This article was originally published at the 2017 Embedded World Conference.
With the emergence of increasingly capable processors, image sensors, and algorithms, it's becoming practical to incorporate computer vision capabilities into a wide range of systems, enabling them to analyze their environments via video inputs. This article explores the opportunity for embedded vision, compares various processor and algorithm options for implementing embedded vision, and introduces an industry alliance created to help engineers incorporate vision capabilities into their designs.
Introduction
Vision technology is now enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Such image perception, understanding, and decision-making processes have historically been achievable only using large, expensive, and power-hungry computers and cameras. Thus, computer vision has long been restricted to academic research and low-volume applications.
However, thanks to the emergence of increasingly capable and cost-effective processors, image sensors, memories and other semiconductor devices, along with robust algorithms, it's now practical to incorporate computer vision into a wide range of systems. The Embedded Vision Alliance uses the term "embedded vision" to refer to this growing use of practical computer vision technology in embedded systems, mobile devices, PCs, and the cloud.
Similar to the way that wireless communication has now become pervasive, embedded vision technology is poised to be widely deployed in the coming years. Advances in digital integrated circuits were critical in enabling high-speed wireless technology to evolve from exotic to mainstream. When chips got fast enough, inexpensive enough, and energy efficient enough, high-speed wireless became a mass-market technology. Today one can buy a broadband wireless modem or a router for under $50.
Similarly, advances in digital chips are now paving the way for the proliferation of embedded vision into high-volume applications. Like wireless communication, embedded vision requires lots of processing power—particularly as applications increasingly adopt high-resolution cameras and make use of multiple cameras. Providing that processing power at a cost low enough to enable mass adoption is a big challenge.
This challenge is multiplied by the fact that embedded vision applications require a high degree of programmability. In contrast to wireless applications where standards mean that, for example, baseband algorithms don’t vary dramatically from one handset to another, in embedded vision applications there are great opportunities to get better results—and enable valuable features—through unique algorithms.
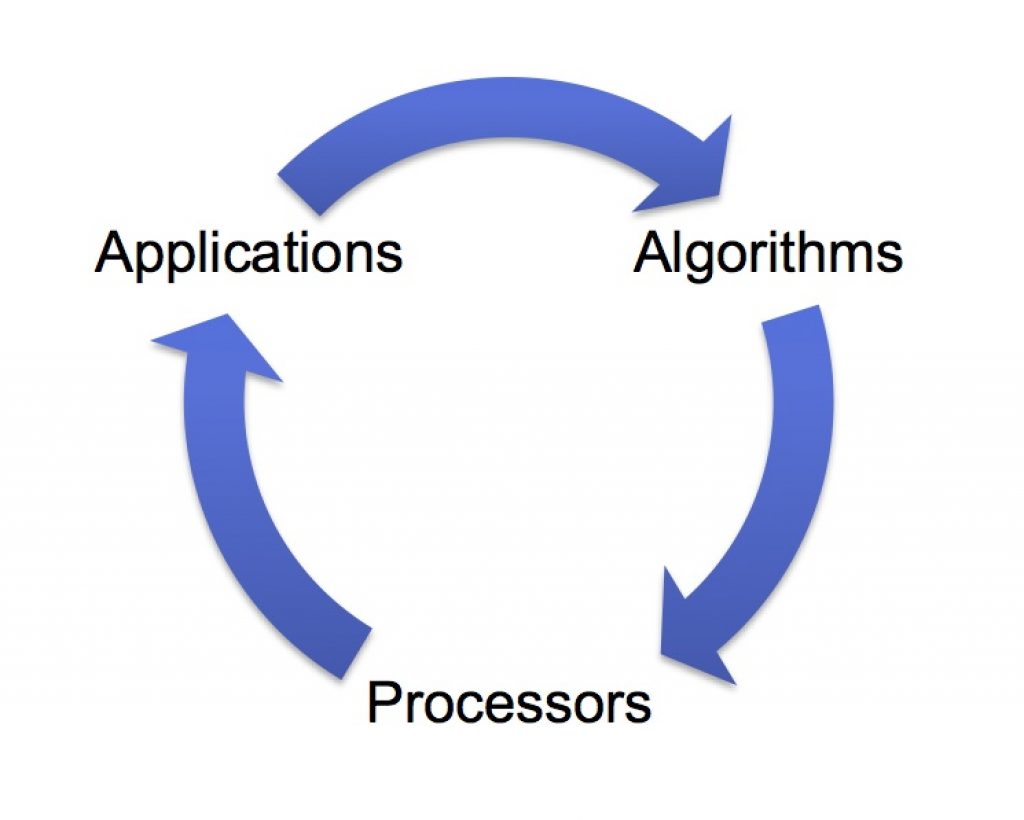
With embedded vision, the industry is entering a "virtuous circle" of the sort that has characterized many other digital signal processing application domains (Figure 1). Although there are few chips dedicated to embedded vision applications today, these applications are increasingly adopting high-performance, cost-effective processing chips developed for other applications. As these chips continue to deliver more programmable performance per dollar and per watt, they will enable the creation of more high-volume embedded vision end products. Those high-volume applications, in turn, will attract more investment from silicon providers, who will deliver even better performance, efficiency, and programmability – for example, by creating chips tailored for vision applications.
