This blog post was originally published at Hasty’s website. It is reprinted here with the permission of Hasty.
The previous post featuring our results on the PASCAL VOC 2012 cleansing project was successful. We attracted your attention and got you talking about the Data-centric AI development approach on Reddit and the Slack communities. There was some criticism, which was great, but also, there seemed to be a lot of interest in the idea of a cleaner, better PASCAL. Nevertheless, the obtained results were just the tip of the iceberg, as the project still had an expansive room for experimentation and improvements. So, in this blog post, we will unveil what was going on for the past two months and share our plans for the future.
What’s new?
If you want a quick recap of our initial results, you can always skim through the original blog post. Still, we suggest you give your eyes a bit of the rest and take a look at our YouTube video, where we explain the project’s workflow and provide some interesting insights about it.
Over the past weeks, we explored the field a bit more while trying not to rush for a result but to be more systematic and accurate. Overall, we ran two massive experiments:
- We trained custom models on the initial and updated PASCAL without any LR scheduler;
- We trained custom models on the initial and updated PASCAL with the StepLR scheduler.
No scheduler
After posting our initial results on Reddit, we got many valuable comments from the community. It helped us identify that the initial improvements might have happened because of the ReduceLROnPlateau scheduler that, for some reason, worked only for the model trained on cleansed PASCAL. So, we decided to see what happens if we do not use any scheduler.
The experiment’s settings (hyperparameters, dataset partitioning, etc.) were the same as in the first iteration of the PASCAL cleansing project. To remind you as hyperparameters, we used the following options:
- Faster R-CNN architecture with ResNet101 FPN as a backbone;
- R101-FPN COCO weights were used for model initialization;
- Blur, Horizontal Flip, Random Crop, Rotate, and Color Jitter as augmentations;
- AdamW was the solver;
- There was no scheduler;
- Just like in every other OD task, a combination of losses was used (RPN Bounding Box loss, RPN Classification loss, final Bounding Box regression loss, and final Classification loss);
- As a metric, we had COCO mAP.
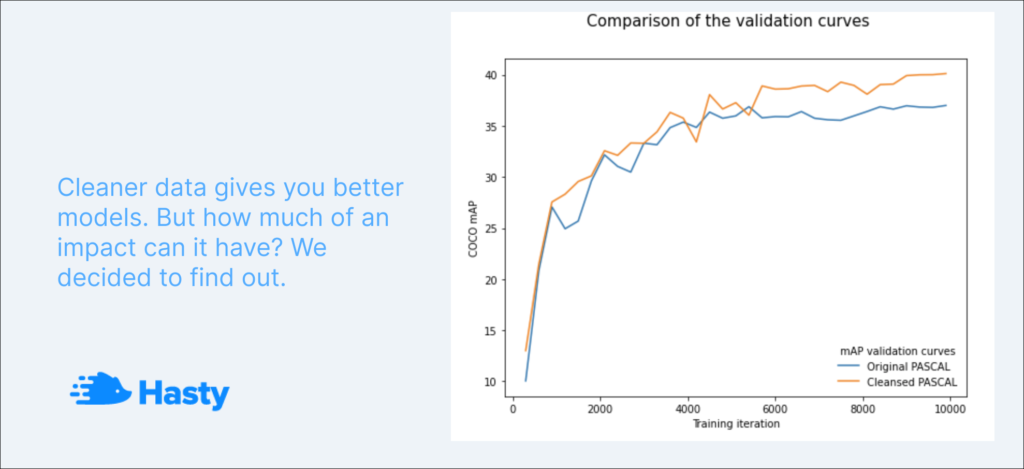
Additionally, we decided to run this experiment 4 times in a row as we wanted to achieve a more robust result. Across all these experiments the parameters were the same. Our goal was to ensure that the random processes inside neural networks do not massively affect the final result. As an example, please check out the mean Average Precision curves for one of the experiments:

Example: mAP curve (PASCAL dirty)

Example: mAP curve (PASCAL clean)
To evaluate this part of the experiment, we separately averaged mAP curves obtained on dirty and clean PASCAL and built the following graph.

