
This blog post was originally published at Cadence's website. It is reprinted here with the permission of Cadence.
"It's a visual world," Tim Ramsdale of ARM said at one point in the recent Embedded Vision Summit. "If I had a colleague come and drop a stack of plates at the back of the room, you'd all look round to see what happened, not listen harder." Today, we sometimes have very simple sensors that are a proxy for vision. Most of us have sat in a conference room with a sensor and had the light turn off on us because nobody was moving enough. Vision will be everywhere going forward. But not just in our conference rooms, but in our cars, our baseball stadiums. Maybe even by the dartboard in the local dive bar.
Embedded Vision Summit
Jeff Bier, who created the summit, was asked during a Q&A about how the event has grown. He said that it was like Ernest Hemingway's comment on how he went bankrupt, "gradually, and then suddenly." When they started the summit, it was a small gathering of the few people who were interested in embedded vision, and he wondered if they were wasting their time. Now it is thousands of people in five parallel tracks, and it is one of the hottest areas in computer science or even just technology.

If I had to pick a watershed moment, it would be Yann LeCun's keynote in 2014 on using neural nets for vision recognition. He pointed a little camera at objects around the stage and, in real time, his computer said "it's a pen," or "it's a cellphone." The only one it got wrong was calling a muffin a bagel. "Hey, it was trained in New York," Yann joked. But I'd never seen anything like that before, I was more used to OCR systems that didn't do that great a job of recognizing text.
Since then, neural nets have taken off as being the solution to many vision problems, but also almost any problem with messy data and inexact answers, such as voice recognition or driving decisions. I have seen it said that there has been more development in the field in the last three years than in the previous 30, and it is easy to believe.
One of the other challenges that was repeatedly mentioned was the shortage of people who understand this stuff. There are about 20,000 people who are knowledgeable about deep learning versus about 2M regular programmers. In addition to the fundamental technical challenges, there is the challenge of "how do we democratize vision and vision technology so you don't need a PhD?" as Jeff McVeigh of Intel put it. Most people will need off-the-shelf hardware and libraries, they are not going to build an SoC or program up their own learning algorithms.
Watch for…
This week is embedded vision week here on Breakfast Bytes. Watch out for posts in the rest of the week:
Lifting the Veil on Hololens, which was the opening keynote by Marc Pollefeys of Microsoft.
Deep Understanding Not Just Deep Vision, which was the second-day keynote by Jitendra Malik of Cal, who has been working in this area since he was a masters student 35 years ago.
How to Start an Embedded Vision Company, which was a presentation by Chris Rowen, recently CTO of Cadence's IP group and the father of the Tensilica processor. He recently left to…well, read the title.
How Embedded Vision Is Transitioning from Exotic to Everyday, on a presentation by Jeff Bier, the chairman of the Embedded Vision Allilance. He showed how conservatively he thinks performance will improve by 1000X in the next three years.
It's the Power, Stupid
There were several themes that ran through the conference. I always think it is significant, if a little boring, when each presenter gets up and many of them say the same thing. It means that the research phase of throwing mud at walls and seeing what sticks is starting to switch to the development phase where real products are being developed. Some are very serious, such as driving and predicting heart attacks, and some are whimsical, such as the can't-miss dartboard (see below for a video on that one). In between, perhaps, was Steven Cadavid of Kinatrax talking about markerless analysis of baseball pitchers. One of the first teams to use the system, starting in 2016, were the Chicago Cubs. They immediately won the World Series for the first time since 1907…just saying'.
There are a lot of names for neural networks such as deep learning, deep neural networks, convolutional neural networks, and more. Sometimes there are subtle differences. Somebody pointed out in one presentation that in the 1960s people used the phrase "automatic programming", which meant not having to write assembly language (or even pure binary) code. But, programming computers in high-level languages did turn out to be a really big deal (if not exactly automatic programming, CEOs are still not writing their own COBOL programs or even SQL). In the same way, the new way of "programming" these ill-defined tasks is:
- Build a deep neural network (with hundreds of layers)
- Use a huge training dataset to calculate the weights for the network
- Use the network for inference without ever explicitly telling the network "how" to tell the difference between a cat and a dog, or whatever it is
In his keynote, Jitendra pointed out that these problems are really hard and we don't get a lot of credit for the advances. "You mean you've been working for decades on this and now you can tell the difference between a cat and a dog? My beagle can do that."
