| LETTER FROM THE EDITOR |
|
Dear Colleague,
Later today and this Thursday, Lattice Semiconductor will deliver the free webinar "Delivering Milliwatt AI to the Edge with Ultra-Low Power FPGAs" in partnership with the Embedded Vision Alliance. Low power FPGAs are well suited for implementing machine learning inferencing at the edge, given their inherent parallel architecture along with the ability to adapt to evolving deep learning algorithms and architectures. Lattice's iCE40 UltraPlus and ECP5 product families support development of edge AI solutions that consume from 1 mW to 1 W on compact hardware platforms. To accelerate development, Lattice has also brought together the award-winning sensAI stack, which gives designers all of the tools they need to develop low power, high performance edge devices. Two webinar sessions will be offered, the first at 11 am Pacific Time (2 pm Eastern Time) today, Tuesday, November 19 and the second at 6 am Pacific Time (2 pm Central European Time) this Thursday, November 21. To register, please see the event page for the session you're interested in.
On Tuesday, December 17 at 9 am PT, Hailo will deliver the free webinar "A Computer Architecture Renaissance: Energy-efficient Deep Learning Processors for Machine Vision" in partnership with the Embedded Vision Alliance. Hailo has developed a specialized deep learning processor that delivers the performance of a data center-class computer to edge devices. Hailo’s AI microprocessor is the product of a rethinking of traditional computer architectures, enabling smart devices to perform sophisticated deep learning tasks such as imagery and sensory processing in real time with minimal power consumption, size and cost. In this webinar, the company will navigate through the undercurrents that drove the definition and development of its AI processor, beginning with the theoretical reasoning behind domain-specific architectures and their implementation in the field of deep learning, specifically for machine vision applications. The presenters will also describe various quantitative measures, presenting detailed design examples in order to make a link between theory and practice. For more information and to register, please see the event page.
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
| MACHINE LEARNING FOR VISION |
|
An Introduction to Machine Learning and How to Teach Machines to See
What is machine learning? How can machines distinguish a cat from a dog in an image? What’s the magic behind convolutional neural networks? These are some of the questions Facundo Parodi, Research and Machine Learning Engineer at Tryolabs, answers in this introductory talk on machine learning in computer vision. Parodi introduces machine learning and explores the different types of problems it can solve. He explains the main components of practical machine learning, from data gathering and training to deployment. Parodi then focuses on deep learning as an important machine learning technique and provides an introduction to convolutional neural networks and how they can be used to solve image classification problems. He also touches on recent advancements in deep learning and how they have revolutionized the entire field of computer vision.
Machine Learning-based Image Compression: Ready for Prime Time?
Computer vision is undergoing dramatic changes because deep learning techniques are now able to solve complex non-linear problems. Computer vision pipelines used to consist of hand engineered stages mathematically optimized for some carefully chosen objective function. These pipelines are being replaced with machine-learned stages or end-to-end learning techniques where enough ground truth data is available. Similarly, for decades image compression has relied on hand crafted algorithm pipelines, but recent efforts using deep learning are reporting higher image quality than that provided by conventional techniques. Is it time to replaced discrete cosine transforms with machine-learned compression techniques? This talk from Michael Gormish, Research Manager at Clarifai, examines practical aspects of deep learned image compression systems as compared with traditional approaches. Gormish considers memory, computation and other aspects, in addition to rate-distortion, to see when ML-based compression should be considered or avoided. He also discusses approaches using a combination of machine learned and traditional techniques.
|
| EMBEDDED CAMERA DESIGN AND USAGE |
|
Introduction to Optics for Embedded Vision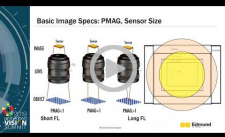
This talk from Jessica Gehlhar, formerly an imaging engineer at Edmund Optics, provides an introduction to optics for embedded vision system and algorithm developers. Gehlhar begins by presenting fundamental imaging lens specifications and quality metrics such as MTF. She explains key parameters and concepts for specifying off-the-shelf or custom optics. Some optical design basics and trade-offs will be introduced. Gehlhar also explores manufacturing considerations, including testing the optical components in your product, and the industrial optics used for a wide range of manufacturing tests. These tests and calibrations become important with designs that include multi-camera, 3D, color and NIR.
Accessing Advanced Image Processing Feature Sets with Alvium Cameras Using a V4L2/GenICam Hybrid Driver
Camera device drivers are a critical component for all embedded vision systems, providing an essential interface between the camera and the application software. In this talk, Sebastian Günther, Host Systems Competence Center Lead at Allied Vision Technologies, begins by examining the key challenges associated with camera drivers for embedded vision systems. He then introduces two approaches to camera drivers: one based on V4L2 (a popular Linux API), and one based on GenICam (a formal standard created for the industrial machine vision space). Günther examines the pros and cons of these two approaches, and presents a hybrid solution that combines support for both V4L2 and GenICam in a single driver. Such a driver is included as part of the software stack provided with Allied Vision’s Alvium embedded vision cameras. Günther introduces these Alvium cameras and illustrates how the hybrid driver can be used to enable developers to utilize the best capabilities of both V4L2 and GeniCam APIs, while minimizing integration effort.
|
| UPCOMING INDUSTRY EVENTS |
|
Lattice Semiconductor Webinar – Delivering Milliwatt AI to the Edge with Ultra-Low Power FPGAs: November 19, 2019, 11:00 am PT and November 21, 2019, 6:00 am PT
Hailo Webinar – A Computer Architecture Renaissance: Energy-efficient Deep Learning Processors for Machine Vision: December 17, 2019, 9:00 am PT
Embedded AI Summit: December 6-8, 2019, Shenzhen, China
Embedded Vision Summit: May 18-21, 2020, Santa Clara, California
More Events
|
| VISION PRODUCT OF THE YEAR SHOWCASE |
|
Xilinx's AI Platform (Best Cloud Solution)
Xilinx's AI Platform is the 2019 Vision Product of the Year Award Winner in the Cloud Solutions category. Xilinx’s AI Platform provides a comprehensive set of software and IP to enable hardware accelerated AI inference applications. AI vision applications, which rely on convolutional neural networks, are a major target for the Xilinx AI Platform. The platform provides the tools and sample AI models that allow developers to build and optimize vision-based AI applications including classification, object detection and scene segmentation. Additional examples of vision-based AI applications enabled by the platform include pedestrian detection, facial recognition and pose estimation. For all of these application sets, the platform provides software, IP and example models, which allows AI developers to use Xilinx adaptable hardware to build the most efficient hardware-accelerated AI-vision applications. The Xilinx AI Platform provides the industry’s first dual hardware and software optimizer.
Please see here for more information on Xilinx and its AI Platform. The Vision Product of the Year Awards are open to Member companies of the Embedded Vision Alliance and celebrate the innovation of the industry's leading companies that are developing and enabling the next generation of computer vision products. Winning a Vision Product of the Year award recognizes leadership in computer vision as evaluated by independent industry experts.
|
| FEATURED NEWS |
|
RealNetworks' SAFR Transforms Global Cities to Be Smarter and More Secure with AI-Based Video Intelligence Powered by NVIDIA
Intel Speeds AI Development, Deployment and Performance with New Class of AI Hardware from Cloud to Edge
OmniVision Expands Machine Vision Global Shutter Image Sensor Family with New Lightguide-Integrated Sensor for Improved Optical Performance and Shutter Efficiency
Hailo Recognized as CES 2020 Innovation Awards Honoree in Embedded Technologies Category
NVIDIA Announces Jetson Xavier NX, World’s Smallest Supercomputer for AI at the Edge
More News
|
