, such as when individuals aren't looking directly at the lens or are obscured by shadows or other challenging lighting conditions. As a result, human eyes and brains were traditionally relied upon for video analysis instead of computer code, thereby delaying suspect identification and pursuit, as well as increasingly the possibility of error (false positives, missed opportunities, etc). Such automated surveillance technology shortcomings are rapidly being surmounted, however, as cameras (and the image sensors contained within them) become more feature-rich, as the processors analyzing the video outputs similarly increase in performance, and as the associated software therefore becomes more robust.
As these and other key system building blocks such as memory devices also decrease in cost and power consumption, opportunities for surveillance applications are rapidly expanding beyond traditional law enforcement into new markets such as business analytics and consumer-tailored surveillance systems, as well as smart building and smart city initiatives. To facilitate these trends, an alliance of hardware and software component suppliers, product manufacturers, and system integrators has emerged to accelerate the availability and adoption of intelligent surveillance systems and other embedded vision processing opportunities.
How do artificial intelligence and embedded vision processing intersect? Answering this question begins with a few definitions. Computer vision is a broad, interdisciplinary field that attempts to extract useful information from visual inputs, by analyzing images and other raw sensor data. The term "embedded vision" refers to the use of computer vision in embedded systems, mobile devices, PCs and the cloud. Historically, image analysis techniques have typically only been implemented in complex and expensive, therefore niche, surveillance systems. However, the previously mentioned cost, performance and power consumption advances are now paving the way for the proliferation of embedded vision into diverse surveillance and other applications.
Automated Surveillance Capabilities
In recent years, digital equipment has rapidly entered the surveillance industry, which was previously dominated by analog cameras and tape recorders. Networked digital cameras, video recorders and servers have not only improved in quality and utility, but they have also become more affordable. Vision processing has added artificial intelligence to surveillance networks, enabling “aware” systems that help protect property, manage the flow of traffic, and even improve operational efficiency in retail stores. In fact, vision processing is helping to fundamentally change how the industry operates, allowing it to deploy people and other resources more intelligently while expanding and enhancing situational awareness. At the heart of these capabilities are vision algorithms and applications, commonly referred to as video analytics, which vary broadly in definition, sophistication, and implementation (Figure 1).
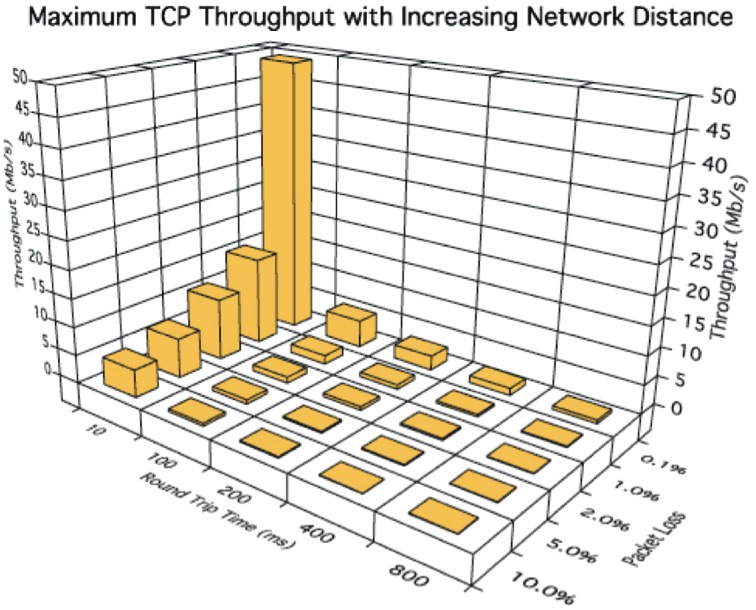
Figure 1. Video analytics is a broad application category referencing numerous image analysis functions, varying in definition, sophistication, and implementation.