Head-to-head comparison
The average COCO mAP result we achieved on dirty PASCAL was 0.372 mAP on validation, whereas for the model trained on the cleansed PASCAL, this value is 0.4 mAP. This experiment shows that even without a scheduler, the clean model outperformed the dirty one by 8%. So, ReduceLROnPlateau gave the clean model a more significant performance boost in the previous iteration. Still, as you can see, the scheduler was not the only cause of the metric improvement – the improved annotations make the difference.
If you are curious and want to see how the final COCO mAP changed for the models trained on dirty and cleansed PASCAL from experiment to experiment, please check out the table down below:

StepLR scheduler
The second idea was to use a scheduler that will 100% reduce the learning rate simultaneously for both models. We decided to use the StepLR scheduler and reduce the learning rate every 3000 iterations by 0.1. All the other parameters remained the same.
Just as in the No scheduler case, we ran the StepLR experiment 4 times in a row as we wanted to achieve a more robust result. As an example, please check out the mean Average Precision curves for one of the runs:

Example: mAP curve (PASCAL dirty)

Example: mAP curve (PASCAL clean)
Once again, to evaluate this part of the experiment, we separately averaged mAP curves obtained on dirty and clean PASCAL and built the following graph.

Head-to-head comparison
The average COCO mAP result we achieved on dirty PASCAL was 0.387 mAP on validation, whereas for the model trained on the cleansed PASCAL, this value is 0.409 mAP. The clean model outperformed the dirty one by 5.6%. So, having a scheduler gave us an additional logical and expected overall metric boost.
If you are curious and want to see how the final COCO mAP changed for the models trained on dirty and cleansed PASCAL from experiment to experiment, please check out the table down below:

To summarize, although our second iteration might not be as extensive and fascinating as the initial one, we still got the results that prove the original experiment was legit. With this in mind, we again encourage you to give Data-centric AI development a shot, as it might be the exact thing you need to push your solution to the top.
What is the next step?
Getting excellent results and proving that the Data-centric AI development approach works are great achievements, but, unfortunately, they are not enough to make a difference in the grand scheme. Even with an understanding that better data results in better models, if you have a partially labeled dataset like PASCAL, you still have to work hard and invest lots of time and money to improve the data quality.
However, the bigger picture is that cleaning up even a section of a dataset has its benefits. First, it can push your AI solution to new heights and we have demonstrated that it two iterations of our project. Second, by improving the data (especially if you are tuning a well-known free dataset) and sharing it with the Data Science community, you are helping future researchers to achieve better results. From this point of view, the Data-centric AI development approach is not only relevant for commercial organizations. We strongly believe that better data for research teams also means more accurate results and advancement for the entire AI field.
These assumptions defined our next step with the PASCAL cleansing project. We have always tried to make our customers’ life easier and spare their time, money, and nerves. Today is the time to set a new goal and contribute a bit to the future. The PASCAL project was an unforgettable experience as we had never thought such little work could push a solution so much further. And we want to share this experience with you and the AI community.
Today, we are launching our PASCAL crowdsourcing campaign, where you will work side by side with us to thoroughly cleanse PASCAL from all its issues using the full power of the Hasty AI assistants and AI Consensus Scoring.
Why should I help?
If you join us, you will have a chance to work on a fascinating project that might be helpful for future AI research. When the job is done, we will post the updated version of the dataset on Kaggle so that anyone around the globe can use it without experiencing any issues with annotations. Additionally, we will donate to charity depending on the results achieved, making your contribution precious and karma cleaner.
Do you want to get in the gauntlet, push PASCAL to its limits, and help future AI researchers? Please fill in the sign-up form, and we will get back to you in no time.
Vladimir Lyashenko
Content Manager, Hasty