
All neural networks have similar components, including neurons, synapses, weights, biases, and functions. But each network has unique requirements based on the number of operations, weights, and activations that must be processed. This is apparent when comparing popular networks, as shown in the chart below. Still, in the initial wave of edge AI deployments, many OEMs opted for general-purpose Neural Processing Units (NPUs). The general-purpose nature of those NPUs means they can support various networks and the gamut of their underlying requirements. However, a one-size-fits-all solution is rarely the most efficient one. That’s because a general-purpose NPU is often much larger than it needs to be for a specific application and will consume much more power than necessary.
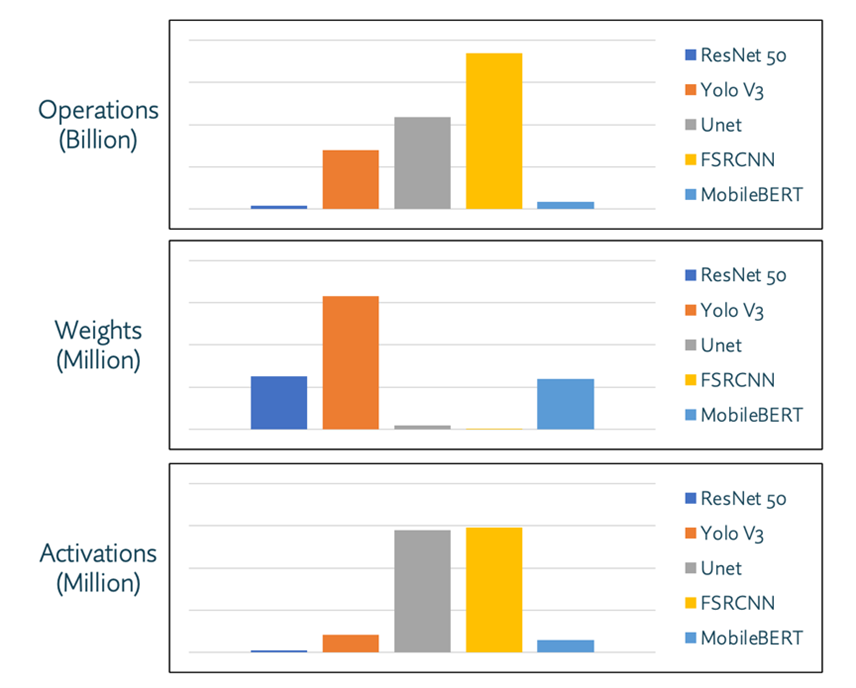
Figure 1: Plotting the number of operations, weights, and activations of 5 common NNs (ResNet 50,
Yolo V3, Unet, FSRCNN, MobileBERT) makes it easy to see the variability in workload processing requirements.
The inefficiencies of one-size-fits-all AI processing significantly impact manufacturers of home appliances and other smaller applications like doorbell cameras—all of which are highly cost-sensitive. OEMs can use AI to enable a whole host of new use cases. However, deploying advanced AI processing can prove difficult when general-purpose NPUs require significant silicon area and costly external memory. While home appliances and doorbells typically don’t need much processing—perhaps only about 1 TOPS (Trillions of Operations Per Second). But even at 1 TOPS, inefficient processing can double or triple the size of a general-purpose NPU compared to a purpose-built version. That increased size translates directly to increased BOM cost, which is untenable in a situation where each cent is analyzed repeatedly.
OEMs tell us that for their products to evolve to offer a true AI-enhanced user experience, the inherent overhead of general-purpose NPUs won’t cut it. They need the absolute smallest NPU that best matches their requirements and keeps costs to an absolute minimum. They’re looking for NPUs tailored to their specific use cases, with an absolute minimum of overhead and requiring little, or ideally no, external memory. Simply put, size (and by extension cost) are the primary drivers of NPU deployments for cost-sensitive home appliances and other innovative home applications.
That is where Expedera’s new OriginTM E1 product family comes in. We’ve adapted our silicon-proven Origin architecture to provide the smallest, most power-efficient 1 TOPS engines optimized for specific neural networks such as ResNet50, YOLO, Unet, FSRCNN, Inception, BERT, MobileNet, EfficientNet, and others. Optimizing the engine for a small set of networks reduces the size and power overhead of a general-purpose NPU by as much as 3X. Origin E1 engines provide the smallest possible NPU for the application, consume the least power, and maintain more than 80% average utilization with little or no external memory required. As with all our Origin products, Expedera delivers the E1 as soft IP, suitable for any process technology. Origin is field-proven in more than 8 million consumer devices.
Need the smallest engine possible? Contact us with your specific requirements, and we will work with you to tailor our IP to your unique needs.