
Artificial intelligence on mobile devices is no longer dependent on a connection to the cloud. As evidenced by the hottest demos at CES this year and all the recently announced smartphone flagships, AI has entered the edge device, and has quickly become a marketing selling point. For many reasons, including security, privacy and response time, this trend is bound to continue and expand to more edge devices. To meet demand, almost every player in the silicon industry has come out with some version of AI processor, under many names, like ‘deep learning engine’, ‘neural processor’, ‘AI engine’ etc.

(source: CEVA)
However, not all AI processors are created equal. In practice, many of the so-called AI engines are the same as traditional embedded processors (leveraging CPU and GPU) with the addition of a vector processing unit (VPU). The VPU is designed for efficiency in performing the heavy-duty computations associated with computer vision and to some extent with deep learning. While having a strong, low-power VPU is a very significant part of handling embedded AI, it is not the whole story. The VPU is one of the many components that make up an excellent AI processor. A VPU, however well-designed it may be, is still just a VPU that indeed provides the required flexibility, but it is not an AI processor. Here are some of the other features that are vital to AI processing at the edge.
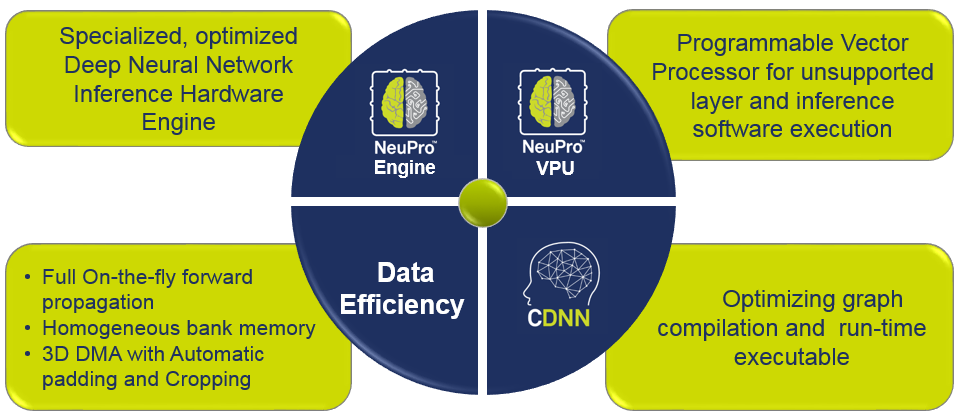
NeuPro™ – CEVA’s Holistic Solution for AI (Machine Learning)
(Source: CEVA)
Optimizing the workload for embedded systems
In cloud-based processing, calculations are performed in floating-point for training and fixed-point for inference, achieving maximum accuracy. In large server farms, where the data is processed, energy and size must be considered, but they are virtually unlimited, when compared to processing on the edge constraints. In mobile devices, Power consumption, Performance and Area (PPA) are vital to the feasibility of the design. Hence, in embedded SoCs, much more efficient fixed-point calculations are preferred. When converting a network from floating-point to fixed-point, some precision is inevitably lost. But, with the right design, this can be minimized to achieve almost the same results as the original trained network.
One of the ways to control the accuracy is to choose between 8-bit and 16-bit integer precision. While 8-bit precision saves bandwidth and computation resources, many commercial NNs still require the accuracy provided by using 16-bit precision. Each layer in neural networks has different constraints and tolerance, therefore it is crucial to select the optimal precision for each layer.

Optimal Precision on a Layer Basis
(Source: CEVA)
For developers and SoC designers, a tool that automatically outputs an optimized graph compilation and run-time executable, like the CEVA Network Generator, is a huge advantage from a time-to-market perspective. Furthermore, it is important to maintain the flexibly to select the optimal precision (8 bit or 16 bit) for each layer. This enables optimal tradeoff between accuracy and performance per layer, resulting in an efficient and precise embedded network inference, at the push of a button.
Dedicated hardware to deal with real AI algorithms
VPU’s are versatile, but many of the most common neural networks challenge the standard processor instruction sets with the demanding bandwidth pipeline. Therefore, it is imperative to have dedicated hardware to deal with these complex calculations.
For example, the NeuPro AI processor includes specialized engines for Matrix Multiplication, Fully Connected, Activation and Pooling layers. This advanced, dedicated AI engine works in conjunction with the fully programmable NeuPro VPU, which enables support of all other layer types and NN topologies. The direct connection between these modules enables a seamless handover, eliminating the need to write to the internal memory. In addition, an optimized DDR BW and advanced DMA controller enable on-the-fly pipeline processing, further boosting speed while reducing the power consumption.
