
This technical article was originally published by SmartCow AI Technologies. It is reprinted here with the permission of SmartCow AI Technologies.
On March 22th 2022, NVIDIA announced the availability of its new edge computing platform, the Jetson AGX Orin™ developer kit. The production version is being released on Q4 2022 at roughly the same price as the AGX Xavier™. NVIDIA claims this new product to be ‘the world’s most powerful, compact and energy-efficient AI supercomputer’.
In this article, we will introduce this new device and compare its specifications and performance in real world scenarios to its older brother, the NVIDIA® Jetson AGX Xavier™.
Who are we
SmartCow is an AI engineering company that specializes in advanced video analytics, applied artificial intelligence & electronics manufacturing. Established in 2016, SmartCow is a rapidly-growing AI engineering company, It offers vertical solutions to complex real-world problems.
We are a multicultural company with offices across the globe.
A few weeks ago we released the Apollo AI Engineering Kit, based around the NVIDIA® Jetson Xavier NX™. This is a kit enabling developers to build applications with image, conversational, and audio AI capabilities. As a company, we have in-depth knowledge of the Jetson family including its strengths and its limitations. Throughout this article, we will be sharing with you how the new NVIDIA Jetson AGX Orin can be a game changer in the world of edge devices.
Jetson AGX Orin vs Jetson AGX Xavier
Specification Comparison
Let’s first take a look at the technical specifications before we benchmark them.
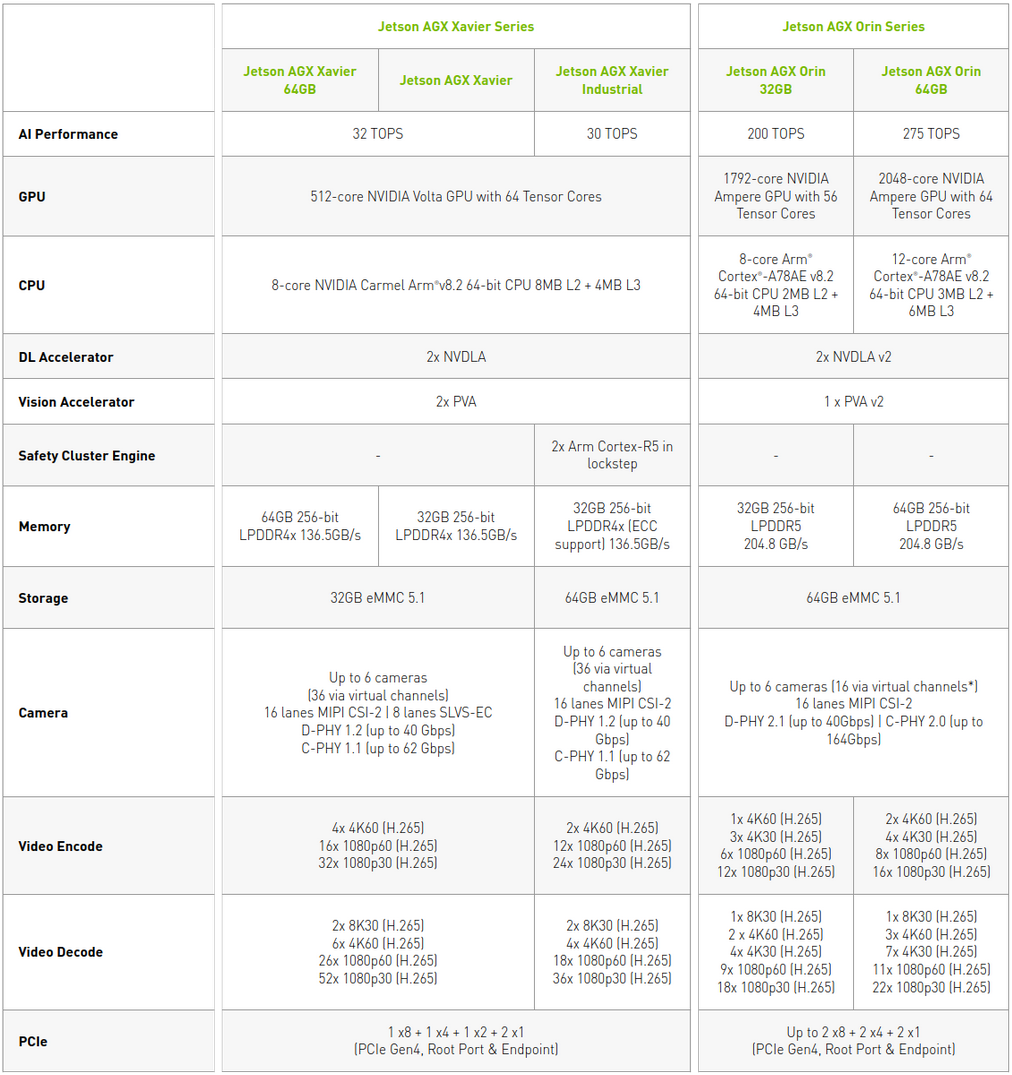
Comparing the specifications of Jetson AGX Orin to Jetson AGX Xavier, we can agree that Jetson AGX Orin is quite promising. It has up to 275 TOPS, which is 8.5x more powerful than the 64GB/32GB versions of the Jetson AGX Xavier. Further more it has the new Cortex CPU with up to 12 cores, LPDDR5 Memory, 64GB eMMC and 2048 core Nvidia Ampere GPU with 64 Tensor Cores + 2 DLA cores V2.0.
