This blog post was originally published at Intel's website. It is reprinted here with the permission of Intel.
Many AI applications have data pipelines that include several processing steps when executing inference operations. These steps can include data transformation, inference execution and conditional processing. The Seldon Core* open source machine learning framework facilitates management of inference pipelines, using pre-configured and reusable components. Intel and Seldon data scientists have worked together to improve the performance of the inference pipeline on Intel® Xeon® Scalable processors. Now, we’re sharing our results – and guidelines on how to adopt these improvements in various use cases.
Network Communication Performance Improvements
To create a solution suitable for the larger volumes of data used in image analysis workloads, we focused on making network communication and data transfer more efficient. In our first attempt, we switched from using a REST API protocol with ‘ListView’ data type to gRPC with tensor data type. This improved performance, but we were able to improve it further by changing the deserialization mechanism and employing NumPy and FlatBuffer methods. Our final setup for network communication on Seldon Core included the TensorFlow* Tensor data type which produced the shortest latency and overhead in our usage scenarios.

Figure 1. Performance improvements related to communication between microservices using GKE (Google Kubernetes Engine). Test configuration details in appendix.
Inference Execution Performance Improvements
Intel offers a ranges of solutions to speed up inference processing, from framework optimizations to software libraries, available through the Intel® AI Developer Program.
In this blog, we’ve presented optimizations for image classification using the Intel® Distribution of OpenVINO™ toolkit (a developer tool suite that stands for Open Visual Inference and Neural Network Optimization). Based on convolutional neural networks, the toolkit supports a range of Intel® processors and accelerators including CPUs, Intel® Processor Graphics/GPUs, Intel® Movidius™ VPUs, and FPGAs.

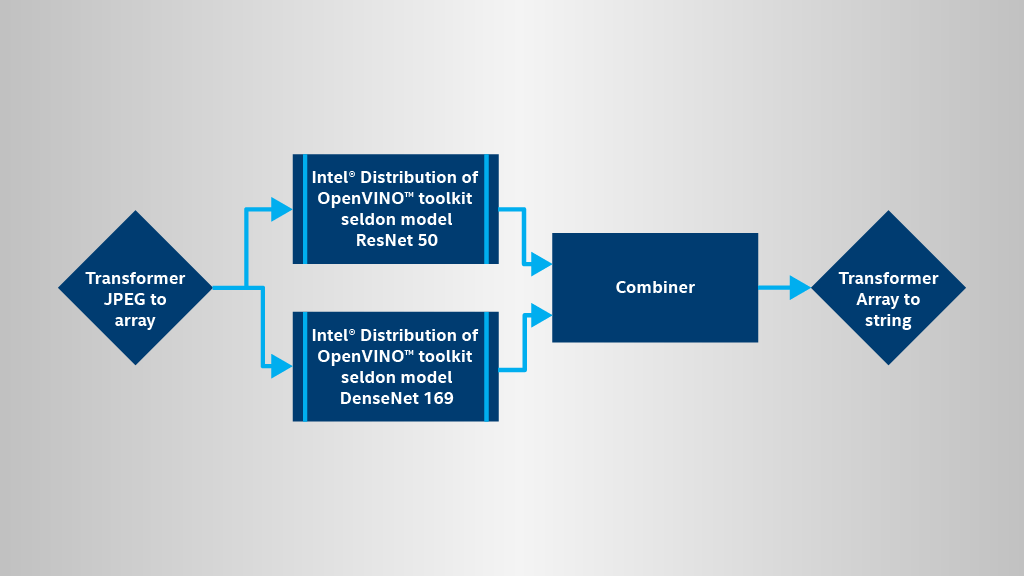
Figure 2. Model optimization and inference execution pipeline.
The Intel Distribution of OpenVINO toolkit features two key components: a Model Optimizer and an Inference Engine. We introduced a new type of model wrapper to Seldon Core that includes the toolkit’s Inference Engine.
Model Quantization Performance Improvements
Model quantization is a commonly used method to increase inference efficiency by reducing the precision of graph calculations. Refer to this blog post to learn more about the process of model quantization. New integer vector neural network instructions (VNNI) in future-generation Intel® Xeon® Scalable processors are expected to achieve performance gains in low precision convolution and matrix-matrix multiplication operations used in deep neural networks. These gains are a result of new instructions which multiply matrices so that multiplication operations can consume up to three times fewer cycles.
Demo environment
The data pipeline presented here demonstrates the performance enhancements described in the previous section. The pipeline includes the following components:
- An input transformer that converts jpeg compressed content into NumPy array
- Two model components that execute inference requests using ResNet and DenseNet models
- A combiner component that implements the ensemble of models
- An output transformer that converts an array of classification probabilities to a human-readable top1 class name
We also tested the scalability of Seldon Core by multiplying the inference pipeline with Kubernetes* replicas and an Ambassador load-balancer. In the tests, we used two models with identical input and output shapes and comparable accuracy results and complexity:
- ResNet v1.50
- DenseNet 169

