This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Qualcomm Technologies contributes Hexagon DSP improvements to the open source Apache TVM community to scale AI
AI is revolutionizing industries, products, and core capabilities by delivering dramatically enhanced experiences. However, to make AI truly ubiquitous, it needs to run on the end device within a tight power and thermal budget. This is the challenge that Qualcomm Technologies has been laser focused on for many years. In fact, our 5th generation Qualcomm AI Engine in Qualcomm Snapdragon 865 is the culmination of over a decade of AI research combined with our core competency in power-efficient computing.
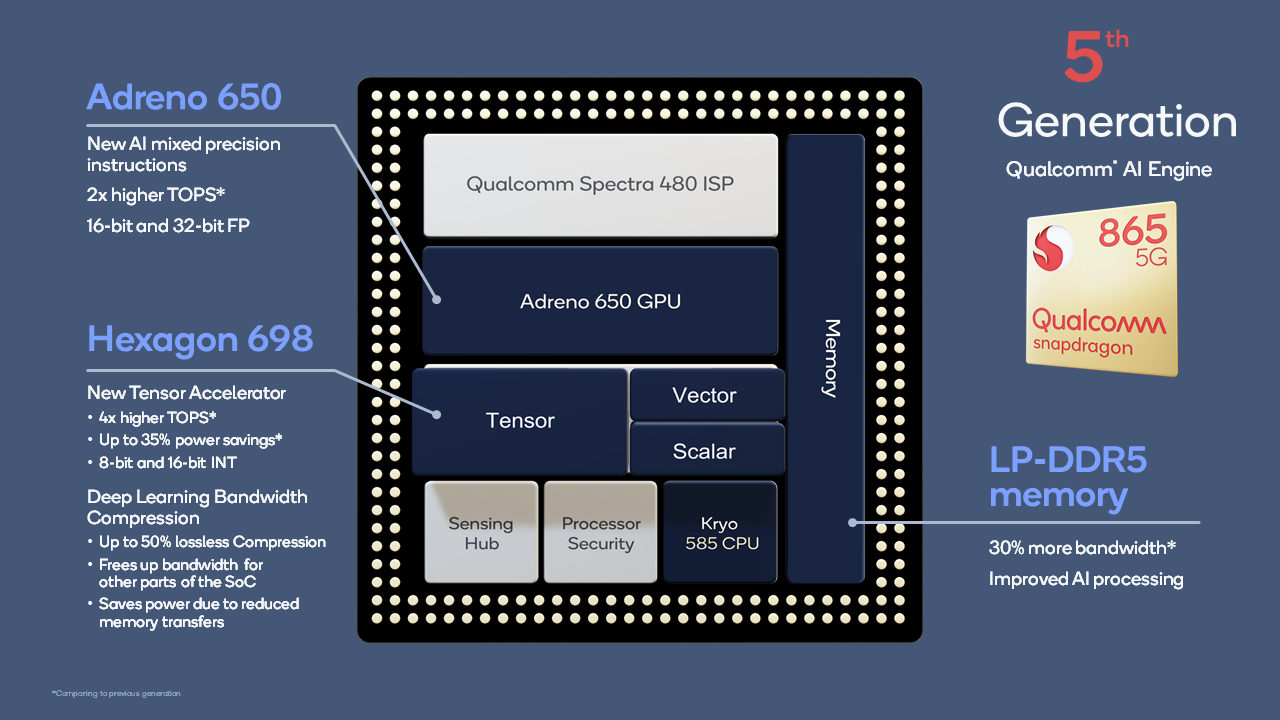
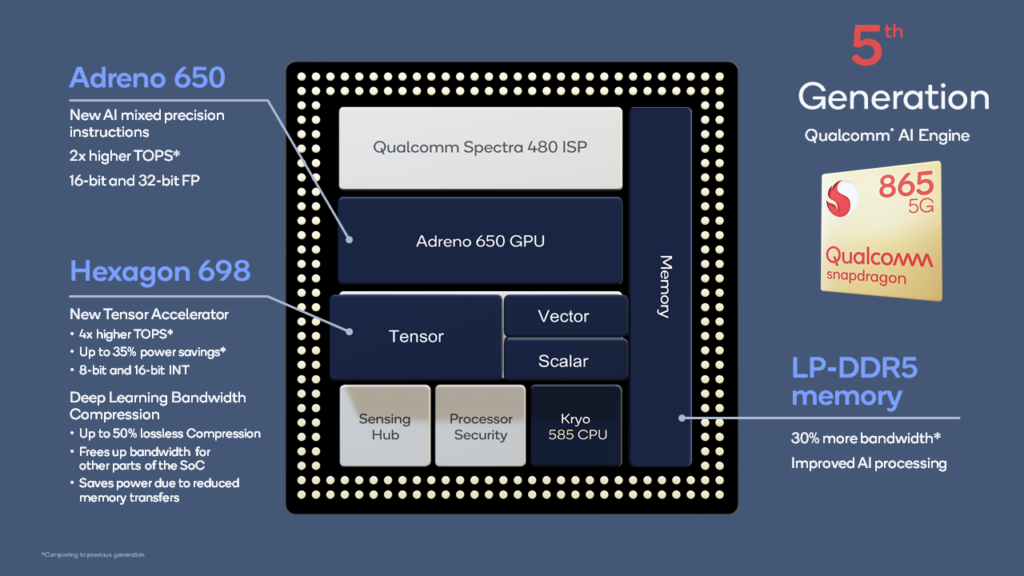
Figure 1: The 5th generation AI Engine offers new advancements to increase AI performance per watt
Taking a holistic approach for power efficiency and performance
The Qualcomm AI Engine is comprised of several hardware and software components to accelerate AI. On the hardware side, we have a heterogeneous computing architecture that includes the Hexagon DSP, Qualcomm Adreno GPU, and Qualcomm Kryo CPU – each of which is engineered to run AI applications quickly and efficiently on-device. It goes beyond great hardware to scale AI to the masses.
