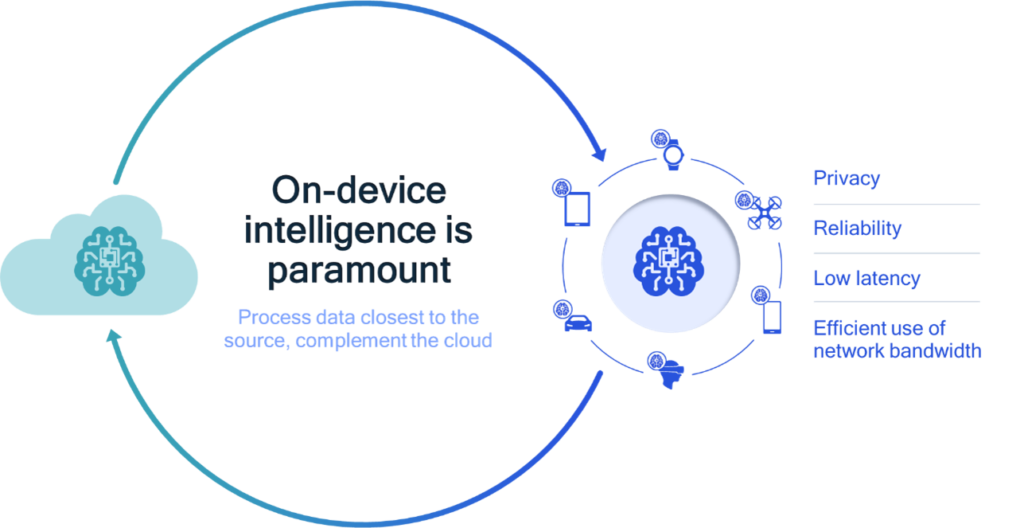
On-device intelligence provides important benefits.
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Our latest AI research to personalize and adapt models while keeping data private
One size doesn’t fit all. The need for intelligent, personalized experiences powered by AI is ever-growing. Our devices are producing more and more data that could help improve our AI-powered experiences. How can we learn and efficiently process all this data from edge devices? On-device learning rather than cloud training can address these challenges. In this blog post, I’ll describe how our latest research is making on-device learning feasible at scale.
What is on-device learning?
In the past, AI was primarily associated with the cloud. We have moved from a cloud-centric AI where all the training and inference occurs in the cloud, to today where we have partially distributed AI with inference happening on both the device and cloud. In the future, we expect not only inference but also the training or adaptation of models to happen on the device. We call this fully-distributed AI, where devices will see continuous enhancements from on-device learning, complementing cloud training. Processing data closest to the source helps AI to scale and provides important benefits such as privacy, low latency, reliability, and efficient use of network bandwidth.
On-device learning modifies the AI model, which was originally trained in the cloud with a global dataset, based on the new local data that a device (or set of devices) encounters. This can improve performance by personalizing to an individual user or adapting a shared model among a group of users and their environment. The AI can also continuously learn over time, adjusting to a world and personal preferences that are dynamic rather than static.
On-device learning is challenging
The benefits of on-device learning are clear. So why aren’t we doing it? The reality is that that there is a number of challenges to overcome to make on-device learning feasible at scale. For example:
- Model training and fine tuning can be power, compute, and storage hungry. This is why learning has traditionally occurred in the cloud on datacenters with much more available resources than edge devices.
- Local data can be limited, unlabeled, biased, and imbalanced, which makes it hard to learn an improved model.
- Overfitting or catastrophic forgetting results in models that are not robust to a variety of situations.
Our research is solving on-device learning challenges
To overcome some of the feasibility and deployment issues for on-device learning, Qualcomm AI Research is actively investigating several topics and seeing very encouraging results.
