
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
In Exploring AIMET’s Post-Training Quantization Methods, we discussed Cross-layer Equalization (CLE), Bias Correction, and AdaRound in AIMET. Using these methods, the weights and activations of neural network models can be reduced to lower bit-width representations, thus reducing the model’s size. This allows developers to optimize their models for the connected intelligent edge so that they’re fast, small, and power efficient.
The information presented was based on a recent whitepaper from our Qualcomm AI Research team: Neural Network Quantization with AI Model Efficiency Toolkit (AIMET), which provides in-depth details around AIMET’s optimizations.
The whitepaper also mentions that PTQ alone may not be sufficient to overcome errors introduced with low-bit width quantization in some models. Developers can employ AIMET’s Quantization-Aware Training (QAT) functionality, when the use of lower-precision integers (e.g., 8-bit) causes a large drop in performance compared to 32-bit floating point (FP32) values.
Let’s take a closer look at AIMET’s QAT functionality.
Quantization Simulation and QAT
To understand QAT, it’s first important to understand one of AIMET’s foundational features: quantization simulation. As discussed in Chapter 3 of the whitepaper, quantization simulation is a way to test a model’s runtime-target inference performance by trying out different quantization options off target (e.g., on the development machine where the model is trained).
AIMET performs quantization simulation by inserting quantizer nodes (aka simulation (sim) ops) into the neural network, resulting in the creation of a quantization simulation model. These quantization sim ops model quantization noise during model re-training/fine-tuning, often resulting in better solutions than PTQ, as model parameters adapt to combat quantization noise.
AIMET also supports QAT with range learning, which means that together with adapting model parameters, the quantization thresholds are also learned as part of fine-tuning.
Figure 1 below, shows the workflow for AIMET’s QAT functionality:
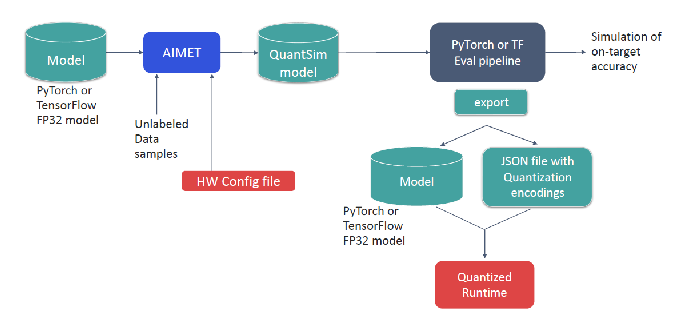
Figure 1 – Workflow that incorporates AIMET’s QAT functionality.
Given a pre-trained FP32 model, the workflow involves the following:
- PTQ methods (e.g., Cross-Layer Equalization) can optionally be applied to the FP32 model. Applying PTQ technique can provide a better initialization point for fine-tuning with QAT.
- AIMET creates a quantization simulation model by inserting quantization sim ops into a model’s graph. The user can also provide additional configuration (e.g., quantization scheme, layer fusion rules) to embed runtime knowledge into the optimization process.
- The model is then fine-tuned with the user’s original training pipeline and training dataset.
- At the end, an optimized model is returned along with a JSON file of recommended quantization encodings. Together with the model, these can be passed to the Qualcomm Neural Processing SDK to generate a final DLC model optimized for Snapdragon mobile platforms.
While model fine-tuning may seem daunting, QAT can achieve good accuracy within 10 to 20 epochs (versus full-mode training that can take several hundred epochs). To achieve better/faster convergence with QAT, good initialization should be done as recommended above. Hyper-parameters can be chosen following guidelines in the white paper.
AIMET API
AIMET provides a high-level QAT API for creating a quantization simulation model with quantization sim ops, as documented here and shown in the following code sample from the whitepaper:
import torch
from aimet_torch.examples import mnist_torch_model
# Quantization related import
from aimet_torch.quantsim import QuantizationSimModel
model = mnist_torch_model.Net().to(torch.device(’cuda’))
# create Quantization Simulation model
sim = QuantizationSimModel(model,
dummy_input=torch.rand(1, 1, 28, 28),
default_output_bw=8,
default_param_bw=8)
# Quantize the untrained MNIST model
sim.compute_encodings(
forward_pass_callback=send_samples,
forward_pass_callback_args=5)
# Fine-tune the model’s parameter using training
trainer_function(model=sim.model, epochs=1,
num_batches=100, use_cuda=True)
# Export the model and corresponding quantization encodings
sim.export(path=’./’, filename_prefix=’quantized_mnist’,
dummy_input=torch.rand(1, 1, 28, 28))
This example creates a PyTorch model and then uses it to instantiate a corresponding simulation model of AIMET’s QuantizationSimModel class. The class’s compute_encodings() method then quantizes the simulation model. The simulation model is then trained via trainer_function() – a user-defined function from the user’s training pipeline – which fine tunes model parameters using QAT. Finally, the export() method exports the quantized sim model and quantization parameter encodings
QAT Results
The whitepaper shows some impressive results for AIMET’s QAT functionality. Table 1 compares the FP32 versions of two baseline models (MobileNetV2 and ResNet50) against those quantized using both PTQ methods and QAT functionality in AIMET:
| Model | Baseline (FP32) | AIMET PTQ | AIMET QAT |
|---|---|---|---|
| MobileNetV2 | 71.72% | 71.08% | 71.23% |
| ResNet50 | 76.05% | 75.45% | 76.44% |
Table 1 – AIMET quantization-aware training (Top-1 accuracy).
For additional information, be sure to check out the whitepaper here, as well as the following resources:
- Quantizing Deep Convolutional Networks for Efficient Inference: A Whitepaper: Covers the fundamentals of quantization and includes metrics of model performance on Qualcomm DSPs.
- A White Paper on Neural Network Quantization: Provides in-depth background information on PTQ and QAT.
- AI Model Efficiency Toolkit page on QDN: Landing page where you can find links to all of the resources needed to understand and use AIMET.
- AI on the Device Edge: Developer’s Guide: An eBook on what it means to process AI at the device edge and tools to get you started.
- AIMET GitHub page: AIMET is an open-source project for creating advanced quantization and compression techniques for neural network models.
Related Blogs:
- Dreams of Sci-Fi: How the Ideas of Yesterday Become the Reality of Today
- A Virtual Showcase of the Open-source Development Model
- AWS Smart Manufacturing at the Connected Intelligent Edge
- Accelerate your machine learning networks using TVM and the Adreno OpenCL ML APIs on Adreno GPUs
- The Making of a Lucki Robot
Chirag Patel
Principal Engineer/Manager, Corporate R&D AI Research Team, Qualcomm Technologies