Motion detection, as its name implies, allows surveillance equipment to automatically signal an alert when frame-to-frame video changes are noted. As one of the most useful automated surveillance capabilities, motion detection is widely available, even in entry-level digital cameras and video recorders. A historically popular technique to detect motion relies on codecs' motion vectors, a byproduct of the motion estimation employed by video compression standards such as MPEG-2 and H.264. Because these standards are frequently hardware-accelerated, scene change detection using motion vectors can be efficiently implemented even on modest IP camera processors, needing no additional computing power. However, this technique is susceptible to generating false alarms, because motion vector changes do not always coincide with motion from objects of interest. It can be difficult-to-impossible, using only the motion vector technique, to ignore unimportant changes such as trees moving in the wind or casting shifting shadows, or to adapt to changing lighting conditions.
These annoying "false positives" have unfortunately contributed to the perception that motion detection algorithms are unreliable. To wit, and to prevent vision systems from undermining their own utility, installers often insist on observing fewer than five false alarms per day. Nowadays, however, an increasing percentage of systems are adopting intelligent motion detection algorithms that apply adaptive background modeling along with other techniques to help identify objects with much higher accuracy levels, while ignoring meaningless motion artifacts. While there are no universal industry standards regulating accuracy, systems using these more sophisticated methods even with conventional 2-D cameras regularly achieve detection precision approaching 90 percent for typical surveillance scenes, i.e. those with those adequate lighting and limited background clutter. Even under more challenging environmental conditions, such as poor or wildly fluctuating lighting, precipitation-induced substantial image degradation, or heavy camera vibration, accuracy can still be near 70 percent. And the more advanced 3-D cameras discussed later in this article can boost accuracy higher still.
The capacity to accurately detect motion has spawned several related event-based applications, such as object counting andtrip zone. As the name implies, counting tallies the number of moving objects crossing a user-defined imaginary line, while tripping flags an event each time an object moves from a defined zone to an adjacent zone. Other common applications include loitering, which identifies when objects linger too long, and object left-behind/removed,which searches for the appearance of unknown articles, or the disappearance of designated items.
Robust artificial intelligence often requires layers of advanced vision know-how, from low-level imaging processing to high-level behavioral or domain models. As an example, consider a demanding application such as traffic and parking lot monitoring, which maintains a record of vehicles passing through a scene. It is often necessary to first deploy image stabilization and other compensation techniques to retard the effects of extreme environmental conditions such as dynamic lighting and weather. Compute-intensive pixel-level processing is also required to perform background modeling and foreground segmentation.
To equip systems with scene understanding sufficient to identify vehicles in addition to traffic lanes and direction, additional system competencies handle feature extraction, object detection, object classification (i.e. car, truck, pedestrians, etc.), and long-term tracking. LPR (license plate recognition) algorithms and other techniques locate license plates on vehicles and discern individual license plate characters. Some systems also collect metadata information about vehicles, such as color, speed, direction, and size, which can then be streamed or archived in order to enhance subsequent forensic searches.
Algorithm Implementation Options
Traditionally, analytics systems were based on PC servers, with surveillance algorithms running on x86 CPUs. However, with the introduction of high-end vision processors, all image analysis steps (including the previously mentioned traffic systems) can now optionally be entirely performed in dedicated-function equipment. Embedded systems based on DSPs (digital signal processors), application SoCs (system-on-chips), GPUs (graphics processors), FPGAs (field programmable logic devices) and other processor types are now entering the mainstream, primarily driven by their ability to achieve comparable vision processing performance to that of x86-based systems, at lower cost and power consumption.
Standalone cameras and analytics DVRs (digital video recorders) and NVRs (networked video recorders) increasingly rely on embedded vision processing. Large remote monitoring systems, on the other hand, are still fundamentally based on one or more cloud servers that can aggregate and simultaneously analyze numerous video feeds. However, even emerging "cloud" infrastructure systems are beginning to adopt embedded solutions, in order to more easily address performance, power consumption, cost and other requirements. Embedded vision coprocessors can assist in building scalable systems, offering higher net performance in part by redistributing processing capabilities away from the central server core and toward cameras at the edge of the network.