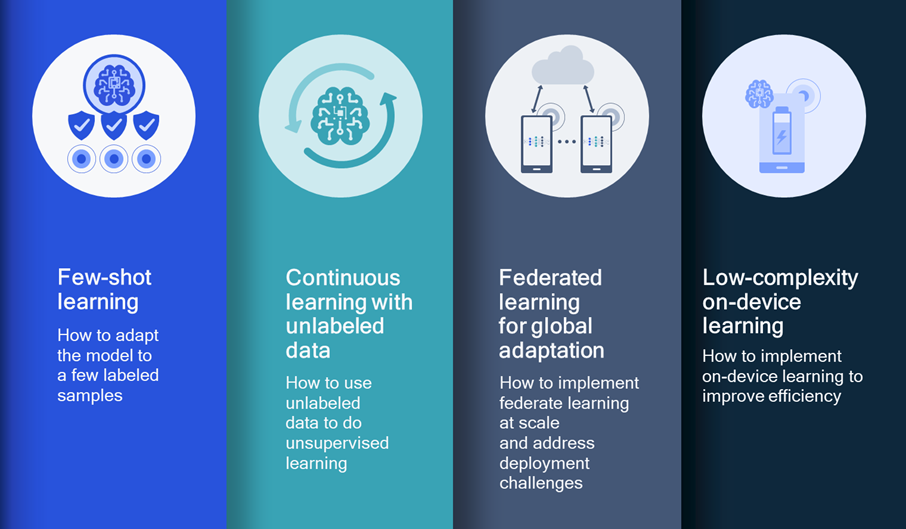
Our AI research areas address the key deployment challenges of on-device learning.
Few-shot learning explores how to adapt the AI model to a few labeled data samples. Learning from limited labeled data is crucial since there may not be as many opportunities for user-assisted labeling. Consider keyword spotting, where the task is to identify when a keyword is spoken, such as “Hey Snapdragon,” using always-on machine learning. A typical keyword-spotting model may not be sensitive to users’ accents and have poor performance for outliers. By using our methods to locally adapt the model to a few examples of the user saying, “Hey Snapdragon,” we’ve seen personalization improvements across the board but particularly for outliers, with up to 30% outlier detection rate gain.
Continuous learning is learning that continues after enrollment with the benefit that the AI model improves and adjusts over time. Continuous learning is also often unsupervised learning, which means the data is unlabeled since it is not practical for users to do enrollments or label data repeatedly. On the positive side, there are often plentiful samples of unlabeled data. To address the training challenge of unlabeled data, our research method assigns pseudo labels to the training data through the verification process. To address the challenge of overfitting and forgetting a useful capability of the model when the number of collected data is small, we exploit regularization loss that maintains some metrics from a pre-trained model.
Federated learning provides the best of both worlds from on-device training and cloud training. It maintains the privacy benefit and scale of on-device learning by keeping the data local, while also getting the benefit of learning from diverse data across many users by having the cloud aggregate many different locally-trained models. Raw data is never sent to the cloud, and model updates can be shared in ways that still preserve privacy.
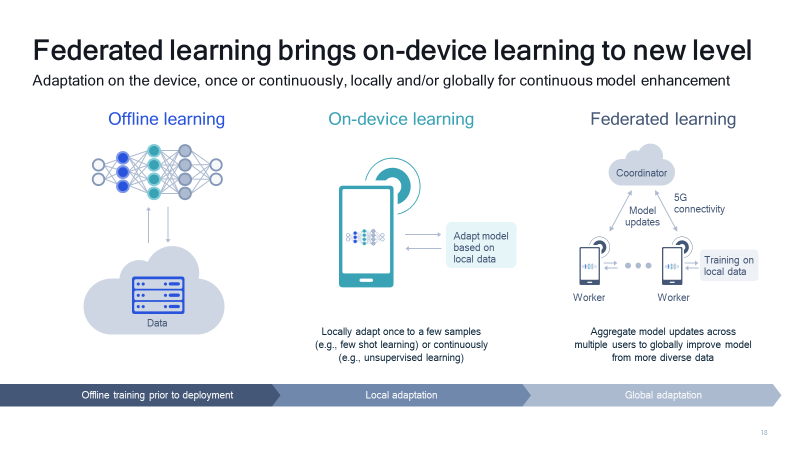
Federated learning aggregates model updates from devices capable of on-device learning.
