This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Usually, when you’re presented with three options, such as powerful, efficient, and low cost, you’re also faced with the conundrum where you’re only allowed to pick one or two. Machine learning (ML) practitioners developing neural networks for mobile don’t always have the luxury of picking their top one or two choices because their models generally need to be fast, small, and consume low power to be effective.
In our recent blog post, Neural Network Optimization with AIMET, we discussed how Qualcomm Innovation Center’s (QuIC’s) open-source AI Model Efficiency Toolkit (AIMET) provides advanced quantization and compression techniques and how it can be used with the Qualcomm Neural Processing SDK. With AIMET, developers can optimize their ML models to not only reduce their size, but also reduce the amount of power required for inference while maintaining accuracy requirements.
Previously, Qualcomm AI Research published their whitepaper: A White Paper on Neural Network Quantization that provides in-depth treatment of quantization. Their subsequent whitepaper: Neural Network Quantization with AI Model Efficiency Toolkit (AIMET), provides extensive details and a practical guide for two categories of quantization using AIMET:
- Post-training Quantization (PTQ): Analyzes trained neural networks, which use 32-bit floating-point values (aka FP32 networks and FP models), to find and recommend optimal quantization parameters without model retraining or fine-tuning. PTQ methods can be data-free (i.e., don’t require a dataset), or they can use a small calibration dataset to optimize the models for quantized inference.
- Quantization-aware Training (QAT): QAT takes a pre-trained FP32 model, inserts quantization operations at appropriate places to simulate quantization noise, and fine-tunes the model parameters to combat the quantization noise, thus producing a model suited for quantized inference.
In this blog post, we look at the PTQ techniques discussed in the whitepaper, highlighting their key attributes and strengths and when to use them.
Why Quantization?
To understand the significance of PTQ methods, it’s important to remember what quantization is trying to achieve. In a nutshell, quantization involves mapping a set of values from a large domain onto a smaller domain. This allows us to use smaller bit-width representations for these values (e.g., 8-bit integers rather than 32-bit floating point values), thus reducing the number of bits that need to be stored, transferred, and processed. Furthermore, most processors, including the Qualcomm Hexagon DSP found on Snapdragon mobile platforms, generally perform fixed-point (i.e., integer) math much faster and more efficiently than floating-point math.
Since today’s neural networks typically represent weight and activation tensors using 32-bit floating point values, it can be highly beneficial to quantize these values to smaller representations, down to as low as 4-bit.
However, as the whitepaper points out, quantization can introduce noise and thus reduce accuracy. This can happen for various reasons, such as when large outlier values are clipped to quantized ranges. That’s why we’ve put so much effort into advancing quantization methods for different types of neural networks.
PTQ Workflow and Methods