Evidently 8x more TOPS does not necessarily mean 8x faster inference time. In fact, in this specification sheet Nvidia made an inference time comparison.

According to the table above and using currently available software, we can expect improvements of up to 3.3x that that can be achieved on the AGX Xavier, and we can hope for better performance with future updates.
The Jetson AGX Orin we have is an engineering sample, not the final production version which is to be released by the end of Q4. The specifications for our device differ slightly from what is shown in the above spec sheet. It has a 12-core Cortex CPU, 2048 cores GPU + 64 tensor cores but unlike the production version, this one has 32GB LPDDR5 memory. You can find the exact specifications here.
Running deviceQuery allows us to get more detailed specifications on the GPU:
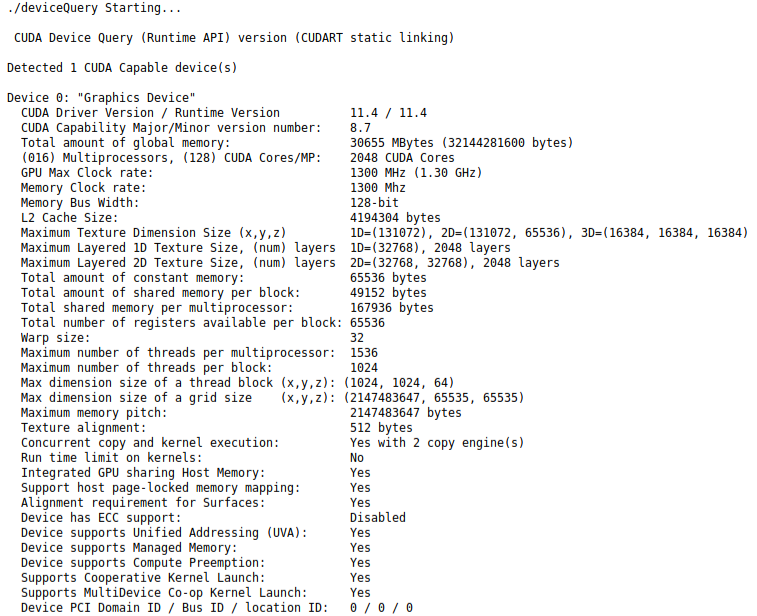
As the control, we will be using a development model 32GB Jetson AGX Xavier, which has 512 cores Volta GPU, 32GB memory & internal storage, an 8 core CPU Carmel and 2 DLA V1 cores leading to an AI performance measurement of 32 TOPS.
To summarise, the Jetson AGX Orin offers 8x TOPS over the Jetson AGX Xavier at almost at the same price point. Promising so far, isn’t it? Based on the benchmarks in the next part, we will have a realistic idea of the performance gain from a Jetson AGX Orin.
Benchmarking
In this section we will run the same scripts on both devices.
Before taking a look at the charts and the actual metrics, let’s have a look at the software environment.
Our Jetson AGX Orin is flashed with is running Linux for Tegra 34 and Jetpack 5.0 (Early Access), with CUDA 11.4 and TensorRT 8.4.0. On the other hand, the Jetson AGX Xavier is flashed with Jetpack 4.6, has CUDA 10.2 and TensorRT 8.0.1. The biggest difference between the two is the TensorRT version which may affect the engine building process. This must be kept in mind when interpreting the results.
At SmartCow, we have several engineers interested in running and sharing experiments, not only during the training phase but also during the production phase. To centralise and share the results, we are using the well-known MLOps platform called Weights & Biases. This platform allows us to put together all the metrics, data and models versions in a “Team” so that we can quickly and easily fetch the information from a common platform. In this article, WandB experiment tracking feature is used for stats visualisation and sharing.
As a side note, every benchmark presented in this article has been run on bare metal; outside of a container.
Now, that we have a good understanding of the devices and the tools that we will use for visualisations, we will be explaining how the performance of each device is calculated.
Firstly, we will run a mask recognition pipeline having two models: a face detection model and a classification network that takes an input of the detected face and determines if the person is wearing a mask or not. Both models are running with TensorRT in fp16 mode. Do not worry, tests with int8 quantised models are coming soon.
We then fed video through this pipeline, and got the below result:
Based on the above video, we cannot easily distinguish any visual differences. Looking at the FPS count however, it is easily apparent that the AGX Orin is much more capable of generating inferences on the input video. As the video was being rendered by the pipeline, the FPS count was broadcast in real time to our WandB server, giving us a clearer idea of the actual behaviour of the models.