To make hardware accessible to programmers, we also need compilers, programming models, and software tools. This allows software developers to exploit our cutting-edge AI hardware and author power-efficient, high-performance AI user experiences on smartphones and other edge devices. To that end, we are investing in the TVM deep learning compiler, which we’ll get to shortly. In terms of open source community development, Qualcomm Innovation Center (QuIC) has open sourced the AI Model Efficiency Toolkit, which provides a simple library plugin for AI developers to utilize for state-of-the-art quantization and compression techniques.
Taking a holistic approach across hardware, software, and algorithms has really paid off. In February 2020, the flagship phones performing best in AI benchmarks are powered by Snapdragon (Figure 2). We’re pleased to see that our leading performance in benchmarks is also carrying over to real-world applications, which is what really matters. Challenging AI applications that previously were not feasible on a smartphone, like style transfers on Snapchat and real-time translation on Youdao, are seeing significant speedup and power efficiency on Snapdragon 865.
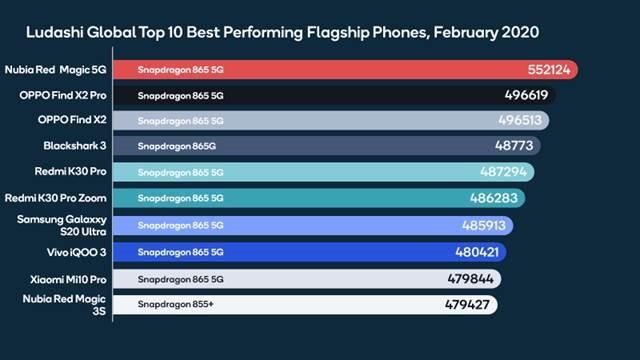
Figure 2: Snapdragon powers the flagship smartphones that lead in the Ludashi AI benchmark
On the compilation front, we’ve invested heavily in TVM to help developers, ISVs, and OEMs take advantage of the hardware acceleration on Snapdragon. In this blog post, we’ll discuss the Hexagon DSP improvements for TVM we’re contributing, our collaboration with the open source community, and how to get started.