AIMET’s PTQ methods currently include:
- Cross-layer Equalization (CLE)
- Bias Correction
- AdaRound
These methods are intended to be used in different parts of a typical optimization workflow.
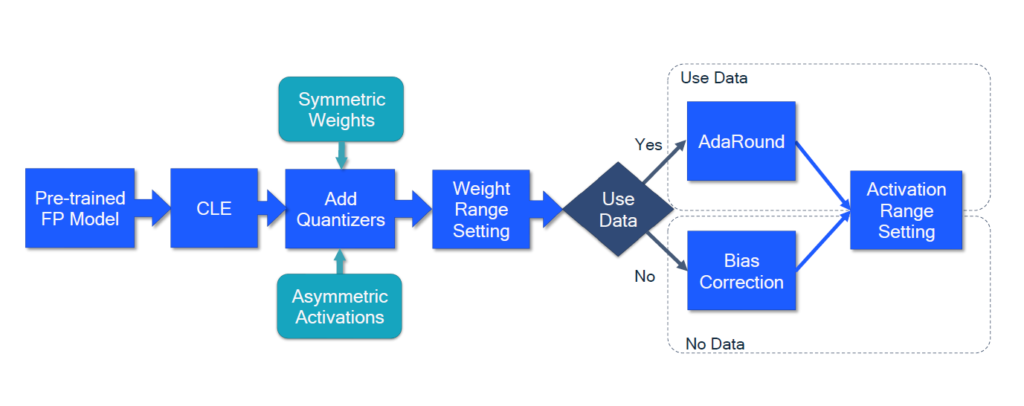
The whitepaper proposes the following workflow for employing AIMET’s PTQ methods:
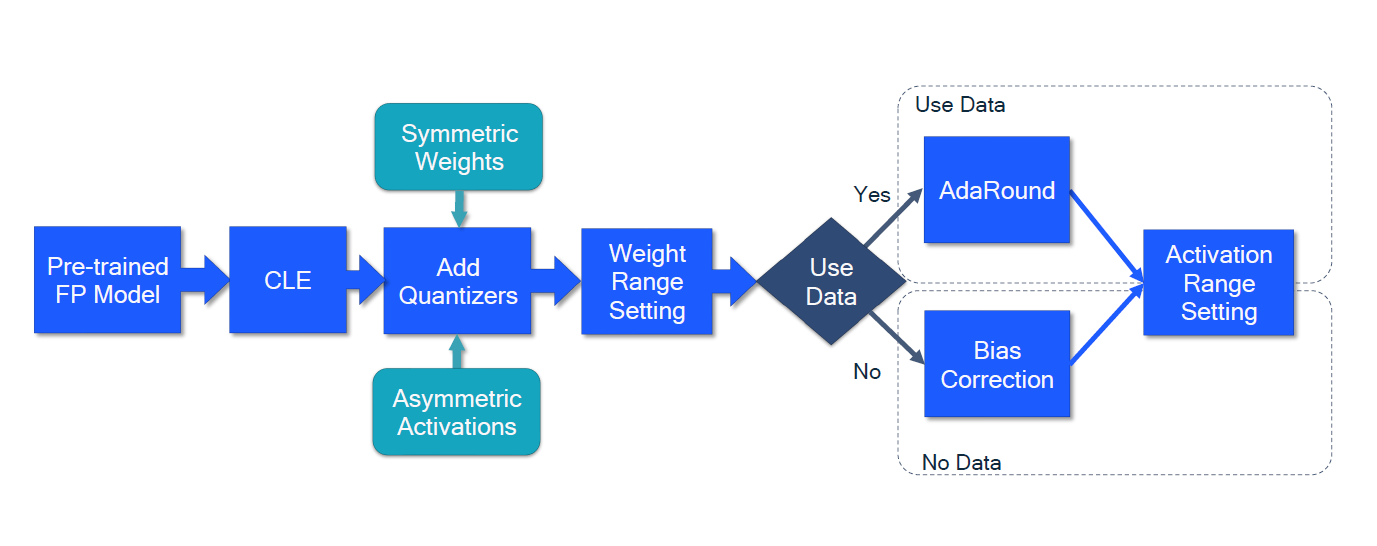
Figure 1 – Workflow that incorporates AIMET’s PTQ methods.
Given a pre-trained FP model, the workflow involves the following:
- AIMET’s Cross-layer Equalization (CLE) pre-processes the FP model making it quantization-friendly.
- Quantization ops are then added to the model to simulate quantization effect and evaluate performance. Quantization ops can be based on a variety of factors (e.g., target hardware).
- Weight ranges for the quantizers are selected to specify clipping thresholds, while ideally reducing rounding errors.
- If data is available, then AIMET’s AdaRound implementation optimizes the rounding of weights instead of performing the typical rounding-to-nearest approach
- If data isn’t available, then analytical Bias Correction can be employed. Bias Correction adapts a layer’s bias parameter to correct for bias in noise introduced through quantization. Bias Correction, in conjunction with CLE, is described in detail in Data-free Quantization (DFQ).
Let’s take a closer look at CLE, Bias Correction, and AdaRound.
Cross-layer Equalization (CLE)
CLE equalizes the weight ranges in the network by using the scale-equivariance property of activation functions (i.e., equalize weight tensors to reduce the amplitude variation across channels). This improves the quantization accuracy performance for many common computer vision architectures. CLE is especially beneficial for models with depth-wise separable convolution layers.
AIMET has APIs for CLE, including the equalize_model() function for PyTorch , as shown in the following code example:
from torchvision import models
from aimet_torch.cross_layer_equalization import equalize_model
model = models.resnet18(pretrained=True).eval()
input_shape = (1, 3, 224, 224)
# Performs batch normalization folding, Cross-layer scaling and High-bias absorption
# It must be noted that above API will equalize the given model in-place.
equalize_model(model, input_shape)
Bias Correction
Bias Correction fixes shifts in layer outputs introduced due to quantization. When noise due to weight quantization is biased, it also introduces a shift, (i.e., bias, in the layer activations). The root cause is often due to clipped outlier values which shift the expected distribution. Bias Correction adapts a layer’s bias parameter using a correction term to correct for the bias in the noise, and thus recovers at least some of the original model’s accuracy.
AIMET supports two Bias Correction approaches:
- Empirical Bias Correction: Uses a dataset to calculate the correct term by comparing activations of quantized and FP models at the expense of additional processing time.
- Analytic Bias Correction: Calculates the biased error through analytics without the need for data. For networks with batch normalization and ReLU activation functions, the mean and standard deviation of the batch normalization are used. AIMET automatically detects candidate convolution layers with associated batch normalization statistics in a given model to perform bias correction.