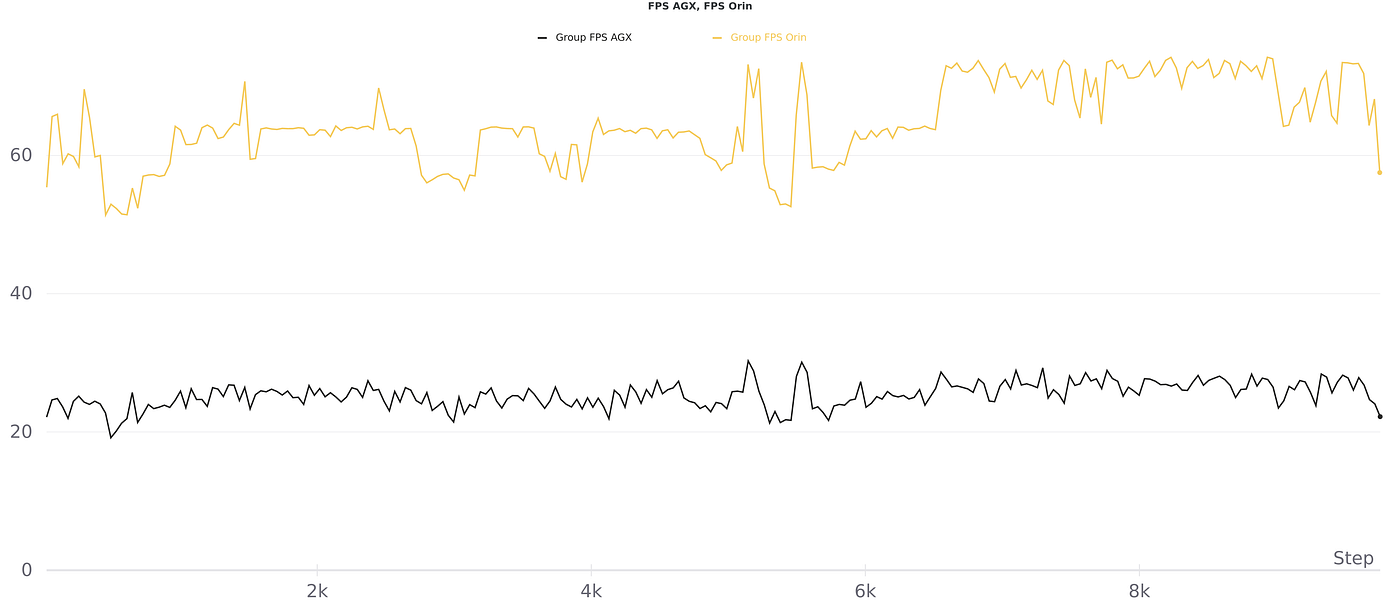
For this first test, it is quite obvious that the Jetson AGX Orin outclasses the AGX Xavier, but we should take a deeper look at the above graphs. As you can see both the average and standard deviation figures are really interesting:
AGX Xavier fps average : 25.334680618048342 AGX Xavier fps std : 2.5580909414300215 AGX Orin fps average : 64.62059476555176 AGX Xavier fps std : 6.366172809817752
We can therefore conclude that in this scenario, the Jetson AGX Orin is 2.66 times faster than the Jetson AGX Xavier, but also a bit less stable.
The next test is a pure TensorRT based inference benchmark of classification models. For those who are familiar with classification at the edge, the EfficientNet family might ring a bell. This famous classification model is well known to provide an incredibly good accuracy with very low latency. It is also a known fact that post quantisation, the vanilla EfficientNet models will result in accuracy loss because of the Swish activation functions and SENet keeping your models stuck at fp16 until QAT is mastered.
We will consider both fp16 and int8 models. For these tests, we will use two different families of EfficientNet — the vanilla versions from B0 to B4 and the lite versions from lite0 to lite4. I strongly invite you to take a look at this repository of EfficientNet-lite if you’re curious about in the implementations of these networks. Furthermore, in a real life scenario the quantization method would be different from vanilla models (QAT) and lite models (PTQ), and thus we have decided to quantize both model families using the same PTQ method (same images, parameters…). This will yield comparable results.
When deploying classification models on embedded devices we usually convert them into fp16 or int8 and change the input size. This is done because it is proven that there is a correlation between input size, accuracy and inference time. This means that the bigger the size of the input, the more accurate the model might be, at the cost of significantly longer inference times. Another parameter that impacts inference time and accuracy is the size of the model itself (B0, B1, …). Because of this, it is always good practice to benchmark all combinations before choosing the one that suits your needs.