Semiconductor vendors offer numerous devices for different segments of the embedded cloud analytics market. These ICs can be used on vision processing acceleration cards that go into the PCI Express slot of a desktop server, for example, or to build standalone embedded products (Figure 2). Many infrastructure systems receive compressed H.264 videos from IP cameras and decompress the image streams before analyzing them. Repeated "lossy" video compression and decompression results in information discard that may be sufficient to reduce the accuracy of certain video analytics algorithms. Networked cameras with local vision processing "intelligence," on the other hand, have direct access to raw video data and can analyze and respond to events with low latency (Figure 3).



Figure 2. Modern vision processing "engines" can implement standalone surveillance cameras (top) and embedded analysis systems (middle); alternatively, they can find use on processing acceleration add-in cards for conventional servers (bottom).
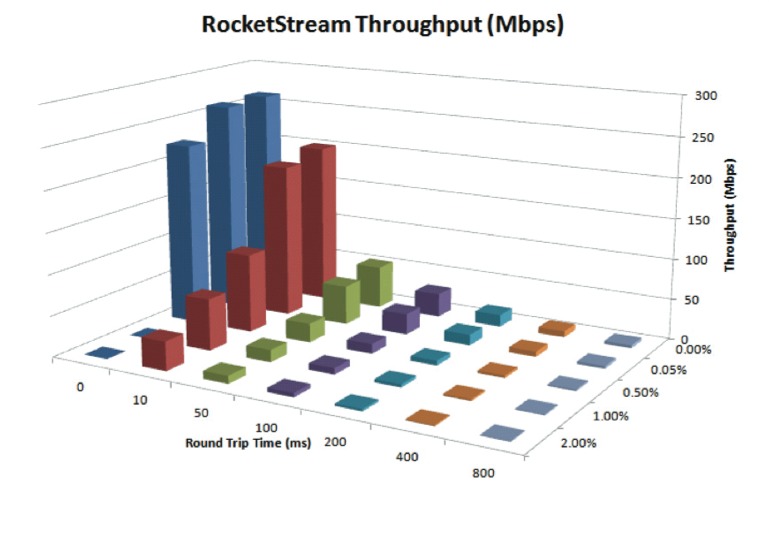
Figure 3, In distributed intelligence surveillance systems, networked cameras with local vision processing capabilities have direct access to raw video data and can rapidly analyze and respond to events.
Although the evolution to an architecture based on distributed intelligence is driving the proliferation of increasingly autonomous networked cameras, complex algorithms often still run on infrastructure servers. Networked cameras are commonly powered by Power Over Ethernet (PoE) and therefore have a very limited power budget. Further, the lower the power consumption, the smaller and less conspicuous the camera be. To quantify the capabilities of modern semiconductor devices, consider that an ARM Cortex-A9-based camera consumes only 1.8W in its entirety, while compressing H.264 video at 1080p30 (1920×1080 pixels per frame, 30 frames per second) resolution.
It's relatively easy to recompile PC-originated analytics software to run on an ARM processor, for example. However, as the clock frequency of a host CPU increases, the resultant camera power consumption also increases significantly as compared to running some-to-all of the algorithm on a more efficient DSP, FPGA or GPU. Harnessing a dedicated vision coprocessor will reduce the power consumption even more. And further assisting software development, a variety of computer vision software libraries is available. Some algorithms, such as those found in OpenCV (the Open Source Computer Vision Library), are cross-platform, while others, such as Texas Instruments' IMGLIB (the Image and Video Processing Library), VLIB (the Video Analytics and Vision Library) and VICP (the Video and Imaging Coprocessor Signal Processing Library), are vendor-proprietary. Leveraging pre-existing code speeds time to market, and to the extent that it exploits on-chip vision acceleration resources, it can also produce much higher performance results than those attainable with generic software (Figure 4).