The academic work until recently has cared little about efficiency. It was all about results, recognition success. For applications where there is a lot of training data, the technology is now better than humans. This tends to be on the margin, such as recognizing street signs in fog or very bright sunlight, where it is challenging for both computer and human. Researchers got kudos for a percentage increase in recognition ability without anyone caring that it used 100 times as much computer power. But now that there are lots of developments to use this technology for real applications, that is changing.
Thus a few more themes, most important for embedded vision, are:
- Do the training on the deep network, but then compress it once you have the weights, since most layers add little but you can only tell which after training.
- Don't use 32-bit floating point just because the training GPUs do. In many cases 8-, 4-, or even 2-bit resolution is enough to get good results.
- Power is really, really important. You will not have a server farm in your trunk.
Stephen Hawking said that "a picture is worth a thousand words…but uses a thousand times the memory." Tim Ramsdale of ARM pointed out that video is a thousand times worse, se we have to have processing at the edge, not just in the cloud, and that means low power. Even if the device is plugged in, the form factors can't cope with multiple watts of power consumption.
Did I say that low power is really, really important?
Cats, Dogs…and Zebras?
 There is lots of stuff that is still a research area. Jitendra hinted at this in the second day's keynote (watch for that on Friday). One of the big things is how to build these neural net-based inference engines without a lot of training data. He hinted at the possibility. By the age of two or three, kids have become visual learning machines. They can tell the difference between cats and dogs with at most hundreds of examples. But then they have a trick that visual researchers can only dream about:
There is lots of stuff that is still a research area. Jitendra hinted at this in the second day's keynote (watch for that on Friday). One of the big things is how to build these neural net-based inference engines without a lot of training data. He hinted at the possibility. By the age of two or three, kids have become visual learning machines. They can tell the difference between cats and dogs with at most hundreds of examples. But then they have a trick that visual researchers can only dream about:
You take them to the zoo and say "that is a zebra." That's all it takes. We still need a few thousand pictures of zebras for training.
Lux
Mark Bünger of Lux Research gave a fascinating presentation. Lux is in the finance industry and looks at the dynamics of the companies in the industry. He titled his talk Automakers at the Crossroads: How Embedded Vision and Autonomy Will Reshape the Industry. He didn't pull any punches (and, for clarification, what I say below is what he said. In many cases I don't know enough or haven't thought enough to decide whether I agree).
If there was a theme to his talk, that he said many times, it was that "Automakers are terrible at this stuff." He had lots of examples to demonstrate his point. Bluetooth was invented in 1994 but it wasn't until 2000 that Chrysler added it, but in general automakers were resisting. "We'll lose control of the dashboard" was their way of thinking. The car makers have never caught up to smartphones for in-car entertainment and never will. In-car navigation is inferior to Waze (and its many competitors).
More recently, automakers dropped the ball on smartphone-enabled business models that compete with car ownership, such as Uber and Lyft.
Now, self-driving cars look to repeat the story. Automakers saw what happened to phone manufacturers as a result of Android and so they won't work with Google. Instead, they are paying a lot of money to buy non-top-tier technology. For example, GM invested $500M in the market leader, right? Wrong, in Lyft, the distant #2. And they acquired Sidecar, who never operated outside of San Francisco (although they may own some key patents).
As Mark said repeatedly, "The auto industry really doesn't want to do this." All the advancements in the industries have been pushed by outsiders and he sees that continuing.
They also move too slowly. The auto industry has been working on a big standard called ITS (Intelligent Transportation System) that is meant to solve e-payment of tolls, the convenience of digital maps, v2v communication to enable automatic emergency braking, and more. All of these are already solved problems but, still ITS rolls on. Since there are about 250M cars on the road in the US, and since about 16M are sold each year and then last for 20 years, it will be decades before this technology is useful since it requires every car to be equipped. Seat belts took about 20 years to become ubiquitous, for example. Ten years for them to be available in all new vehicles and another ten years for enough new vehicles to be sold for most of the fleet to be replaced.