Figure 3. Seldon pipeline with ensemble of models.
The components in the demo are created using a Seldon base docker image that includes a compiled OpenVINO Inference Engine with Python API and can be used to implement the code for executing the inference operations. For more details, refer to the documentation on software.intel.com or github. This base image also includes Intel® Optimizations for TensorFlow with Intel® Math Kernel Library (Intel® MKL) and OpenCV Python packages. It can be used to improve inference performance with standard TensorFlow models and images pre/post processing.
The demo pipeline can be reproduced in any Kubernetes cluster, or even run locally on a laptop using Minikube*. The deployment and testing steps are described in this Jupyter* notebook.
Results
The inference pipeline was tested on a GCP infrastructure using GKE service. Each Kubernetes node used 32 virtual cores of Intel Xeon Scalable processors.
Accuracy impact
In the first step we tested the accuracy of individual models used in the pipeline. This verification was completed for models with both float32 and int8 precision. We used a sample of 5000 images from the ImageNet dataset to estimate the results, though more accurate results can be collected with a complete ImageNet dataset. Finally, we validated the accuracy using the Seldon pipeline with an ensemble of models with reduced INT8 precision.
| Model | Accuracy Top1 |
| ResNet v1.50 float32 | 74.91 |
| ResNet v1.50 int8 | 74.87 |
| DenseNet169 float32 | 75.65 |
| DenseNet169 int8 | 75.59 |
| Ensemble of Resnet50 and DenseNet169 int8 models |
77.37 |
Table 1. Accuracy observed on the models and their ensemble collected with a sample of imagenet data. Test configuration details in appendix.
Latency
It can be difficult to analyze the execution timelines in distributed systems due to the complexity of tracking the correlations between events. We employed OpenTracing* and Jaeger* components to help with the pipeline execution visualization. Seldon has built-in integration with Jaeger which can be easily enabled in the pipeline.
Below are execution timelines captured in Jaeger for the pipeline presented in Figure 2.

Figure 4. Processing timelines for the pipeline with an ensemble of two models. Test configuration details in appendix.
As shown in Figure 4, we observed that communication between Seldon microservice adds fairly low latencies; depending on the message size in our pipeline, the latency might be in the range of 2-4ms. As well, the actual inference execution in the OpenVINO Inference Engine was about 5ms shorter than the Jaeger results for two Predict components. The reason of the difference is due to the gRPC communication overhead mentioned in the earlier section.
The inference execution time, based on the model components logs, was:
- ~30ms for DenseNet 169
- ~20ms for ResNet 50
Scalability
Seldon scalability was tested by horizontally expanding the Kubernetes cluster in the GKE service. At the same time, there were many requests generated by multiple clients.

Figure 5. Seldon pipeline scalability in GKE using nodes with 32vCPU. Test configuration details in appendix.
We observed linear scaling of up to 800 requests per second and 1600 predictions per second without any bottleneck. Despite the heavy request load, network traffic was low due to JPEGompression. We measured ~50Mb/s with throughput of about 900 images/sec.
Conclusions and recommendations
As we’ve shown above, network and serialization overhead in Seldon can be reduced to about 5ms for image classification data. The Intel Distribution of OpenVino toolkit speeds up Seldon inference execution, and using an ensemble method to train multiple models can boost accuracy without adding latency. Seldon can be used to effectively built complex execution pipelines, with no scaling bottleneck. The examples we’ve included can be easily reused and adopted, and the components and base images presented in this blog can simplify adoption of Intel Distribution of OpenVINO, OpenCV and Intel® Distribution for Python*. We invite you to follow us on @IntelAIDev and @Seldon_IO for future updates on machine learning framework optimizations.
Appendix
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure.
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations, and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/benchmarks.
Performance results are based on internal testing done on 1st February 2019 and may not reflect all publicly available security updates. No product can be absolutely secure. Test configurations are described below.
Hardware specification for GKE cluster tests for Seldon pipeline tests:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) CPU @ 2.00GHz
Stepping: 3
CPU MHz: 2000.166
BogoMIPS: 4000.33
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 56320
Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Consult other sources of information to evaluate performance as you consider your purchase. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel.
Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Dariusz Trawinski
Senior Cloud Software Engineer, Artificial Intelligence Products Group, Intel
Clive Cox
Chief Technology Officer, Seldon