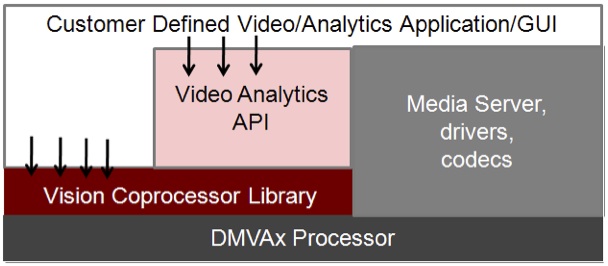
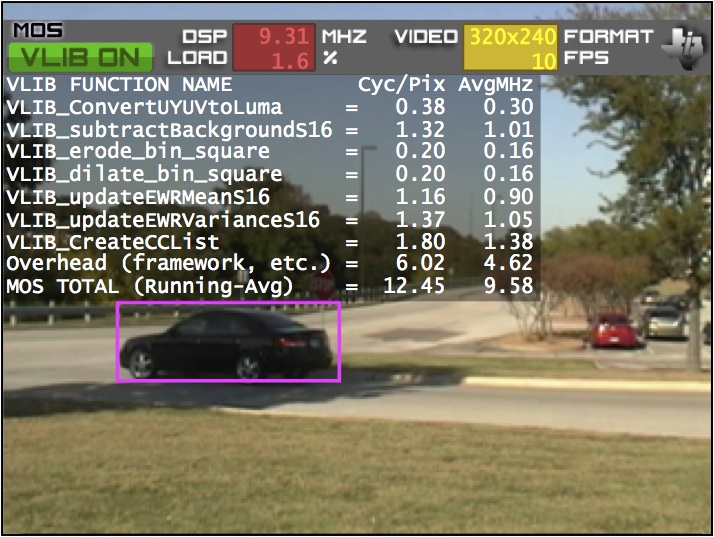
Figure 4. Vision software libraries can speed a surveillance system's time to market (top) as well as notably boost its frame rate and other attributes (bottom).
Historical Trends and Future Forecasts
As previously mentioned, embedded vision processing is one of the key technologies responsible for evolving surveillance systems beyond their archaic CCTV (closed-circuit television) origins and into the modern realm of enhanced situational awareness and intelligent analytics. For most of the last century, surveillance required people, sometimes lots of them, to effectively patrol property and monitor screens and access controls. In the 1990’s, DSPs and image processing ASICs (application-specific integrated circuits) helped the surveillance industry capture image content in digital form using frame grabbers and video cards. Coinciding with the emergence of high-speed networks for distributing and archiving data at scales that had been impossible before, surveillance providers embraced computer vision technology as a means of helping manageand interpret the deluge of video content now being collected.
Initial vision applications such as motion detection sought to draw the attention of on-duty surveillance personnel, or to trigger recording for later forensic analysis. Early in-camera implementations were usually elementary, using simple DSP algorithms to detect gross changes in grayscale video, while those relying on PC servers for processing generally deployed more sophisticated detection and tracking algorithms. Over the years, however, embedded vision applications have substantially narrowed the performance gap with servers, benefiting from more capable function-tailored processors. Each processor generation has integrated more potent discrete components, including multiple powerful general computing cores as well as dedicated image and vision accelerators.
As a result of these innovations, the modern portfolio of embedded vision capabilities is constantly expanding. And these expanded capabilities are appearing in an ever-wider assortment of cameras, featuring multi-megapixel CMOS sensors with wide dynamic range and/or thermal imagers, and designed for every imaginable installation requirement, including dome, bullet, hidden/concealed, vandal-proof, night vision, pan-tilt-zoom, low light, and wirelessly networked devices. Installing vision-enabled cameras at the ‘edge’ has reduced the need for expensive centralized PCs and backend equipment, lowering the implementation cost sufficient to place these systems in reach of broader market segments, including retail, small business, and residential.
The future is bright for embedded vision systems. Sensors capable of discerning and recovering 3-D depth data, such as stereo vision, TOF (time-of-flight), and structured light technologies, are increasingly appearing in surveillance applications, promising significantly more reliable and detailed analytics. 3-D techniques can be extremely useful when classifying or modeling detected objects while ignoring shadows and illumination artifacts, addressing a problem that has long plagued conventional 2-D vision systems. In fact, systems leveraging 3-D information can deliver detection accuracies above 90 percent, even for highly complex scenes, while maintaining a minimal false detection rate (Figure 5).

Figure 5. 3-D cameras are effective in optimizing detection accuracy, by enabling algorithms to filter out shadows and other traditional interference sources.