The next great white hope is 5G. But Mark thinks it will be good for entertainment but not much relevance for vehicle safety. It will all be image sensors (cameras, lidar, radar). As a result, us users of cars and suppliers of technology don't need to wait. Only carmakers are working on DSRC radio (dedicated short range communications) but the whole world is working on vision. Vision is the horse to back.
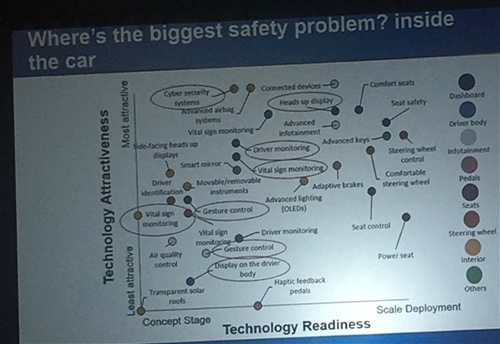
Above is a bubble chart of readiness versus attractiveness that he prepared for their clients, for lots of technologies. Click on the picture for a better (I didn't say good!) view.
With regards to sensors, he thinks we need arrays of simple sensors. They are already getting to be good enough, the software just needs to catch up, which it will since software cycles are so much faster than hardware. He calls this "software-defined sensors". Cute name, it might catch on.
The carmakers are especially terrified of autonomy since it could reduce the number of cars we need dramatically. It is already the case that the average car sits around unused for 98% of the time in either your garage or your parking lot at work. But even when you use it, about 40% are dead trips (you drive your kids to school, fine; you come back home, a dead trip). But it could mean we only need 30%, or even 20% or less of the cars we need today. One implication is that if we only need 30% of the cars going forward, the transition could happen very fast. Instead of taking 10 years to get close to 100%, just three years to get to 30%. Mark says it will happen first with fleets (trucks, taxis, Uber) where the cohort of drivers (or the lack of need for them) is controlled.

Bottom line is that intelligent transportation systems being constructed slowly by the manufacturers are being leapfrogged by vision. "Vision is the new protocol."
The Dartboard You Can't Miss
 Mark Rober has the oddest job description. His bio in the conference program reads "Mark Rober is an engineer, inventor, and YouTube personality."
Mark Rober has the oddest job description. His bio in the conference program reads "Mark Rober is an engineer, inventor, and YouTube personality."
Yes, he used to work as an engineer at JPL, but is now a YouTube personality getting millions of views of his videos (over 1/4 billion in total), and also multiple appearances on the Jimmy Kimmel show. He apparently has an impressive day job at a large Silicon Valley tech company but he has to leave it nameless (large Silicon Valley tech companies are not known for their sense of humor).
He makes a video about once a month about some technical thing, but this video took three years to pull off. It uses multiple cameras to track a dart in flight. In the first 200ms, it works out where it will go. Then in the next 200ms, it uses stepper motors to move the dartboard so that the dart will hit the bullseye. It is not a simple system. The video is 500 images per second at 4K resolution with six cameras, and gigabit Ethernet. When he started, they tried with two cameras and a slow frame rate and USB—it wasn't even close to what was required.
If you are thinking of quitting your day job to make YouTube videos, he had some sobering numbers. You don't make much. I already knew the economics since my son used to work for YouTube and managed their original affiliate program, although in that era "Fred" became the first YouTube millionaire (in both subscribers, and dollars) as a teenager, which is more than most of us did in our teens. Currently it pays about $1,000 for every million views, so knock 3 zeros off.
Instead, he funds these videos with sponsors who have included NVIDIA, Bill Gates, 23andMe, Dollar Shave Club, Audible. Young people don't watch TV any more so companies are trying to find other ways to reach them online. For this particular video, Vicon lent him the $80,000 camera system. Later, in the exhibit hall during the social hour, he had the actual dartboard, but unfortunately not set up (a bunch of mostly male engineers, free beer, and darts, what could possible go wrong?).
By Paul McLellan
Editor of Breakfast Bytes, Cadence