This article was originally published at Intel's website. It is reprinted here with the permission of Intel.
TensorFlow* is one of the most popular deep learning frameworks for large-scale machine learning (ML) and deep learning (DL). Since 2016, Intel and Google engineers have been working together to optimize TensorFlow performance for deep learning training and inference on Intel® Xeon® processors using the Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN). The performance optimizations are not limited to training or inference of deep learning models on a single CPU node, but also improve the performance of deploying TensorFlow models via TensorFlow Serving and scale the training of deep learning models over multiple CPU nodes (distributed training).
In this article, we will discuss recently implemented inference-specific optimizations that are applicable to both real-time inference (batch size of one, at the lowest latency) and offline inference (large batch size, at maximum throughput), but enable especially strong performance improvements for real-time inference.`
Optimizations
As described in this article, a deep neural network written in a high-level language like Python* is represented as a data-flow graph in TensorFlow. Optimizing the data-flow graph accelerates the performance of the corresponding neural network. Some of the optimizations discussed below are graph-level optimizations, while others are at the operator level.
Graph-level Optimizations
Operator Fusions
It is a common practice to overlap computation with memory accesses in order to conserve compute cycles. Operator fusion optimizations looks for operators of different types (such as compute-bound, memory-bound, I/O bound, etc) that follow in a sequence, and fuses them into a single operator.

One of our fusions, for example, looks for a Pad operator followed by a 2D Convolution operator, and fuses them into a single operator called PadWithConv2D. Since the Pad operator adds more elements to its input tensor (and is memory-bound), fusing it with the compute-bound 2D Convolution reduces execution time by hiding a memory-bound operation behind a compute-bound operation. Implementing this optimization is straightforward (seen in Fig. 1), as the 2D Convolution operator accepts padding values as an input attribute. Another example of a fusion is fusing 2D Convolution with BiasAdd and ReLU operators.

Figure 2: Graph Optimization Example: Before and After Fusion
Our graph optimization pass not only looks for patterns of two operators but can also fuse sequences of more than two. One such example is an optimization to eliminate redundant transposes introduced by neural networks operating in different tensor data formats. We have seen cases where an input tensor that is in the NCHW data format is transposed into the NHWC format, fed to a 2D Convolution that operates in the NHWC data format, and with the output of the 2D Convolution again transposed from the NHWC data format to the NCHW data format.
Transpose is a memory-bound operation that wastes computational cycles in this particular case. As seen in Fig. 2, both of these transposes can be made redundant if the 2D Convolution is made to operate directly in the NCHW data format. We also observed many of these fusion opportunities when using the Keras APIs, and our fusions eliminate these redundancies.
Batch Normalization (BatchNorm) Folding
Batch normalization is commonly performed while training a deep learning model. However, during inference this node is unnecessary and can be folded into neighboring operator nodes.