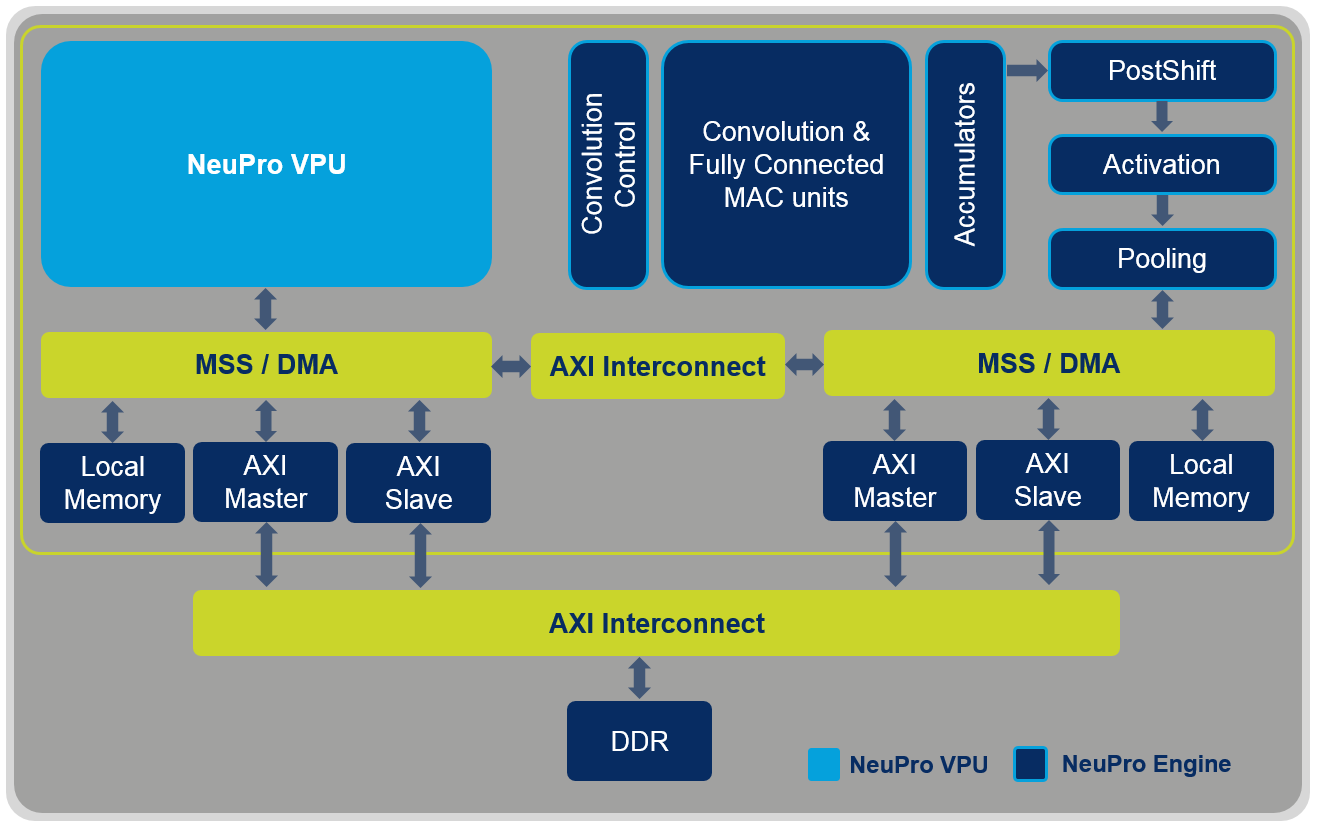
Block diagram of the NeuPro AI Processor combining the NeuPro Engine and NeuPro VPU
(Source: CEVA)
The unknown AI algorithms of tomorrow
AI is still a nascent and rapidly evolving field. Neural networks, for example, are used for object recognition, speech and sound analytics, 5G communication and a rapidly growing number of other use cases. Keeping an adaptive solution for future trends is the only way to ensure the success of a chip design. Therefore, dedicated hardware for today’s algorithms is certainly not enough, and must be accompanied by a fully programmable platform. In this flux of ever-improving algorithms, PC simulation is a critical tool for making decisions based on actual results and reducing time-to-market. The CDNN PC Simulation Package allows SoC designers to study the tradeoffs of their design on a PC environment before developing the actual hardware.
Another valuable feature for futureproofing the design is scalability. The NeuPro AI product family is designed to handle a wide range of target markets from ultra-light IoT and wearables (2TOPs) to high performance enterprise surveillance and autonomous driving (12.5 TOPs).
The race to achieve the ultimate AI processor for mobile applications at the edge has begun. Many are quick to catch on to the trend and use AI as a selling point for their products, but not all of them have the same level of intelligence inside. Those looking to build a smart device that will stay smart as the field of AI progresses, should make sure they can check off all the above mentioned features when selecting an AI processor.
Learn more
For more info about NeuPro, click here.
To access a detailed Linley Microprocessor Report analysis, click here.
Liran Bar
Director of Product Marketing, Imaging & Vision DSP Core Product Line, CEVA