This article was originally published at Imagination Technologies' website, where it is one of a series of articles. It is reprinted here with the permission of Imagination Technologies.
In a previous article we described our PowerVR Imaging Framework, a set of extensions to the OpenCL and EGL APIs that enable efficient zero-copy sharing of memory between a PowerVR GPU and other system components such as a CPU, ISP and VDE.
Most flows use EGL to facilitate the sharing of objects between multiple client APIs, requiring the Khronos extension CL_KHR_EGL_IMAGE. The examples below show the different zero-copy flows supported inside the PowerVR Imaging Framework.
GPU sampling of native YUV semi-planar image
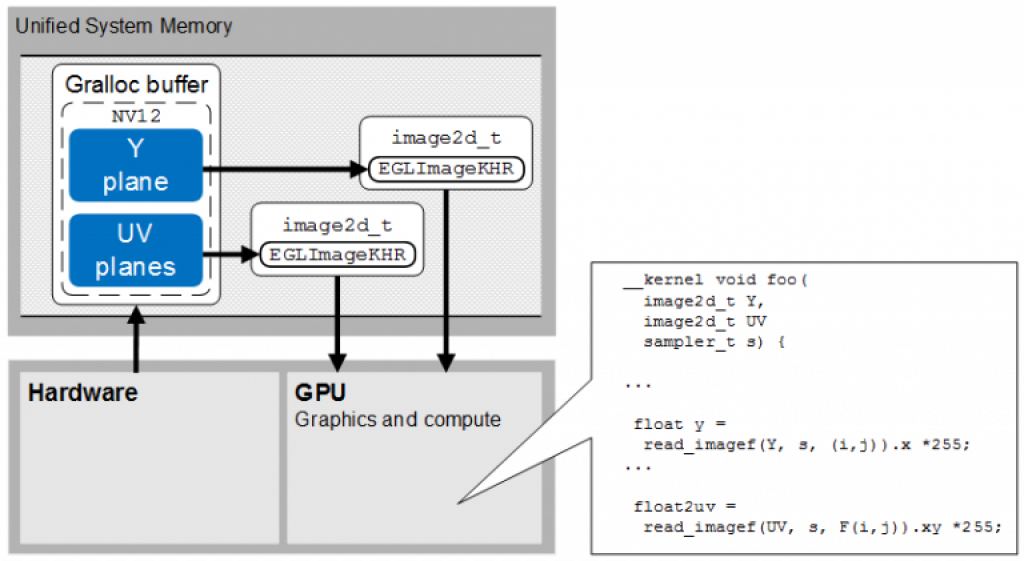
The figure below shows a configuration where one hardware component writes a YUV semi-planar image to memory, using an Android gralloc buffer, and the GPU samples the luminance and chrominance values directly.

The host code should call eglCreateImageKHR two times to instantiate two EGL Images from the Gralloc buffer, passing the option EGL_NATIVE_BUFFER_MULTIPLANE_SEPARATE_IMG and CL_NATIVE_BUFFER_PLANE_OFFSET_IMG with values of 0 (for the Y plane) and 1 (for the UV plane). The host should then call clCreateFromEGLImageKHR to instantiate two OpenCL Images (of type image2d_t).
The OpenCL kernel should call read_imagef (or read_imagei) on these two images to sample pixel values. Sampling the first image returns a variable with type float4 where the first channel contains an element with type CL_UNORM_INT8. Sampling the second image returns a variable with type float4 where the first two channels contain elements of type CL_UNORM_INT8.
The platform must support the extensions OES_EGL_image_external and EGL_IMG_image_plane_attribs.
GPU sampling of native YUV planar image
The figure below shows a configuration where one hardware component writes a YUV planar image to memory, using an Android gralloc buffer, and the GPU samples the luminance and chrominance values directly.

The host code should call eglCreateImageKHR three times instantiate three EGL Images from the Gralloc buffer, passing the option EGL_NATIVE_BUFFER_MULTIPLANE_SEPARATE_IMG and CL_NATIVE_BUFFER_PLANE_OFFSET_IMG with values of 0 (for the Y plane), 1 (for the U plane) and 2 (for the V plane). The host should then call clCreateFromEGLImageKHR to instantiate three OpenCL Images (of type image2d_t).
The OpenCL kernel should call read_imagef (or read_imagei) on these three images to sample pixel values. Sampling each image returns a variable with type float4 where the first channel contains an element with type CL_UNORM_INT8.
The platform must support the extensions OES_EGL_image_external and EGL_IMG_image_plane_attribs.
GPU sampling of YUV image for processing as RGB
The diagram below shows a configuration where one hardware component writes a YUV semi-planar image to memory, using an Android gralloc buffer, and the GPU samples the data as RGB. The Rogue hardware (TPU block) automatically converts sampled YUV data to RGB on-the-fly.