However, these 3-D technology advantages come with associated tradeoffs that also must be considered. For example, stereo vision, which uses geometric “triangulation” to estimate scene depth, is a passive, low-power approach to depth recovery which is generally less expensive than other techniques and can be used at longer camera-to-object distances, at the tradeoff of reduced accuracy (Figure 6). TOF, on the other hand, is an active, higher-power sensor that generally offers more detail, but at higher cost and with a shorter operating range. Both approaches, along with structured light and other candidates, can be used for detection. But the optimum technology for a particular application can only be fully understood after prototyping (Figure 7).



Figure 6. The stereo vision technique uses a pair of cameras, reminiscent of a human's left- (top) and right-eye perspectives (middle), to estimate the depths of various objects in a scene (bottom).
Figure 7. Although the depth map generated by a TOF (time-of-flight) 3-D sensor is more dense than its stereo vision-created disparity map counterpart, with virtually no coverage "holes" and therefore greater accuracy in the TOF case, stereo vision systems tend to be lower power, lower cost and usable over longer distances.
As new video compression standards such as H.265 become established, embedded vision surveillance systems will need to process even larger video formats (4k x 2k and beyond), which will compel designers to harness hardware processor combinations that may include some or all of the following: CPUs, multi-core DSPs, FPGAs, GPUs, and dedicated accelerators. Addressing often-contending embedded system complexity, cost, power, and performance requirements will likely lead to more distributed vision processing, whereby rich object and feature metadata extracted at the edge can be further processed, modeled, and shared “in the cloud.” And the prospect of more advanced compute engines will enable state-of-the-art vision algorithms, including optical flow and machine learning.
The Embedded Vision Alliance and Embedded Vision Summit
Embedded vision technology has the potential to enable a wide range of electronic products, such as the surveillance systems discussed in this article, that are more intelligent and responsive than before, and thus more valuable to users. It can add helpful features to existing products. And it can provide significant new markets for hardware, software and semiconductor manufacturers. The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower engineers to transform this potential into reality. Texas Instruments, the co-author of this article, is a member of the Embedded Vision Alliance. For more information about the Embedded Vision Alliance, please see this Embedded.com article.
On Tuesday, May 12, 2015, in Santa Clara, California, the Alliance will hold its next Embedded Vision Summit. Embedded Vision Summits are technical educational forums for hardware and software product creators interested in incorporating visual intelligence into electronic systems. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Alliance member companies. These events are intended to:
- Inspire product creators' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations.
- Offer practical know-how to help them incorporate vision capabilities into their products, and
- Provide opportunities for engineers to meet and talk with leading vision technology companies and learn about their offerings.
Please visit the event page for more information on the Embedded Vision Summit.
Biographies:
Brian Dipert is Editor-In-Chief of the Embedded Vision Alliance. He is also a Senior Analyst at BDTI (Berkeley Design Technology, Inc.), and Editor-In-Chief of InsideDSP, the company's online newsletter dedicated to digital signal processing technology. He has a B.S. degree in Electrical Engineering from Purdue University in West Lafayette, IN. His professional career began at Magnavox Electronics Systems in Fort Wayne, IN; Brian subsequently spent eight years at Intel Corporation in Folsom, CA. He then spent 14 years (and five months) at EDN Magazine.
Jacob Jose is a Product Marketing Manager with Texas Instruments’ IP Camera business. He joined Texas Instruments in 2001, has engineering and business expertise in the imaging, video and analytics markets, and has worked at locations in China, Taiwan, South Korea, Japan, India and the USA. He has a Bachelors degree in computer science and engineering from the National Institute of Technology at Calicut, India and is currently enrolled in the executive MBA program at Kellogg School of Business, Chicago, Ilinois.
Darnell Moore, Ph.D., is a Senior Member of the Technical Staff with Texas Instruments’ Embedded Processing Systems Lab. As an expert in vision, video, imaging, and optimization, his body of work includes Smart Analytics, a suite of vision applications that spawned TI’s DMVA processor family, as well as advanced vision prototypes, such as TI’s first stereo IP surveillance camera. He received a BSEE from Northwestern University and a Ph.D. from the Georgia Institute of Technology.