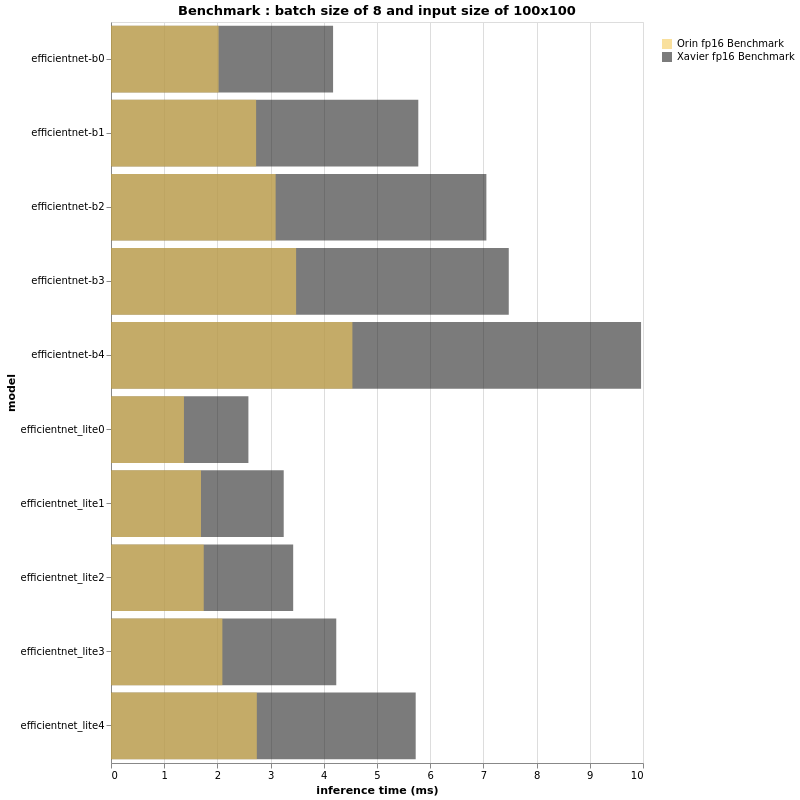
For example, an EfficientNet-B2 with an input size of 100×100 can be as fast as an EfficientNet-B0 with an input size of 224×224, but B2 will be 0.5% more accurate; This balance between inference time and accuracy is a huge challenge. This is the reason that, for this section, we have decided to show multiple models based on the same structure, with multiple batch sizes and multiple input sizes.
FP16
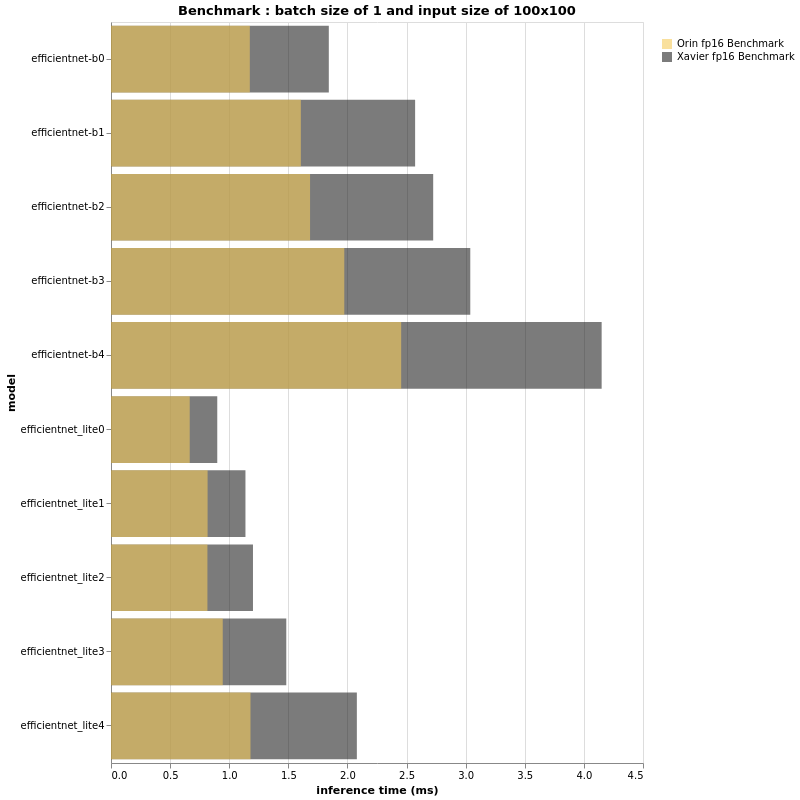 |