Figure 1. Embedded vision benefits from a "virtuous circle" positive feedback loop of investments both in the underlying technology and on applications.
Processing Options
As previously mentioned, vision algorithms typically require high compute performance. And, of course, embedded systems of all kinds are usually required to fit into tight cost and power consumption envelopes. In other application domains, such as digital wireless communications, chip designers achieve this challenging combination of high performance, low cost, and low power by using specialized accelerators to implement the most demanding processing tasks in the application. These coprocessors and accelerators are typically not programmable by the chip user, however.
This tradeoff is often acceptable in wireless applications, where standards mean that there is strong commonality among algorithms used by different equipment designers. In vision applications, however, there are no standards constraining the choice of algorithms. On the contrary, there are often many approaches to choose from to solve a particular vision problem. Therefore, vision algorithms are very diverse, and tend to change rapidly over time. As a result, the use of non-programmable accelerators and coprocessors is less attractive for vision applications compared to applications like digital wireless and compression-centric consumer video equipment.
Achieving the combination of high performance, low cost, low power, and programmability is challenging. Special-purpose hardware typically achieves high performance at low cost, but with limited programmability. General-purpose CPUs provide programmability, but with weak performance, poor cost-effectiveness, and/or low energy-efficiency. Demanding embedded vision applications most often use a combination of processing elements, which might include, for example:
- A general-purpose CPU for heuristics, complex decision-making, network access, user interface, storage management, and overall control
- A specialized, programmable co-processor for real-time, moderate-rate processing with moderately complex algorithms
- One or more fixed-function engines for pixel-rate processing with simple algorithms
Convolutional neural networks (CNNs) and other deep learning approaches for computer vision, which the next section of this article will discuss, tend to be very computationally demanding. As a result, they have not historically been deployed in cost- and power-sensitive applications. However, it's increasingly common today to implement CNNs, for example, using graphics processor cores and discrete GPU chips. And several suppliers have also recently introduced processors targeting computer vision applications, with an emphasis on CNNs.
Deep Learning Techniques
Traditionally, computer vision applications have relied on special-purpose algorithms that are painstakingly designed to recognize specific types of objects. Recently, however, CNNs and other deep learning approaches have been shown to be superior to traditional algorithms on a variety of image understanding tasks. In contrast to traditional algorithms, deep learning approaches are generalized learning algorithms that are trained through examples to recognize specific classes of objects.
Object recognition, for example, is typically implemented in traditional computer vision approaches using a feature extractor module and a classifier unit. The feature extractor is a hand-designed module, such as a Histogram of Gradients (HoG) or a Scale- Invariant Feature Transform (SIFT) detector, which is adapted to a specific application. The main task of the feature extractor is to generate a feature vector—a mathematical description of local characteristics in the input image. The task of the classifier is to project this multi-dimensional feature vector onto a plane and make a prediction regarding whether a given object type is present in the scene.
In contrast, with neural networks, the idea is to make the end-to-end object recognition system adaptive, with no distinction between the feature extractor and the classifier. Training the feature extractor, rather than hand-designing it, gives the system the ability to learn and recognize more- complex and non-linear features in objects which would otherwise be hard to model in a program. The complete network is trained from the input pixel stage all the way to the output classifier layer that generates class labels. All the parameters in the network are learned using a large set of training data. As learning progresses, the parameters are trained to extract relevant features of the objects the system is tasked to recognize. By adding more layers in the network, complex features are learned hierarchically from simple ones.
