
With more than 1,200 attendees and over 90 presenters, the 2017 Embedded Vision Summit made one thing clear: I am not the only one who thinks that energy-efficient processors and simple-to-use software toolkits to utilize the available horse-power are critical for embedded vision. Jeff Bier made a compelling argument that cost and power consumption of vision computing will decrease by about 1000x over the next 3 years. He mentioned techniques like reducing data types and using software tools and frameworks to achieve significant improvements in resource usage and efficiency.
If you’ve been following any of CEVA’s bloggers, this should sound very familiar. This drastic reduction, even if it will be less than 1000x, will lead to ubiquitous embedded vision with a virtually unlimited variety of applications. The trend-setters of the industry are already putting the pieces on the board for when this happens. Here is a look at some of the action going on in the world of embedded vision.
Machine Learning, AI and Deep Learning Coming to Mobile Phones
Motorola is using machine learning to improve the camera quality in their mobile phones. One example is the ability to use a machine learning trained algorithm to increase accuracy to auto-trigger HDR feature on the phone. Per Motorola’s presentation at the Embedded Vision Summit, properly identifying the cases in which HDR is required, significantly increases the quality of the photos.

The importance of identifying when to use HDR (Credit: Motorola)
Another key player pushing AI to mobile is Facebook. They have adopted the widely used and open source deep learning Caffe framework and re-designed it to make deep learning portable from cloud to mobile. Subsequently, they open-sourced it as a new framework called Caffe2. Facebook also recently announced the Camera Effects Platform to bring augmented reality (AR) to over a billion users on their smartphones.
Facebook have also done some interesting things with camera software. A while ago I wrote a post about how dual cameras combined with deep learning were pushing the limits of smartphone photography towards DSLR-like quality and features. Since then, this trend has been red-hot, with many devices featuring a dual camera setup. Last month, Facebook demonstrated that these features can be achieved without the dual-camera setup. The company has developed software that can identify the foreground and background without the use of two cameras for depth perception. These are just the first steps of their mega, multi-year roadmap plan to bring AR and AI to mobile devices.
3D Perception and Deep Learning Enter Smart Home Market; Cloud Privacy Concerns Raised
The year 2017 has already been deemed the year of the voice interface. Nonetheless, recent events show that vision is swooping in as a formidable contender to voice. Microsoft announced that they are joining in on the far-field smart speaker frenzy, which is now dominated by Amazon Echo and Google Home. The device, called Invoke, will be launched by Samsung and will include Microsoft’s digital assistant, Cortana.
At the same time, Amazon is already taking the next step forward. While CES 2017 opened the year with everyone wanting to talk with Alexa on the Amazon Echo, Amazon’s newly announced products Echo Look and Echo Show are now stealing the show. The Echo Look utilizes a depth sensor and AI algorithms to supply fashion advice to the users. This has really sparked a public discussion on problems with video analytics on the cloud concerning security and privacy issues. These issues make a very strong case for edge analytics, meaning performing the processing on the device itself and not in the cloud.
The Echo Show is equipped with a screen and a camera, giving Alexa the ability to show you information, and to connect you with other Echo Show users via video chats. Although the Microsoft/Samsung speaker has not yet been released, it seems logical that they will also soon launch a version with a camera and display. This should be the natural next step for the Invoke, since one of its selling points is that can be used for Skype, which is a video chat application, after all.
Amazon's promotional video for the Echo Show (Credit: Amazon)
It is not yet clear how the Echo Show will use the camera to improve the Alexa AI, but it is now a completely viable feature. Naturally, the other smart speaker players like Google, and now Microsoft, won’t stay behind for long and will also endow their devices with a display and camera.
Another very strong case for edge analytics is the sheer amount of raw video data that is constantly growing from always-seeing cameras. If every home were to upload full HD (or better) video 24/7, in addition to surveillance cameras, autonomous vehicles and other use cases, the amount of data would exceed the available limits of bandwidth and storage. Using edge analytics, only the useful information (called metadata) would be uploaded and stored, as necessary per use case. One such device is made by Camio who use edge processing to only send the metadata to the cloud and apply AI to enable real-time video search. As shown in their EVS 2017 presentation, their next version will move majority of the AI onto the device itself to further improve latency and efficiency of the product.