 |
 |
 |
 |
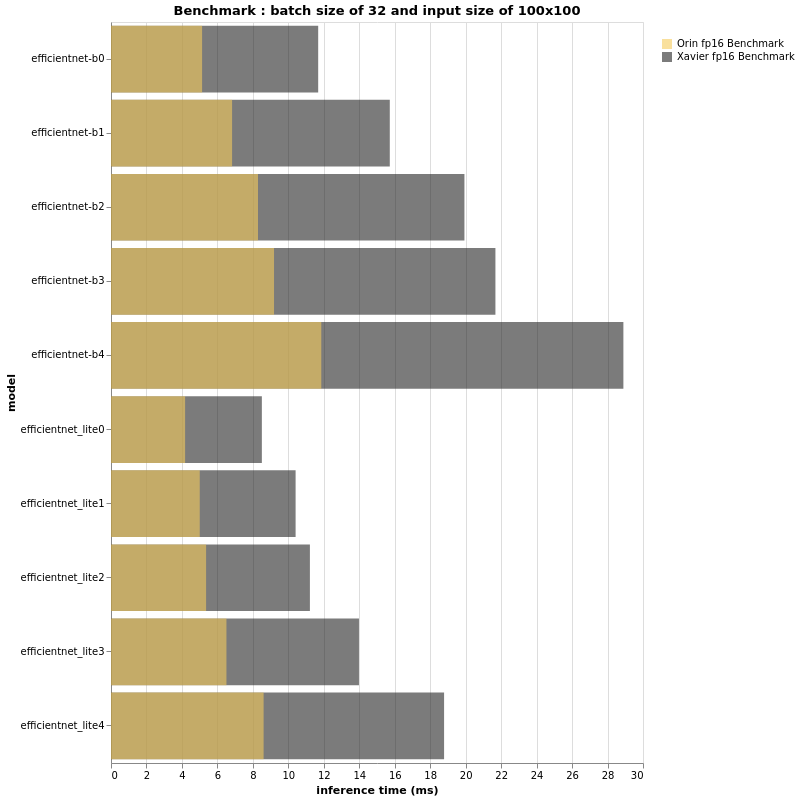 |
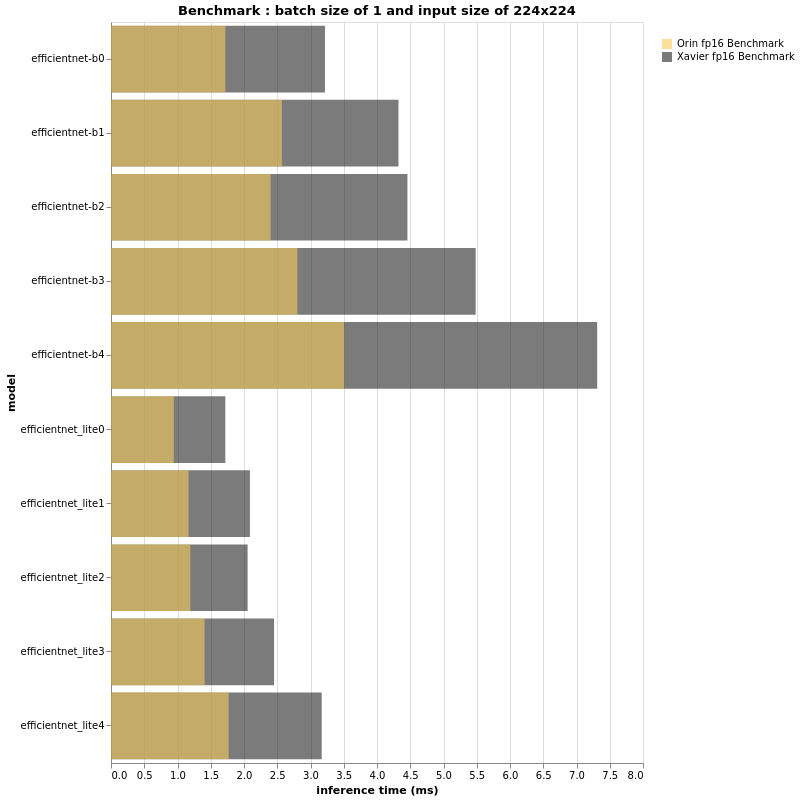
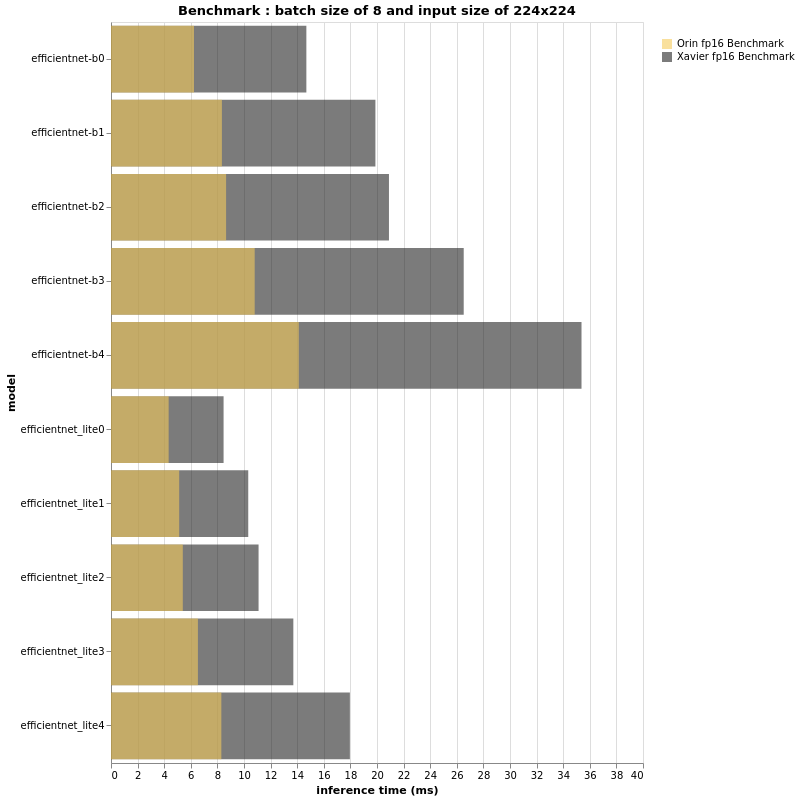
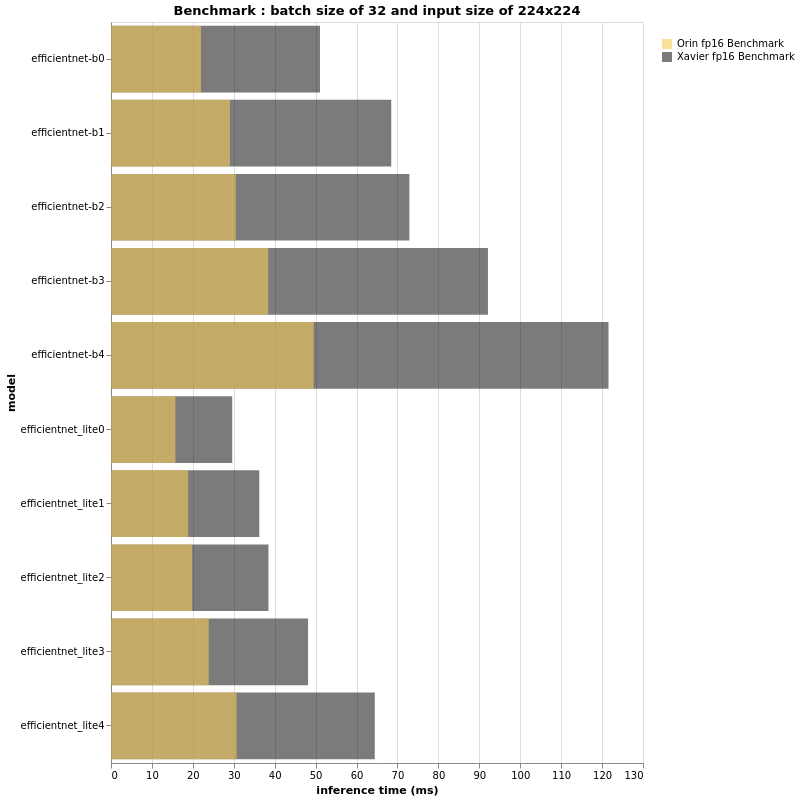
Based on the above beautiful bar-plots, we can definitely conclude a few things.
First, as expected the Jetson AGX Orin is much faster than its brother Jetson AGX Xavier. Having said that, it is yet again proven that TOPS or FLOPS alone cannot give us real performance insight. An EfficientNet-B4, with batch size of 32 and input size of 224×224 is as fast on a Jetson AGX Orin as an EfficientNet-B0 running on Jetson AGX Xavier with the same configuration. Further more, B4 has a top-1 accuracy of 82.9% on ImageNet whereas B0 performs at 77.1%.
Thus, if the FPS performance of your project running on an Jetson AGX Xavier is acceptable and there is no need for more features, you can deploy bigger models and have a more accurate pipeline when using Jetson AGX Orin.
