This article was originally published by Xnor.ai. It is reprinted here with the permission of Xnor.ai.
Everywhere we hear that AI is going to change the world — those underlying AI models now power more products, businesses, and solutions. To understand what this all means, how AI models are structured, and how they are learning and making decisions — it is essential to understand the methodology and the context for how current AI models have evolved.
In this post, we present the trends and stages of AI models in the field of computer vision. The evolution is very similar in other application domains (e.g., Natural Language and Speech). Currently, deep learning is pioneering in AI models. The primary motivation behind the success of the deep learning was do not relying on human intuition for building features or representation for the data (visual, textual, audio, …), instead, to build a neural network architecture to figure out (learn) the representation. We observed repetitive progress in the trend of developing AI models that helps easily to predict the next phase of advancement in deep learning models. We believe the same motivation still holds and we should not rely on human intuition to build the neural network architectures as well; instead, we should let the computer figure out (learn) the architecture by itself. This novel claim is backed by recent research [18,19] that shows the neural network architectures learned by computers can perform better than the one designed by humans.
The learned neural architectures have extremely sparse connections; therefore, hardware supporting efficient sparse computations could be the main trigger for the next evolution in deep learning models.
If we look back at the key trends that led to the development of AI models in computer vision from two decades ago up to the beginning of the deep learning era, we observe these three stages:
1- Feature (Kernel) Engineering: This is a manual process of trying to explain the semantic content of images in a high-dimensional vector space by determining the type of visual configuration (similarities) in (or between) that exists in images. Examples of successful features were: SIFT [1], HOG [2], ShapeContext [3]. And some successful kernel functions were: RBF [4] and Intersection Kernel [5]. These features and functions were based on a human intuition of how visual recognition should work. This was the fundamental science behind the computer vision at the time. After a few years of research-driven by intuition, computer vision scientists were pretty much out of ideas for new features, which moved the field into the second stage.
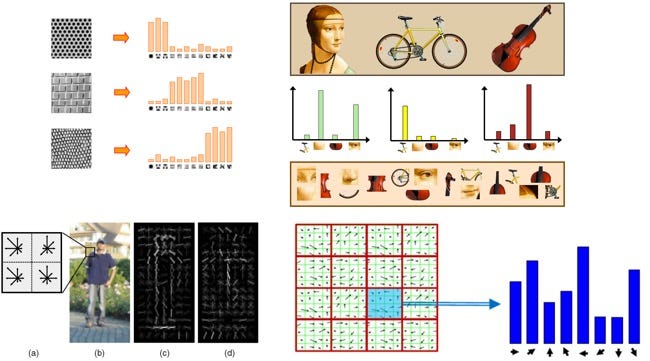
Feature engineering was the fundamental science behind the computer vision before deep learning
2- Feature (Kernel) Search: Defined as an automatic search process to combine different possible features or kernel functions to help improve the accuracy of a specific application (e.g. object classification). A few successful approaches were: Feature selection methods [6] and Multiple Kernel Models [7]. These processes turn out to be very computational intensive but quite helpful in boosting the accuracy of the computer vision models. Another main constraint was that the building blocks of the search space (the features and kernel functions) were manually designed based on human intuition of visual recognition. But there are some evidences that we as humans may not understand in terms of how we are actually distinguishing categories of objects. For example, can you tell yourself how you would discriminate between pictures of dogs versus cats? Any feature that you pick (e.g. sharpness on the ear, or shapes and color in eyes,…), you would find either dogs or cats who have similar features but yet immediately you are able to say it is a dog or a cat without clearly knowing why. That was the motivation for a few scientists to walk away from the traditional approach of designing feature-driven computer vision algorithms from the bottom up and instead move to the next stage of letting the computer design the features itself.

Feature combination and multiple kernel models (Image from Kavak et al. ISACS2013)
3- Feature (Kernel) Learning: This is the automatic process of determining visual features from a high-dimensional vector space that explains the semantic content of an image, which enables computers to perform specific tasks, such as object classification. This capability became possible through the evolution of deep convolutional neural network architectures (CNN). These approaches are sometimes referred to as end-to-end models because there is no human intervention in the process of designing features. In fact, the constructed features are barely interpretable by humans. This process is highly computationally intensive and demands large amounts of data to train the underlying neural network. However, progress in parallel processor hardware (e.g. GPUs and TPUs) and the availability of large scale data sets has made this a viable and successful technique.

Feature learning by deep neural network
That is great!!! Deep learning appears to do the job by itself. But now you may ask what is the role of the computer vision scientists?! Easy, If we replace the word “Feature (kernel)” with the word “Architecture”, in all three aforementioned stages, we can illustrate the trend in the modern AI model development after deep learning. Let's see:
1- Architecture Engineering: This is pretty much the same as the “Feature (kernel) learning” stage. The manual process of designing the architecture of a convolutional neural network for a specific task. The main finding was that a simple but deeper (i.e. more layers) architecture can gain a higher accuracy. At this stage, designing the architecture and training (network optimization) techniques was the major science behind the computer vision (and many other DCNN applications). These network designs were based on a human intuition of how a visual recognition system should work. Some successful architecture designs were: AlexNet [9], VGGNet [9], GoogleNet [10], and ResNet [11]. The main constraint for these models was the computational complexity. These models typically run billions of arithmetic operations (floating point operations) to process a single image. Therefore, in practice, to enable these models to run fast enough for real-world applications, one needs to use GPUs and consume a lot of power. Hence, modern AI was mostly accessible through strong server machines in the cloud. That was a motivation for scientists to design more efficient AI models to run on edge devices. Some successful models were: Xnor-net [12], Mobilenet [13] and Shufflenet [14]. Similar to the “feature (kernel) engineering” stage, after a few years, researchers ran out of ideas for designing architectures and move to the “search” stage.