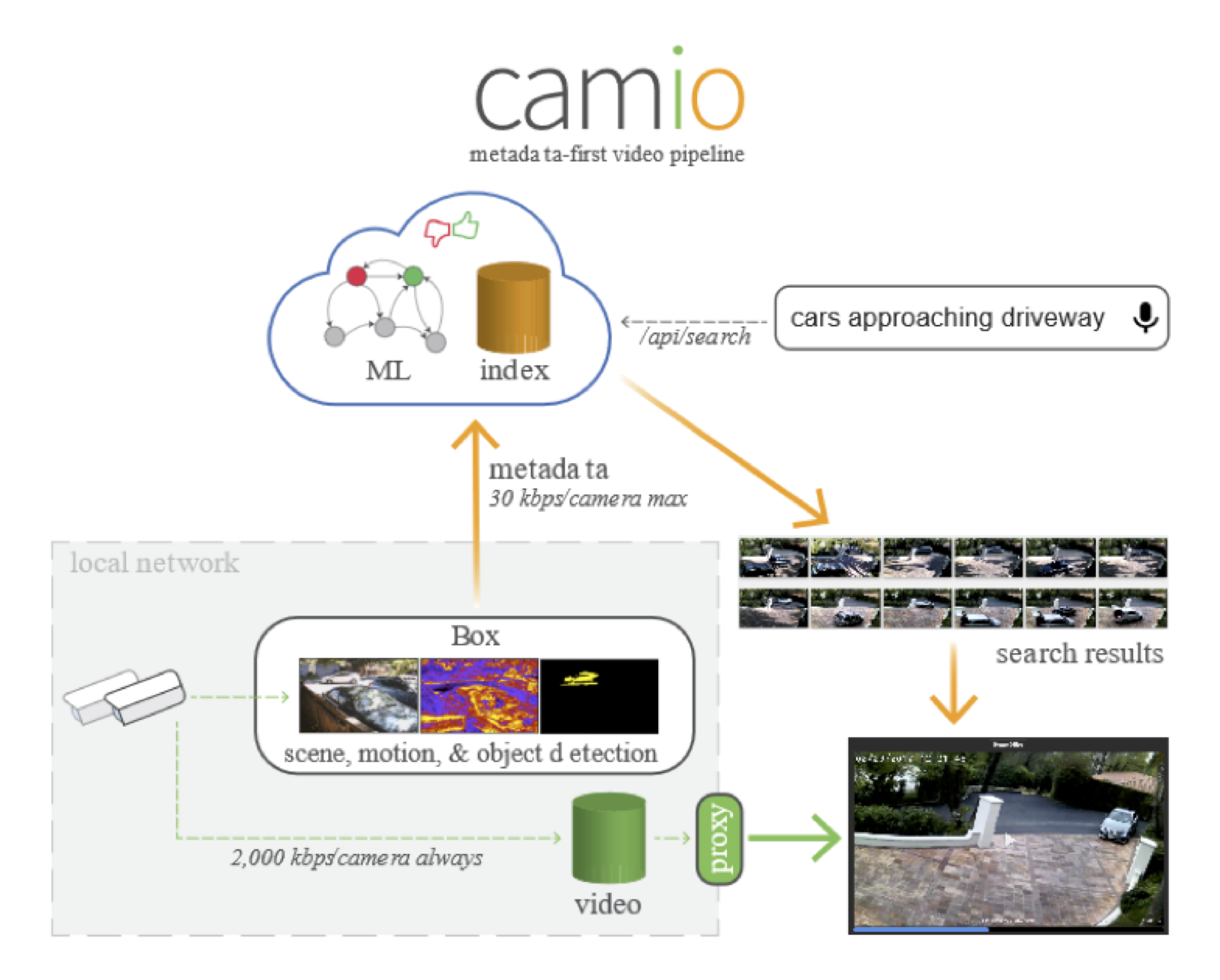
Camio’s metadata-first video pipeline enabling video search (Credit: Camio)
Taking 3D perception and AI one step forward is this new device from Lighthouse. It combines a 3D sensor, video camera, deep learning, and computer vision in sophisticated ways to answer questions on actions within the video feed such as “Did anyone walk the dog today?”
Lighthouse promotional video (Credit: Lighthouse)
Power-efficiency, Development Time, Flexibility Will Determine Success
Many exciting, innovative vision products are starting to flood the market. Which of them will be successful, and which won’t? The factors that determine this have as much to do with the insides of the device as they do with the exterior design and user interface.
The engines running all this amazing vision software must be extremely efficient, due to the heavy processing involved and the increasing demand for portability. Even the devices that are relatively stationary, like the smart speakers mentioned above, are starting to lose their cords and will have to find ways to use less power. It is also critical to have tools that can streamline the transition to an embedded environment. This can minimize time-to-market while reducing risk and complexity. Another key factor is flexibility. The dynamic field of embedded vision and imaging is constantly evolving. The only way to make a future-proof solution is to make sure that the software can be updated whenever required.
A solution based on the CEVA-XM6 computer vision processor and using the CDNN toolkit is sure to check all the above boxes. To find out more, you can read about our imaging and computer vison solutions on our website. You are also welcome to visit us at the Augmented World Expo and learn more about how CEVA is bringing intelligent vision to the mass market. Hope to see you there.
By Yair Siegel
Director of Segment Marketing, CEVA.