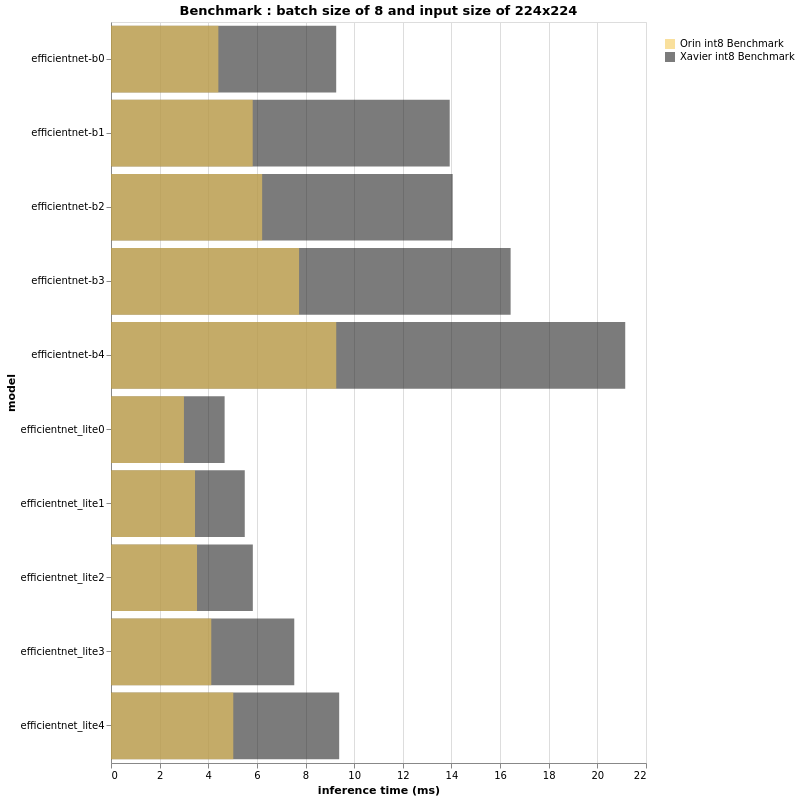
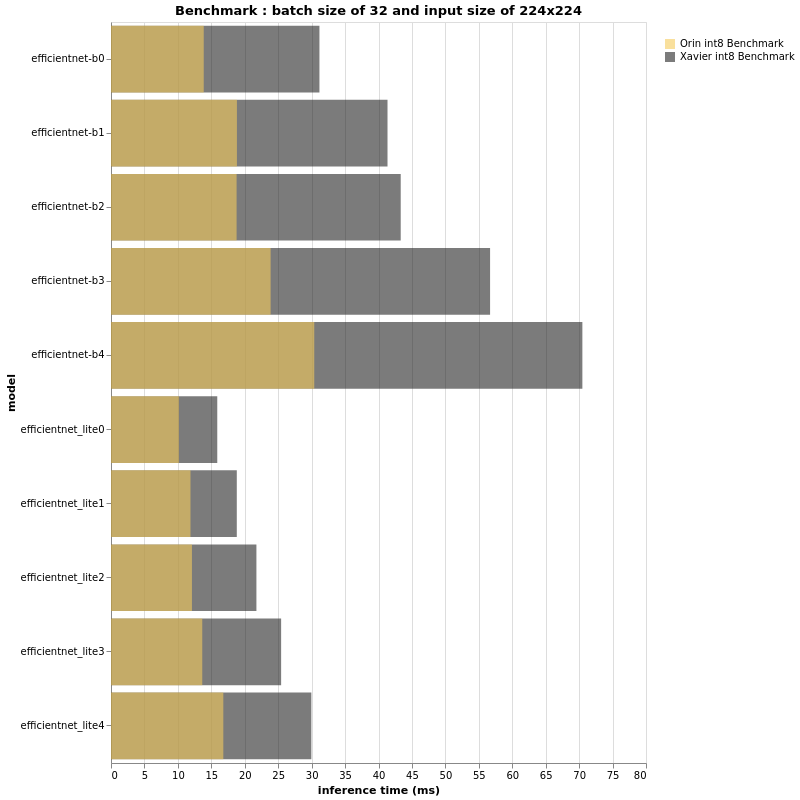
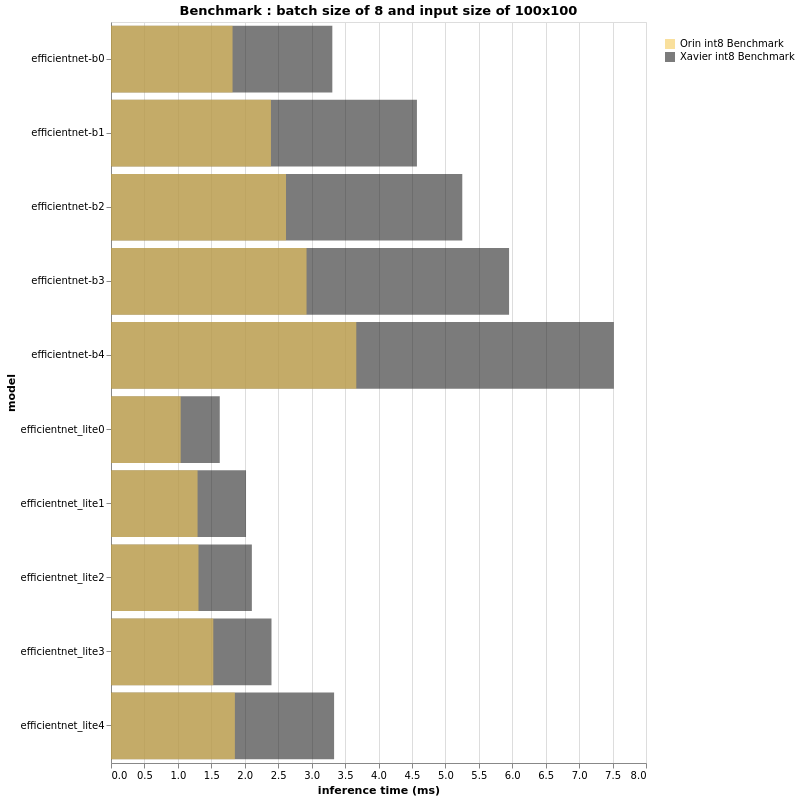
INT8
 |
 |
 |
 |
 |
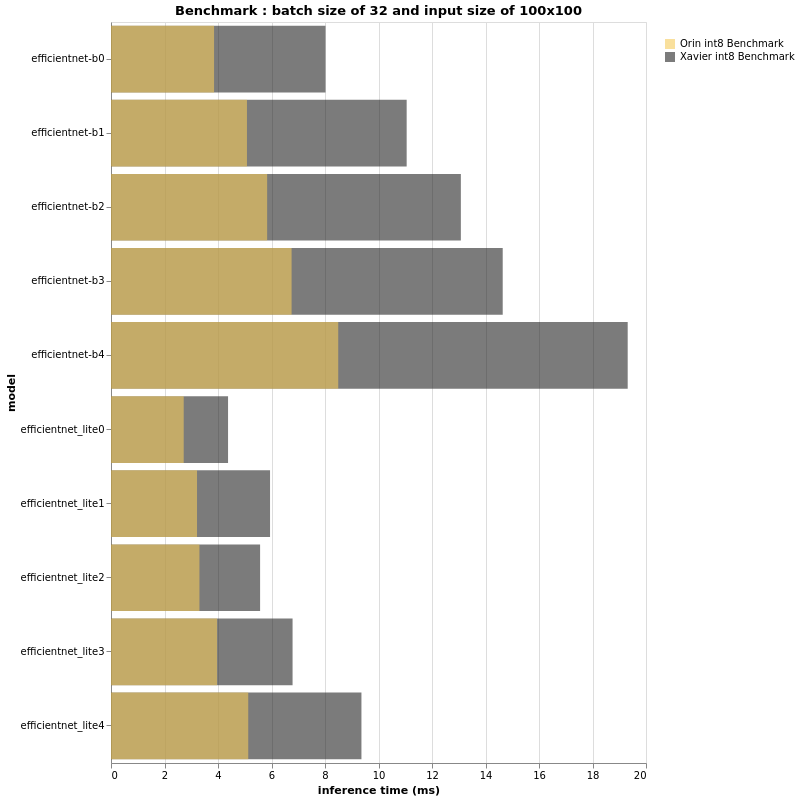 |
The above charts look very similar to the fp16 results, don’t they?
Indeed, the ratio of performance between Jetson AGX Orin & Jetson AGX Xavier in this int8 context is seemingly the same as that for fp16.
However on close observation if the performance ratio is roughly the same, the abscissa axis that measures the inference time is expected to be different, specifically when the batch size and/or the input size is bigger. For both fp16 and int8, the bigger the input size and batch size, the bigger the gap between Jetson AGX Xavier and Jetson AGX Orin.
In conclusion, a small input size and small batch size might not show us a 3x difference in performance. We have experimentally seen that in the case of larger models, Jetson AGX Orin can reach or even surpass 3x better performance when compared with the AGX Xavier.
Based on our tests so far, Jetson AGX Orin appears to be a very promising new addition to the Jetson family; However we are yet to conduct one last test. Since the DLA cores are different we will try to make a fair and solid comparison using the NVIDIA AI IOT jetson_benchmarks. While not designed to support AGX Orin, a bit of modifications to the scripts allow us to run the benchmarks and get the below results:
Xavier AGX :
Model Name FPS
0 inception_v4 458.944580
1 vgg19_N2 320.622839
2 super_resolution_bsd500 292.901820
3 unet-segmentation 231.217034
4 pose_estimation 525.769665