Of course, the device must be capable of on-device learning for federated learning to work, and there are also many other system challenges for producing a good, federated model. Our research is largely focused on solving these challenges. Consider user verification, where a person is authenticated through biometrics. Deep learning is a powerful tool for user verification but typically requires large amounts of very personal data across a diverse set of users. Federated learning enables the training of such models while keeping all this personal data private. In fact, our user verification models trained with our federated learning methods are able to achieve competitive performance compared to state-of-the-art techniques, which do not preserve privacy. And our research is not all theory. We have developed a federated learning framework for research and application development on mobile, and we will be demonstrating this user verification use case at upcoming conferences. We want to make federated learning available at scale and address deployment challenges.
Low-complexity on-device learning is key to making all three of the learning techniques I described above possible. Backpropagation, which is the technique used during training of AI models, is computationally demanding and challenging to do on most power and thermal-constrained devices.
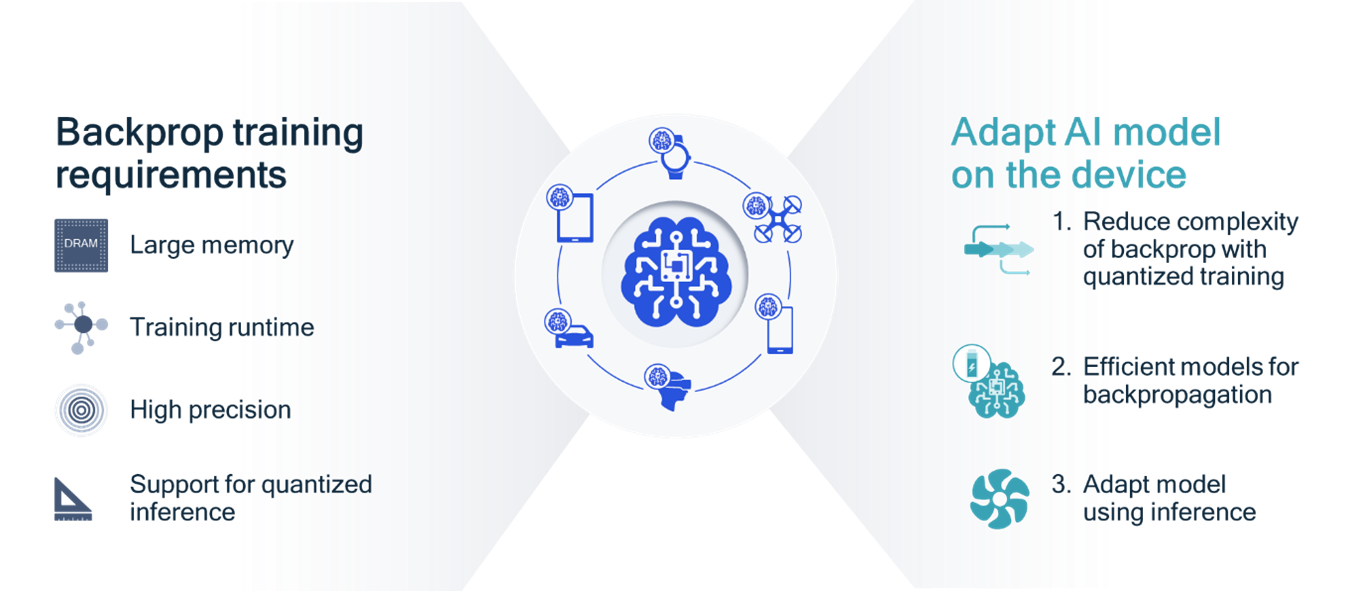
Overcoming challenges to efficiently adapt a neural net on a device.
We’re investigating several approaches to efficiently adapt the AI model on a device, such as quantized training, efficient models for backpropagation, and adaptation based on inference results.
More to come
Overall, we’re very excited about the potential of on-device learning since it can lead to better models that leverage all the data available from edge devices while providing benefits such as privacy, low latency, reliability, and efficient use of network bandwidth. We have a broad range of research directions for on-device and federated learning to ease deployment, make them efficient, and create better AI models. Be sure to tune into my webinar where I will go into much more detail on our research. If we get this right, you can expect enhanced experiences that are continually improving and be able to trust that your personal data is kept safe. We can’t wait to make this a reality.
Dr. Joseph Soriaga
Senior Director of Technology, Qualcomm Technologies