This blog post was originally published at Intel's website. It is reprinted here with the permission of Intel.
One of the biggest challenges to AI can be eliciting high-performance deep learning inference that runs at real-world scale, leveraging existing infrastructures. Combining efficiency and flexibility, the Intel® Distribution of OpenVINO™ toolkit (a developer tool suite that stands for Open Visual Inference and Neural Network Optimization) accelerates high-performance deep learning inference deployments.
Latency, or execution time of an inference, is critical for real-time services. Typically, approaches to minimize latency focus on the performance of single inference requests, limiting parallelism to the individual input instance. This often means that real-time inference applications cannot take advantage of the computational efficiencies that batching (combining many input images to achieve optimal throughput) provides, as high batch sizes come with a latency penalty. To address this gap, the latest release of the Intel Distribution of OpenVINO Toolkit includes a CPU “throughput” mode.
This new mode allows efficient parallel execution of multiple inference requests by processing them using the same CNN, greatly improving the throughput. In addition to the reuse of filter weights in convolutional operations (also available with batching), a finer execution granularity available with the new mode further improves cache utilization. Using this “throughput” mode, CPU cores are evenly distributed between parallel inference requests, following the general “parallelize the outermost loop first” rule of thumb. It also greatly reduces the amount of scheduling/synchronization compared to a latency-oriented approach when every CNN operation is made parallelized internally over the full number of CPU cores.
The resulting speedup from the new mode is particularly strong on high-end servers, but also significant on other Intel® architecture-based systems, as shown in Table 1.
| Topology\Machine | Dual-Socket Intel® Xeon® Platinum 8180 Processor | Intel® Core™ i7-8700K Processor |
|---|---|---|
| mobilenet-v2 | 2.0x | 1.2x |
| densenet-121 | 2.6x | 1.2x |
| yolo-v3 | 3.0x | 1.3x |
| se-resnext50 | 6.7x | 1.6x |
Table 1. Example speedup of the “throughput” mode over best performance with batch, measured for common topologies on two different Intel® processors. Configurations: Intel® Xeon® Platinum 8180 processor @ 2.50 GHz with 32GB of memory, OS: Ubuntu 16.04, kernel: 4.4.0-87-generic; Intel® Core™ i7-8700 processor @ 3.20GHz with 16 GB RAM, OS: Ubuntu 16.04.3 LTS, Kernel: 4.15.0-29-generic. See notices and disclaimers for details.
Together with general threading refactoring, also introduced in the R5 release, the toolkit does not require playing OMP_NUM_THREADS, KMP_AFFINITY and other machine-specific settings to achieve these performance improvements; they can be realized with the “out of the box” Intel Distribution of OpenVINO toolkit configuration.
Beyond raw performance, additional advantages of the toolkit’s “throughput” mode include:
- Reduced need to batch multiple inputs for improved performance. This also helps to simplify tasks like app logic by minimizing synchronization, as it is now possible to keep a separate inference request per input source (e.g. a camera), and let the toolkit process the requests in parallel. This provides the best throughput, while reducing latency by skipping step of waiting for bigger batches to accumulate.
- Better trade-off between latency and throughput. To meet a specific time threshold of say, 30 milliseconds (e.g. to meet real-time requirements), it is possible to improve throughput while maintaining a set latency amount (see next figure).