More generally, many real-world systems are difficult to model mathematically or programmatically. Complex pattern recognition, 3-D object recognition in a cluttered scene, detection of fraudulent activities on a credit card, speech recognition and prediction of weather and stock prices are examples of non-linear systems that involve solving for thousands of variables, or following a large number of weak rules to get to a solution, or "chasing a moving target" for a system that changes its rules over time.
Often, such as in recognition problems, we don’t have robust conceptual frameworks to guide our solutions because we don’t know how the brain does the job! The motivation for exploring machine learning comes from our desire to imitate the brain (Figure 2). Simply put, we want to collect a large number of examples that give the correct output for a given input, and then instead of writing a program, give these examples to a learning algorithm, and let the machine produce a program that does the job. If trained properly, the machine will subsequently operate correctly on previously unseen examples, a process known as "inference."
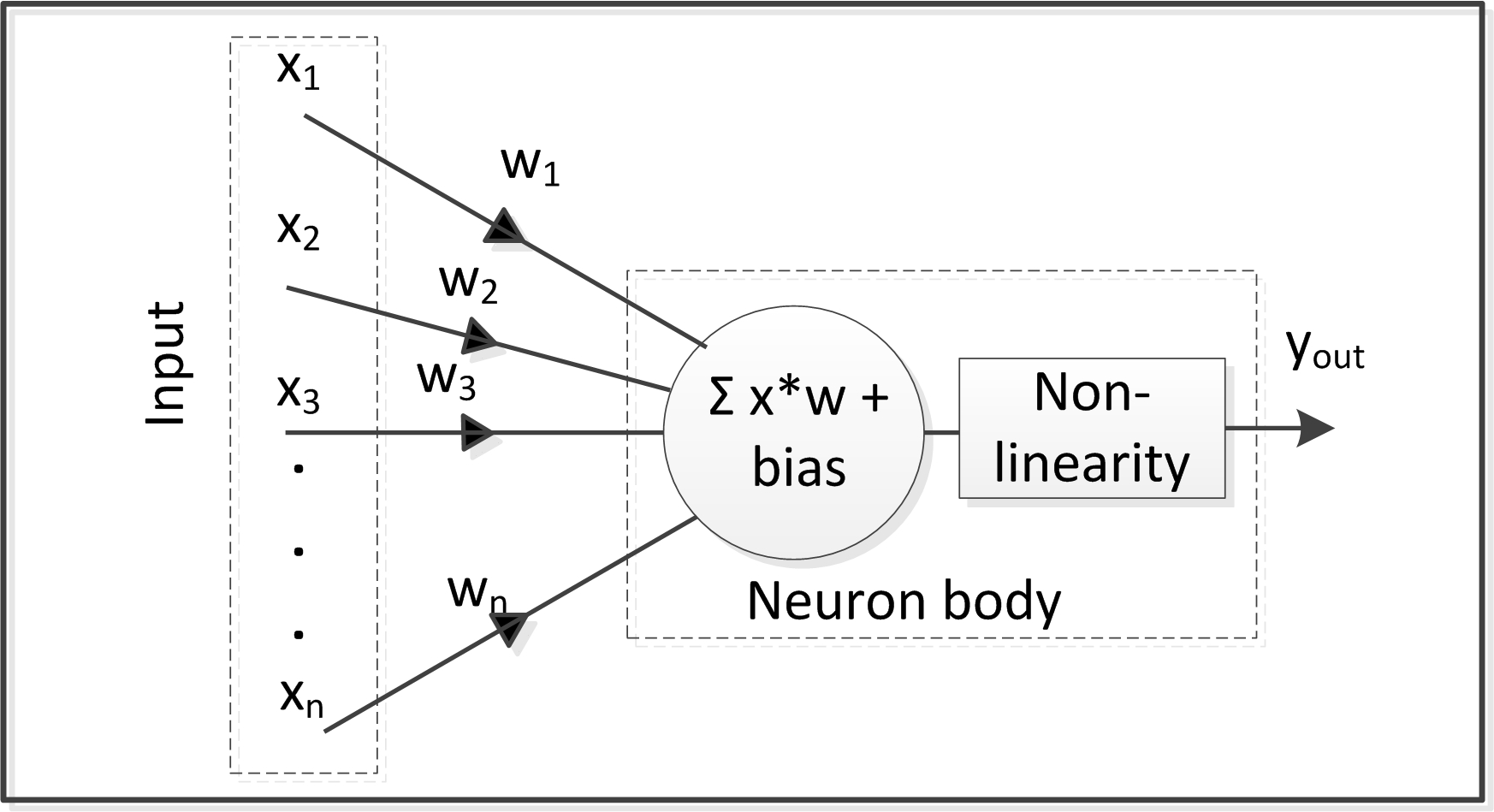
Figure 2. Inspired by biology, artificial neural networks attempt to model the operation of neuron cells in the human brain.
