| LETTER FROM THE EDITOR |
|
Dear Colleague,
The Embedded Vision Summit is the most important industry event for innovators developing and deploying products using computer vision. Next year’s Summit will take place May 1-3, 2017 in Santa Clara, California. We are assembling the presentation program and have a limited number of presentation opportunities. We are looking for insightful presentations that dig deep into the practical how-to of computer vision product development, trends and opportunities across all types of applications – cloud, embedded, wearables, mobile and PC.
We welcome presentation proposals on end-products using computer vision, practical development techniques, business insights and enabling technologies. Summit presentation proposals will be reviewed as they arrive, and Summit presentation slots are limited, so submit your proposal as soon as possible!
Presentation proposals are evaluated on a rolling basis throughout the year. To maximize the chances of your proposal being accepted, submit it early and follow the instructions below.
Please submit the following information via email to [email protected]:
- Company name, speaker name, job title, photo and brief bio (<150 words).
- Presentation title.
- Description of target audience (job function, experience level).
- Purpose: What will the audience gain from this talk? (<25 words).
- Abstract: Describe the scope and depth of the talk, including key examples to be used (<150 words).
- Optional: a link to a video or audio recording of a past talk you’ve presented
If you have any questions, please email [email protected]. Thank you again for your support of the Embedded Vision Summit!
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
| FEATURED VIDEOS |
|
"Designing and Selecting Instruction Sets for Vision," a Presentation From Cadence
Two critical technical trends have reached important inflection points: the massive compute demands of vision processing and the capabilities of specialized vision processors. But what how do you actually select (or even build) a better vision processor? This talk from Chris Rowen, Fellow at Cadence, serves as a step-by-step tutorial on how to dissect a suite of applications, extract the key computational and memory requirements, and determine priorities for processor instruction set and memory organization for optimal vision processing. Rowen walks through large scale application profiling, does data type analysis, outlines selection of operations, examines tradeoffs in SIMD, VLIW and specialized execution units, and drills down on resource constraints that impact power, energy, cost, memory system demands and programming flexibility. He takes a set of real-world applications from ADAS, deep neural network image recognition, and multi-frame imaging as targets and illustrates the process for assessing and selecting vision processors.
Basler's Thies Moeller Explains Time-of-Flight Cameras
Factory automation, robotics and logistics are often used in applications where 3D image data can effectively supplement 2D data. A Time-of-Flight (ToF) camera delivers not just 2D data but also the necessary depth data. In this Vision Campus video, Basler's Thies Moeller explains how a ToF camera functions. He also describes the benefits inherent to this camera, as well as the influencing factors that can diminish the effectiveness of a ToF camera.
More Videos
|
| FEATURED ARTICLES |
|
Deep Learning with INT8 Optimization on Xilinx Devices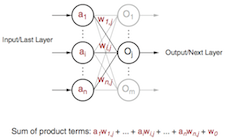
This technical article from Xilinx explores INT8 deep learning operations implemented on the company's DSP48E2 slice, and how this implementation contrasts with that on other FPGAs. With INT8, Xilinx's DSP architecture can achieve 1.75X peak solution-level performance at INT8 deep learning operation per second (OPS) compared to other FPGAs with the same resource count. As deep learning inference exploits lower bit precision without sacrificing accuracy, efficient INT8 implementations are needed. Xilinx's DSP architecture and libraries are optimized for INT8 deep learning inference. This article describes how the DSP48E2 slice in Xilinx's UltraScale and UltraScale+ FPGAs can be used to process two concurrent INT8 multiply and accumulate (MACC) operations while sharing the same kernel weights. It also explains why 24-bit is the minimal size for an input to utilize this technique. The article also includes an example of this INT8 optimization technique to show its relevance by revisiting the fundamental operations of neural networks. More
What Hand-Eye Coordination Tells Us About Computer Vision
"For humans," writes Embedded Vision Alliance founder Jeff Bier in this blog post, "it goes without saying that vision is extremely valuable. When you stop to think about it, it's remarkable what a diverse set of capabilities is enabled by human vision – from reading facial expressions, to navigating complex three-dimensional spaces, to performing intricate tasks like threading a needle. One of the reasons why I'm so excited about the potential of computer vision is that I believe that it will bring a similar range of diverse and valuable capabilities to many types of devices and systems. In the past, computer vision required too much computation to be deployed widely. But today, sufficient processing power is available at cost and power consumption levels suitable for high-volume products. As a result, computer vision is proliferating into thousands of products. The vast range of diverse capabilities enabled by vision, coupled with the wide range of potential applications, can be daunting. How do we figure out which of these capabilities and applications are really worthwhile, and which are mere novelties? I think the analogy with biological vision can help." More
More Articles
|
| FEATURED BOOKS |
|
ARM Guide to OpenCL Optimizing Canny Edge Detection
This technical reference manual, provided by the Embedded Vision Alliance in partnership with ARM and now published in full on the Alliance website, provides advice and information for software developers who want to leverage all available hardware in platforms implementing computer vision. Specifically, it provides an example optimization process for accelerating the performance of Canny edge detection operations using an ARM Mali Midgard GPU; the principles in this guide can also be applied to other computer vision tasks. More
More Books
|
| UPCOMING INDUSTRY EVENTS |
|
Xilinx Webinar Series – Vision with Precision: Augmented Reality: December 6, 2016, 10 am PT
Embedded World Conference: March 14-16, 2017, Messezentrum Nuremberg, Germany
Embedded Vision Summit: May 1-3, 2017, Santa Clara, California
More Events
|
| FEATURED NEWS |
|
Intel Unveils Strategy for State-of-the-Art Artificial Intelligence
DJI Raises Bar for Aerial Imaging with Two New Flying Cameras
AImotive Introduces Level 5 Self-Driving Automotive Technology Powered By Artificial Intelligence To U.S. Market
Videantis Wins Second Deloitte Technology Fast 50 Award, Fueled by Rapid Growth in Automotive
Tessera Technologies Acquires Technology Assets from Pelican Imaging Corporation
More News
|