AdaRound
Typically, quantization projects values from a larger domain onto a smaller domain known as the grid. It then rounds values to the nearest grid point (e.g., a whole number) as shown in Figure 2:
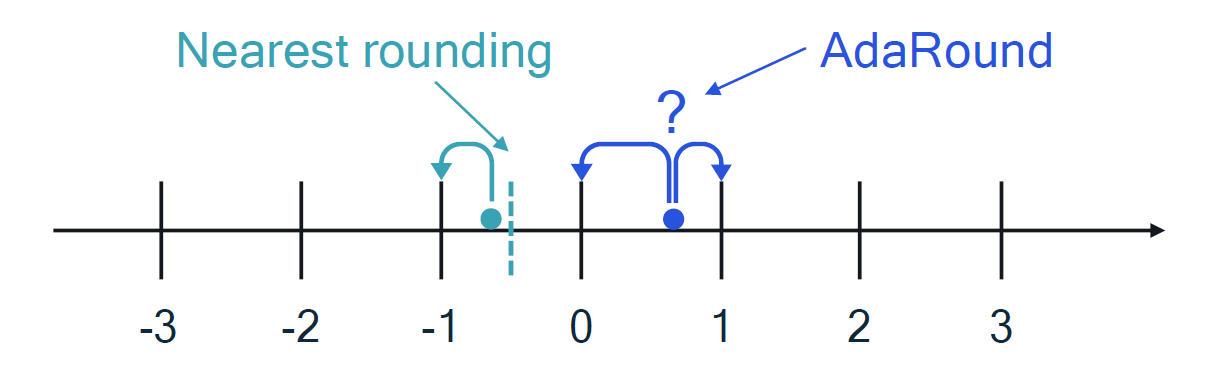
Figure 2 – Visualization of nearest-rounding to a point on the grid during quantization to an 8-bit signed representation.
However, rounding-to-nearest is not always optimal. AdaRound is an effective and efficient method that uses a small amount of data to determine how to make the rounding decision and adapt the weights for better quantized performance. AdaRound is particularly useful for quantizing to a low bit-width, such as 4-bit integer, with a post-training approach.
AIMET provides a high-level API for performing AdaRound that exports a model with updated weights and a JSON file with the corresponding encodings.
For additional information about AdaRound, check out Up or Down? Adaptive Rounding for Post-Training Quantization.
And the Results are in
The whitepaper shows impressive results for AIMET’s PTQ methods.
Table 1 below shows the accuracy of common neural network models for object classification and semantic segmentation, both as standalone FP32 models and after quantization to 8-bit integers, using AIMET’s CLE and Bias Correction methods:
| Model | Baseline (FP32 Model) | AIMET 8-bit Quantized (with CLE and Bias Correction) |
|---|---|---|
| MobileNetv2 (Top-1 Accuracy) | 71.72% | 71.08% |
| ResNet (Top-1 Accuracy) | 76.05% | 75.45% |
| DeepLab v3 (Mean IoU) | 72.65% | 71.91% |
Table 1- Accuracies of FP32 models versus those optimized with AIMET’s CLE and Bias Correction methods
In all three cases, the loss in accuracy (versus the FP32 model) is less than 1%, while model size decreased by four times, from 32-bit to 8-bit. Power and performance improvements depend on the model and the hardware, but in general, going from FP32 to INT8 can provide up to a 16 times improvement in power efficiency.
Table 2 shows the model accuracy of FP32 values compared to quantization using nearest-rounding, or AdaRound rounding, on an object detection model for Advanced Driver-Assistance System (ADAS):
| Configuration | Mean Average Precision |
|---|---|
| FP32 | 82.20% |
| Nearest Rounding (W8A8) | 49.85% |
| AdaRound (W8A8) | 81.21% |
Table 2 – Comparison of a model’s accuracy as FP32 versus quantization using standard rounding to the nearest grid point, and quantization with rounding guided by AdaRound for an object detection model
Here we can see a significant difference in accuracy between standard nearest-rounding and AdaRound, the latter being within 1% of the original FP32 model. Again, quantizing from 32-bit to 8-bit reduced the model size by four times.
For additional information, be sure to check out the whitepaper here, as well as the following resources:
- A White Paper on Neural Network Quantization: Discusses quantization, PTQ, and QAT.
- Quantizing Deep Convolutional Networks for Efficient Inference: A Whitepaper: Covers the fundamentals of quantization and includes metrics of model performance on our DSPs.
- Up or Down? Adaptive Rounding for Post-Training Quantization: Provides an in-depth discussion of AdaRound.
- AI Model Efficiency Toolkit page on QDN: Landing page where you can find links to all of the resources needed to understand and use AIMET.
- AIMET GitHub open-source project: GitHub repo for the AIMET library that provides advanced quantization and compression techniques for trained neural network models.
Related Blogs:
- The Making of a Lucki Robot
- Autonomous Mobile Robots: What do I need to know to design one?
- Building computer vision, artificial intelligence, and heterogeneous computing into your robots
- Key Insights from Microsoft Build 2022
- Cloud Connectivity Planning Considerations for IoT Edge Devices
Chirag Patel
Principal Engineer/Manager, Corporate R&D AI Research team, Qualcomm Technologies