Figure 3: Batchnorm Folding Optimization: Before and After the Optimization.
The BatchNorm operation may be present either as a single operator node or natively as subtraction followed by real division followed by multiplication as shown. In such cases the BatchNorm (Sub-RealDiv-Mul) operator can be removed by using the mean, variance and gamma constant nodes and modifying the weights and beta constant nodes, thus folding it into the convolution and bias neighboring operators as shown in the after graph in Fig. 3. By removing the BatchNorm node, which frequently occurs in convolutional neural networks, we improve inference performance.
Filter Caching
Convolutional neural networks will often have filters as inputs to the convolution operation. Intel® MKL-DNN uses an internal format for these filters that is optimized for Intel Xeon processors and is different from the native TensorFlow format. When this filter is a constant, which is usually the case with inference, we can convert the filter from TensorFlow format to Intel MKL-DNN format one time,and then cache it. This cached filter is reused in subsequent iterations without needing to perform these format conversions again. More information on respective formats is described in this TensorFlow CPU optimizations article. This, too, accelerates neural network performance on CPU.
Primitive Reuse
Creating an Intel MKL-DNN primitive (data structures and JIT-ed code) to execute any operator such as convolution can be compute-intensive. We implemented an optimization in TensorFlow by caching newly-created Intel MKL-DNN primitives for operators. If the same operator with matching input parameters is called again, we can reuse the cached primitive. We have applied primitive reuse optimizations for forward and back propagation. These optimizations have been applied for several operations, such as Convolution, ReLU, Batch Normalization, and Pooling.
Intel® Optimizations for TensorFlow
Intel® Optimizations for TensorFlow using Intel MKL-DNN have been upstreamed to the TensorFlow repository. However, they must be enabled with a special build flag, as explained in the Installation Guide. To make it easier for users to take advantage of these optimizations, Intel has published TensorFlow binaries that have these optimizations enabled by default. These binaries are available in Docker* containers and Python wheels.
Docker* Containers
Instructions for obtaining and running containers with Intel Optimizations for TensorFlow can be found on the latest Installation Guide. In addition to the released and fully validated containers listed there, two additional types of containers are available as listed in Table 1.
| Tag | Description |
| nightly-devel | Python 2 nightly build based on https://github.com/tensorflow/tensorflow master branch. |
| nightly-devel-py3 | Python 3 nightly build based on https://github.com/tensorflow/tensorflow master branch. |
| nightly-prs | Python 2 nightly build based on https://github.com/tensorflow/tensorflow master branch with all open pull requests related to the Intel Optimization for TensorFlow. NOTE: This container contains code that may not be approved by TensorFlow maintainers. |
| nightly-prs-py3 | Python 3 nightly build based on https://github.com/tensorflow/tensorflow master branch with all open pull requests related to the Intel Optimization for TensorFlow. NOTE: This container contains code that may not be approved by TensorFlow maintainers. |
Table 1: List of Tensorflow Containers with Intel MKL-DNN Optimizations
Python Wheels
Full validated Python 2 and 3 installation packages are available on Anaconda* Cloud, the Intel Channel on Anaconda, the Intel® Distribution for Python, and PIP. Please see the latest Installation Guide for more information.
Building from Sources
The pre-built binaries discussed above have been compiled with Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions; running the binaries on older CPUs that do not support this instruction will result in “illegal instruction” errors. Users that would like to use the Intel Optimization of TensorFlow built without Intel AVX-512 instructions, or who would like a binary that is able to take advantage of all CPU instructions available on more modern CPUs should follow these instructions to build TensorFlow from sources. NOTE: Intel MKL-DNN will detect and utilize all available CPU instructions, regardless of what compiler flags TensorFlow has been built with. Only eigen code paths are affected by compiler flags.
TensorFlow Serving
While we have not yet published TensorFlow Serving binaries compiled with Intel Optimizations for TensorFlow, there are Dockerfiles published to the TensorFlow Serving github repository that can be used to build the containers manually. For instructions on how to best build and run a TensorFlow Serving container with Intel MKL-DNN, please see the Intel® Optimization for TensorFlow Serving Installation Guide.
Introducing Models Zoo for Intel® Architecture
The Models Zoo for Intel® Architecture provides a convenient way for users to get the best performance on commonly used topologies on TensorFlow. It contains benchmarking scripts and topologies that have been optimized for Intel® Xeon® Processors; the repository can be freely forked and we welcome community contributions and feedback.
Benchmarking Scripts
The benchmarking scripts were optimized by Intel engineers to get the best performance when running TensorFlow on Intel Xeon Processors. After downloading prerequisites described in the README file for each topology, you can use the scripts to launch a TensorFlow container of your choice, which will then install remaining dependencies in order to run the benchmarks. These scripts will detect the hardware on which the container is running and optimize the script environment accordingly.
Optimized Models
Whenever possible, we have upstreamed our optimizations to the TensorFlow framework. However, in some situations, we needed to optimize the topology itself (e.g. by adding platform awareness). Whenever a topology has been changed, we have submitted pull requests for our optimizations to the topology maintainer; and when the maintainer has merged our pull requests, the benchmarking scripts simply use the upstream version of the topology. When the topology maintainer did not accept our pull requests, however, we have forked the repo and placed our optimized version in the models directory, and the benchmarking scripts refer to that source instead.
Results
In this section, we show the inference performance numbers for six models for both latency (batch size of one) and maximum throughput (large batch size). The models we picked are representative set of image classification, object detection and language translation problems. These results represent performance improvements provided by the Intel Optimization for TensorFlow normalized against the non-optimized version of TensorFlow.

Figure 4: Latency performance of TensorFlow with Intel MKL-DNN1
We know that lower latency means better runtime performance for batchsize = 1. As seen in Fig 4, latency performance of TensorFlow with Intel MKL-DNN for the six models is better than or equal to TensorFlow without Intel MKL-DNN (baseline).