The host code should call eglCreateImageKHR to instantiate an EGL Image, passing no additional flags to the attribute list and having enabled the extension CL_IMG_YUV_image. The host should then call clCreateFromEGLImageKHR to instantiate an OpenCL Image (of type image2d_t).
The OpenCL kernel should call read_imagef (or read_imagei) on this image to sample pixel values. Sampling the image returns a variable with type float4 RGB. During sampling, the hardware performs the necessary colour-space conversion.
The platform must support the extensions OES_EGL_image_external and CL_IMG_YUV_image. The supported YUV formats are listed in the following table.
| Format | Description | |
| NV12 | 4:2:0 8-bit | Semi-planar u/v |
| NV21 | 4:2:0 8-bit | Semi-planar v/u |
| YV12 | 4:2:0 8-bit | Planar Y/V/U |
| I420 | 4:2:0 8-bit | Planar Y/U/V |
GPU sampling from Android Camera HAL
The examples in the previous sections show how to configure the GPU to directly sample individual images output by hardware, for example as required when interfacing directly to a camera or video driver through the associated Android HAL (Hardware Abstraction Layer). Android provides a BufferQueue API to support camera and video streaming applications. The figure below shows a configuration where one hardware component streams a sequence of images to memory, using an Android BufferQueue, and the GPU reads images from this queue.

The BufferQueue API provides both producer and consumer interfaces. The host code should first initialize the hardware (camera or video decoder) and pass the associated handle to the BufferQueue producer interface. It should then start streaming images from the hardware, using the consumer interface to obtain the next Gralloc buffer for processing. It should use the OpenCL and EGL extensions explained in the previous sections to create image2d_t objects that can by sampled from OpenCL on the GPU.
Google defines the Android BufferQueue API as private, and does not expose it in either the Android SDK or NDK. Therefore, to enable this level of integration, the platform vendor should either enable access to this API or provide an alternative interface that utilizes this API internally.
Sharing OpenCL buffer between CPU and GPU
PowerVR Rogue devices are capable of allocating memory, which can also be mapped and shared with a CPU. However, Rogue devices are currently unable to map arbitrary host-allocated CPU memory into the GPU. Therefore, to share memory objects between the CPU and GPU, the host should create the objects using the flag CL_ALLOC_HOST_PTR flag and access using the mapping functions clEnqueueMapBuffer or clEnqueueMapImage, and clEnqueueUnmapMemObject.
The figure below shows how ownership of CPU-allocated buffers is passed to the GPU. First, the host program allocates and initialises some data which is held in two pages of CPU-allocated memory. It then calls clCreateBuffer, passing a pointer to this data and the CL_USE_HOST_PTR.

In general, these pages of data may not be addressable by the GPU, and even if the GPU can address the pages, the CPU may be free to swap the pages out to disk when other pages in virtual memory are required. Therefore, when the host program enqueues a kernel that operates on this data, the driver first allocates a block of memory in GPU-allocated memory, and creates a duplicate copy of the data prior to running the kernel. This copy operation incurs a bandwidth cost every time data is transferred between the host and device, which can significantly reduce performance but is needed to ensure correct operation of the program. For example, the diagram below shows the situation where during execution of the kernel the OS running on the CPU swaps out pages some of the originally-allocated memory to disk.

Here we are showing the alternate situation in which the host program allocates the buffer originally in GPU-allocated memory. First, the host program calls clCreateBuffer with the flag CL_USE_HOST_PTR, which allocates some data in two page of GPU-allocated memory. It then initialises this data.

OpenCL map and unmap functions are used to pass ownership of the buffer between the CPU and GPU. By default the buffer is cached by the GPU and uncached by the CPU. This means that the map operation performed by the host has a cost associated with flushing the GPU cache but an unmap operation has no cost.
To create an OpenCL buffer which is CPU-cached, call the function clCreateBuffer with the flag CL_IMG_USE_CACHED_CPU_MEMORY_IMG. In general, CPU-cached buffers are useful when the CPU needs to read data output by GPU, and CPU-uncached buffers are useful when, for example, the output buffer is an image to be rendered by the GPU to the display.
By Salvatore De Dominicis
Leading Technical Specialist on OpenCL and GPU Compute, Imagination Technologies