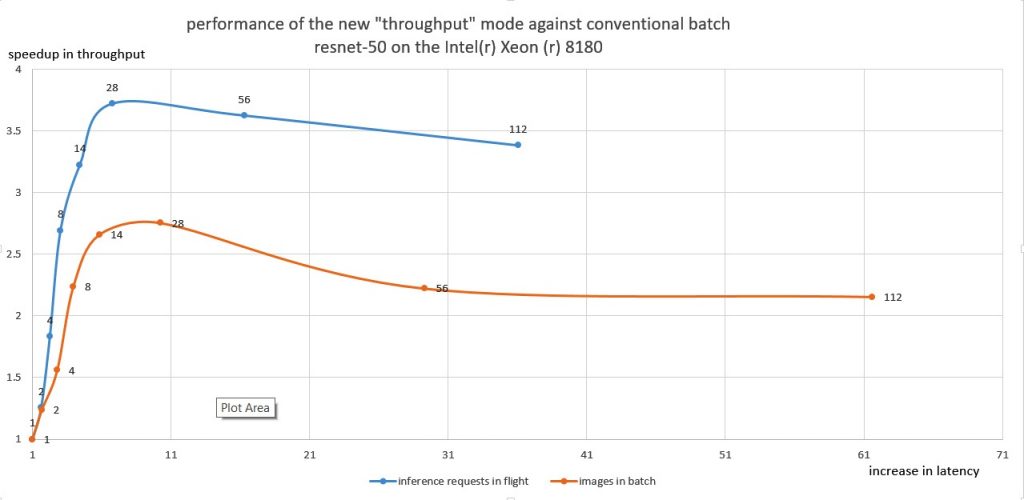
Let’s measure latency versus throughput for the approaches discussed in this post. Below is the new “throughput” mode of the Intel Distribution of OpenVINO toolkit, compared to the conventional approach that uses the batching:

Figure 1. Comparing performance of the new “throughput” mode (altering number of parallel single-image inference requests from 1 to 112) versus performance with legacy approach (altering number of images in a batch from 1 to 112, executed as a single inference request). The data is normalized to the throughput and latency of the single input image executed as a single inference request. Configuration: ResNet-50 on Intel® Xeon® 8180 processor (28 physical CPU cores, 56 logical cores). See notices and disclaimers for details.
A few observations on the figure above:
- The initial slope of the curves indicates how throughput grows when increasing the number of inputs by using batch and the parallel requests respectively.
- The “throughput” mode demonstrates faster growth of throughput. The top throughput is also higher with the new mode. Notice that it is achieved when the number of requests in the flight meets the number of physical cores. When every physical core processes a dedicated input, the amount of synchronization (with other threads) is minimal.
- Inflating the batch too much (or growing the number of requests in the flight) can degrade throughput due to increased memory and cache requirements. A general rule of thumb is processing 1-2 images per physical CPU core.
- Latency-wise, the new mode reduces latency while increasing the number of inputs compared to the conventional batch approach.
- This “throughput mode” is fully compatible with batching, as each parallel inference request can in turn handle multiple inputs (as a batch). This can further improve performance for the lightweight topologies.
- Notice that since the throughput mode relies on the availability of the parallel slack, running multiple inference requests in parallel is essential to leverage the performance. It might require change in the application logic. To simplify the task, the toolkit offers Asynchronous Inference API (see further references below). An additional upside from using the API is amortizing data transfers, input decoding, and other pipeline costs.
Try your favorite model with the new throughput mode
To simplify benchmarking, the Intel Distribution of OpenVINO toolkit features a dedicated Benchmark App that can be used to play with the number of inference requests running in parallel from the command-line. The rule of thumb is to test up to the number of CPU cores in your machine. For example, on an 8-core processor, compare the performance of the “-nireq 1” (which is a latency-oriented scenario with a single request) to the 2, 4 and 8 requests. In addition to the number of inference requests, it is also possible to play with batch size from the command-line to find the throughput sweet spot.
Conclusion
The new CPU “throughput mode” in the Intel Distribution of OpenVINO toolkit enables support for finer execution granularity for throughput-oriented inference scenarios. This brings a significant performance boost for both data centers and inference at the network edge.
More Information
We discussed other CPU-specific features in the latest Intel Distribution of OpenVINO toolkit release in a previous blog post, including post-training quantization and support for int8 model inference on Intel® processors. The toolkit’s throughput mode is fully compatible with int8 and brings further performance improvements.
Additional Documentation on the Intel Distribution of OpenVINO Toolkit:
- General information
- Further reference on “throughput” mode
- Asynchronous API
- CPU inference configuration knobs
- Int8 quantization for fast CPU inference using OpenVINO
Notices and Disclaimers:
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Configurations:
Intel® Xeon® Platinum 8180 Processor @ 2.50 GHz with 32GB of memory, OS: Ubuntu 16.04, kernel: 4.4.0-87-generic
Intel® Core™ i7-8700 Processor @ 3.20GHz with 16 GB RAM, OS: Ubuntu 16.04.3 LTS, Kernel: 4.15.0-29-generic
Performance results are based on testing as of December 18, 2018 by Intel Corporation and may not reflect all publicly available security updates. See configuration disclosure for details. No product or component can be absolutely secure. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Maxim Shevtsov
Senior Software Engineer, Intel Architecture, Graphics and Software Group, Intel
Yury Gorbachev
Principal Engineer, Internet of Things Group, Intel