5 yolov3-tiny-416 1008.346186
6 ResNet50_224x224 1711.112646
-----------------------------------------------------
Orin AGX : Model Name FPS
0 inception_v4 1008.721131 (2.2x faster)
1 vgg19_N2 948.223214 (2.9x faster)
2 super_resolution_bsd500 711.692852 (2.4x faster)
3 unet-segmentation 482.814855 (2.1x faster)
4 pose_estimation 1354.188814 (2.6x faster)
5 yolov3-tiny-416 2443.601094 (2.4x faster)
6 ResNet50_224x224 3507.409752 (2x faster)
Conclusion
Same physical size, same price range but more power. Even with an early engineering sample, we have shown through these benchmarks that Orin is an incredibly promising new addition to the Jetson family, and we can expect even better results in a near future with new software updates.
By releasing NVIDIA Jetson AGX Orin, NVIDIA indisputably made the world of embedded AI take a large step forward. Jetson Xavier devices are already incredibly powerful and full of potential, with Orin now paving the way forward for the continuing growth of embedded AI. We can now plan and work on bigger and more complex projects that we could not even dream about previously. For those who were limited by the number of tasks, NVIDIA has pushed the bar higher. In fact, we here at SmartCow are already re-thinking our embedded solutions to propose much more features, better accuracy and reliability, after working with the Jetson AGX Orin for only a few days; it is that much of a game-changer.
Finally, thank you for reading all this! I really hope this was helpful for your next project and deployment plans. If you have any question or suggestions, please leave a comment.