Open Standards
In the early stages of new technology availability and implementation, development tools tend to be company-proprietary. Examples include NVIDIA's CUDA toolset for developing computer vision and other applications that leverage the GPU as a heterogeneous coprocessor, and the company's associated CuDNN software library for accelerated deep learning training and inference operations (AMD's more recent equivalents for its own GPUs are ROCm and MIOpen).
As a technology such as embedded vision matures, however, additional development tool sets tend to emerge, which are more open and generic and support multiple suppliers and products. Although these successors may not be as thoroughly optimized for any particular architecture as are the proprietary tools, they offer several advantages; for example, they allow developers to create software that runs efficiently on processors from different suppliers.
One significant example of an open standard for computer vision is OpenCV, the Open Source Computer Vision Library. This collection of more than 2500 software components, representing both classic and emerging machine learning-based computer vision functions, was initially developed in proprietary fashion by Intel Research in the mid-1990s. Intel released OpenCV to the open source community in 2000, and ongoing development and distribution is now overseen by the OpenCV Foundation.
Another example of a key enabling resource for the practical deployment of computer vision technology is OpenCL, managed by the Khronos Group. An industry standard alternative to the proprietary and GPU-centric CUDA and ROCm mentioned previously, it is a maturing set of heterogenous programming languages and APIs that enable software developers to efficiently harness the profusion of diverse processing resources in modern SoCs, in an abundance of applications including embedded vision. It's joined by the HSA Foundation's various specifications, which encompass the standardization of memory coherency and other attributes requiring the implementation of specific hardware features in each heterogeneous computing node.
Then there's OpenVX, a recently introduced open standard managed by the Khronos Group. It was developed for the cross-platform acceleration of computer vision applications, prompted by the need for high performance and low power with diverse processors. OpenVX is specifically targeted at low-power, real-time applications, particularly those running on mobile and embedded platforms. The specification provides a way for developers to tap into the performance of processor-specific optimized code, while still providing code portability via the API's standardized interface and higher-level abstractions.
Numerous open standards are also appearing for emerging deep learning-based applications. Open-source frameworks include the popular Caffe, maintained by the U.C. Berkeley Vision and Learning Center, along with Theano and Torch. More recently, they've been joined by frameworks initially launched (and still maintained) by a single company but now open-sourced, such as Google's TensorFlow and Microsoft's Cognitive Toolkit (formerly known as CNTK). And for deep learning model training and testing, large databases, such as the ImageNet Project, containing more than ten million images, are available.
Industry Alliance Assistance
The Embedded Vision Alliance, a worldwide organization of technology suppliers, is working to empower product creators to transform the potential of embedded vision into reality. The Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Alliance maintains a website providing tutorial articles, videos, and a discussion forum staffed by technology experts. Registered website users can also receive the Alliance’s newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools. Access is free to all through a simple registration process.
The Embedded Vision Alliance’s annual technical conference and trade show, the Embedded Vision Summit, will be held May 1-3, 2017 at the Santa Clara, California Convention Center. Designed for product creators interested in incorporating visual intelligence into electronic systems and software, the Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Alliance member companies.
The Embedded Vision Summit is intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings. Online registration and additional information on the 2017 Embedded Vision Summit are now available.
Conclusion
With embedded vision, the industry is entering a "virtuous circle" of the sort that has characterized many other digital processing application domains. Embedded vision applications are adopting high-performance, cost-effective processor chips originally developed for other applications; ICs and cores tailored for embedded vision applications are also now becoming available. Deep learning approaches have been shown to be superior to traditional vision processing algorithms on a variety of image understanding tasks, expanding the range of applications for embedded vision. Open standard algorithm libraries, APIs, data sets and other toolset elements are simplifying the development of efficient computer vision software. The Embedded Vision Alliance believes that in the coming years, embedded vision will become ubiquitous, as a powerful and practical way to bring intelligence and autonomy to many types of devices.
By Jeff Bier
Founder, Embedded Vision Alliance