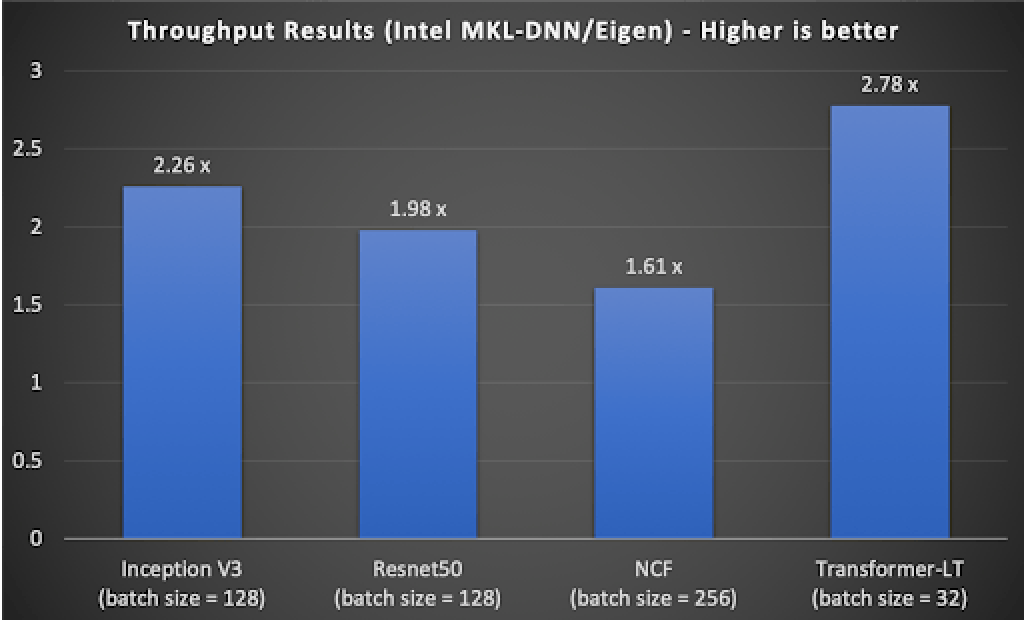
Figure 5: Throughput performance of TensorFlow with Intel MKL-DNN1
Higher throughput means better runtime performance for batchsize greater than one. As seen in Fig. 5, throughput performance of TensorFlow with MKL DNN for the four models are better than Tensorflow without Intel MKL-DNN (baseline).
Summary
Improving runtime performance for TensorFlow models on Intel architecture is made easy by deploying Intel Optimization for TensorFlow. Recent testing by Intel shows up to a 60% performance improvement in latency at batch size one on a variety of popular models. No additional software or configuration is required; users can directly download prebuilt Python wheels or make use of the Docker containers. To get started, consult the Intel Optimization for TensorFlow installation guide and take advantage of pre-trained models from the Models Zoo for Intel Architecture. Follow us on @IntelAIDev for more news about framework optimizations from the Intel AI team.
Additional Contributors
Karen Wu, Ramesh AG, Md Faijul Amin, Sheng Fu, Bhavani Subramanian, Srinivasan Narayanamoorthy, Cui Xiaoming, Mandy Li, Guozhong Zhuang, Lakshay Tokas, Wei Wang, Jiang Zhoulong, Wenxi Zhu, Guizi Li, Yiqiang Li
Acknowledgements
Huma Abidi, Jayaram Bobba, Banky Elesha, Dina Jones, Moonjung Kyung, Karthik Vadla, Wafaa Taie, Jitendra Patil, Melanie Buehler, Lukasz Durka, Michal Lukasziewski, Abolfazl Shahbazi, Steven Robertson, Preethi Venkatesh, Nathan Greeneltch , Soji Sajuyigbe, Emily Hutson, Anthony Sarah, Evarist M Fomenko, Vadim Pirogov, Roma Dubstov.
Notices and Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
1. System configuration: Intel® Xeon® Platinum 8180 CPU @ 2.50GHz; OS: CentOS Linux 7 (Core); TensorFlow Source Code: https://github.com/tensorflow/tensorflow; TensorFlow Commit ID: 355cc566efd2d86fe71fa9d755ceabe546d577a7.
Dataset used in benchmarking: Inception V3: synthetic data. Resnet50: synthetic data. NCF: MovieLens 1M.Transformer-LT: English-German. Mask R-CNN: MS COCO 2014. SSD-Mobilenet: MS COCO 2017.
Performance results are based on Intel testing as of February 20, 2019 and may not reflect all publicly available security updates. See configuration disclosure for details. No product or component can be absolutely secure.
Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Ashraf Bhuiyan
Deep Learning Software Engineer, Artificial Intelligence Products Group, Intel
Mahmoud Abuzaina
Deep Learning Software Engineer, Artificial Intelligence Products Group, Intel
Niranjan Hasabnis
Software Engineer, Artificial Intelligence Products Group, Intel
Niroop Ammbashankar
Deep Learning Software Engineer, Artificial Intelligence Products Group, Intel