After deep learning, the fundamental science behind computer vision was designing network architecture (Image by Joseph Cohen)
2- Architecture Search: This is the current stage at the state-of-the-art AI model. The main idea here is to use the building blocks of the previously successful architectures and try to automatically search for a combination of those blocks to structure a new neural network architecture. The key objective is to arrive at an architecture that contains fewer arithmetic operations and achieves higher accuracy. Some successful neural architecture search approaches are: NASNet [15], MNASNet [16], and FBNet [17]. Training these models demands even more computation and data than standard deep learning models, because the search space of possible combinations of neural network blocks is prohibitively large. Similar to the “feature (kernel) search” stage, these models are constrained by the manual design of their building blocks, which are still based on human intuitions. Based on previous approaches, there is strong evidence that humans do not have the best intuition on how to design neural architecture. Recent research in [19] shows that a randomly wired neural network could outperform several human engineered architecture design.
Based on everything we have learnt from the evolution of computer vision techniques, clearly the next phase for deep learning is to let the computer design the architecture itself.
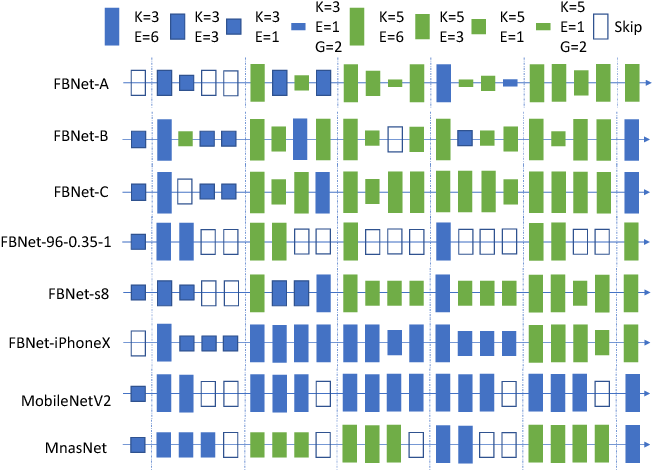
Searching for a combination of different building blocks of CNNs to create a better CNN model (Image from [17])
3- Architecture Learning: Very recently we at Xnor.ai and Allen Institute for AI built a new mechanism called Discovering Neural Wirings [18] for automatically learning the optimal architecture of a neural network directly from data. In this mechanism, we consider a neural network as an unconstrained graph and relax the typical notion of layers and instead enable nodes (e.g. channels of images) to form connections independent of each other. This enables a much larger space of possible networks. The wiring of this network is not fixed during training — as it learns the network parameters it also learn the structure itself. This structure can include loops in the graph which forms a notion of a memory structure. The learned architectures have highly sparse structure thus it will be a much smaller model in terms of the arithmetic operations but still achieves a superior accuracy. The code and experiments can be found at https://github.com/allenai/dnw. Of course, similar to the “feature (kernel) learning” stage, this stage of deep learning demands a lot more computation in training for processing large-graphs and require more data. We believe that as hardware specialized in sparse graph computation evolves, it will unlock even more potential for automatically uncovering the optimal network architecture for highly accurate, computationally efficient edge AI models.

Neural architecture learning is the process of discovering the minimal wirings between the neurons in a full neural graph from data.
Reference:
[1] Lowe, David G. “Object recognition from local scale-invariant features.” iccv. Vol. 99. №2. 1999.
[2] Dalal, Navneet, and Bill Triggs. “Histograms of oriented gradients for human detection.” 2005.
[3] Belongie, Serge, Jitendra Malik, and Jan Puzicha. “Shape context: A new descriptor for shape matching and object recognition.” Advances in neural information processing systems. 2001.
[4] Shawe-Taylor, John, and Nello Cristianini. Kernel methods for pattern analysis. Cambridge university press, 2004.
[5] Maji, Subhransu, Alexander C. Berg, and Jitendra Malik. “Classification using intersection kernel support vector machines is efficient.” 2008 IEEE conference on computer vision and pattern recognition. IEEE, 2008.
[6] Guyon, Isabelle, and André Elisseeff. “An introduction to variable and feature selection.” Journal of machine learning research 3.Mar (2003): 1157–1182.
[7] Gehler, Peter, and Sebastian Nowozin. “On feature combination for multiclass object classification.” 2009 IEEE 12th International Conference on Computer Vision. IEEE, 2009.
[8] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
[9] Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
[10] Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[11] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[12] Rastegari, Mohammad, et al. “Xnor-net: Imagenet classification using binary convolutional neural networks.” European Conference on Computer Vision. Springer, Cham, 2016.
[13] Howard, Andrew G., et al. “Mobilenets: Efficient convolutional neural networks for mobile vision applications.” arXiv preprint arXiv:1704.04861 (2017).
[14] Zhang, Xiangyu, et al. “Shufflenet: An extremely efficient convolutional neural network for mobile devices.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[15] Zoph, Barret, and Quoc V. Le. “Neural architecture search with reinforcement learning.” arXiv preprint arXiv:1611.01578(2016).
[16] Tan, Mingxing, et al. “Mnasnet: Platform-aware neural architecture search for mobile.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[17] Wu, Bichen, et al. “Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search.” arXiv preprint arXiv:1812.03443 (2018).
[18] Wortsman, Mitchell, Ali Farhadi, and Mohammad Rastegari. “Discovering Neural Wirings.” arXiv preprint arXiv:1906.00586(2019).
[19] Xie, Saining, et al. “Exploring randomly wired neural networks for image recognition.” arXiv preprint arXiv:1904.01569(2019).
Mohammad Rastegari
CTO at xnor.ai
Researcher at Allen Institute for AI