Our TVM deep learning compiler contribution for Hexagon DSP
Qualcomm Technologies began development of the Hexagon DSP processor architecture and high-performance implementation in 2004. It started out as a processor with both CPU and DSP functionality to support deeply embedded processing needs of the mobile platform for both multimedia and modem functions. The Hexagon DSP ISA evolved significantly over the years to efficiently process ever-changing requirements for a variety of use cases, such as image enhancement, computer vision, augmented reality, video processing, and sensor processing. The last several generations of the Hexagon DSP enhancements have been focused on efficiently accelerating AI inference. The Hexagon 698 DSP, for example, includes Hexagon Vector eXtensions (HVX) that provide wide-vector processing to accelerate multiply accumulates at low power.
Our open source contribution to TVM unlocks the power efficiency of the Hexagon DSP for the entire community. The contribution includes a runtime and code generator for Hexagon DSP. We will continue to engage with the open source community to expand the capabilities of the TVM compiler for Hexagon DSP.
Developers, ISVs, and OEMs can benefit tremendously from this compiler contribution. It is designed to significantly simplify software development and reduce friction for targeting devices powered by Snapdragon by automatically unlocking the AI hardware acceleration. With these optimizations, your AI applications can see big improvement in performance per watt. Your end customers should be happy to see the result, whether it be longer battery life, higher inferences per second, or lower latency. And since Hexagon DSP is in 100s of millions of devices, these optimizations can have tremendous scale. We plan to continue to grow our open-source efforts and contributions to the community.
Getting started: How to include Hexagon DSP optimizations in TVM compilation
By following these instructions, you will be able to run simple TVM programs either on the simulator or on a target device. All the pieces needed to do it are already present in the TVM open source repository. To get started you will need:
- Hexagon SDK 3.5.0
- LLVM compiler that supports:
- Hexagon and x86 when using Hexagon simulator, or
- Hexagon and AArch64, if using a Snapdragon development board or device
The preparation will require building several components:
- TVM runtime for Hexagon (instructions are available in TVM’s GitHub repository)
- TVM runtime for either x86 or Android with support for Hexagon enabled
- Simulator driver program (sim_dev) when using Hexagon simulator
- Setting up the environment via several environment variables
This is all you need to run TVM programs on Hexagon DSP. Here’s an example of a matrix multiplication program authored for execution on the Hexagon DSP simulator:
import tvm
import tvm.contrib.hexagon
import numpy as np
from tvm import te, tir
# Size of the matrices.
N = 32
# Construct the TVM computation.
A = te.placeholder((N, N), name='A', dtype='int16')
B = te.placeholder((N, N), name='B', dtype='int16')
k = te.reduce_axis((0, N), name='k')
# Provide the function that calculates element at position i,j of the output:
# the dot product of the i-th row of A and j-th column of B.
C = te.compute((N,N), lambda i, j: te.sum(A[i][k] * B[k][j], axis=k), name='C')
# Create the schedule.
s = te.create_schedule(C.op);
px, x = s[C].split(s[C].op.axis[0], nparts=1)
s[C].bind(px, te.thread_axis("pipeline"))
target = tvm.target.hexagon('v66', hvx=0)
f = tvm.build(s, [A, B, C], target=target, target_host='llvm', name='mmult')
# Prepare inputs as numpy arrays, and placeholders for outputs.
ctx = tvm.hexagon(0)
a = np.random.randint(0, 16, (N, N), dtype=np.int16)
b = np.random.randint(0, 16, (N, N), dtype=np.int16)
c = tvm.runtime.ndarray.empty((N, N), dtype='int16', ctx=ctx)
print(a)
print(b)
# Invoke the matrix multiplication via function f and through numpy.
f(tvm.runtime.ndarray.array(a, ctx=ctx), tvm.runtime.ndarray.array(b, ctx=ctx), c)
npc = np.matmul(a, b)
print('tvm\n', c.asnumpy())
print('numpy\n', npc)
# Report error if there is any difference in the two outputs.
if not (c.asnumpy() - npc).any():
print('correct')
else:
print('wrong')
What’s next
This is just the start. We’re truly excited to see what the community of ML developers, application writers, and TVM users will do with the TVM compiler for Hexagon DSP. We can’t wait to engage with the community, see what others contribute, and have people use our code! Get started now by downloading the TVM compiler.
Krzysztof Parzyszek
Compiler and Machine Learning Tool Developer, Hexagon Digital Signal Processor, Qualcomm