
This article was originally published at Au-Zone Technologies’ website. It is reprinted here with the permission of Au-Zone Technologies.
Working in a hazardous environment always requires protection to prevent injuries. In most fatal accidents the workers are not wearing the right protection or using it properly. Due to the dynamic nature of some work, danger is always present, thus it is needed to monitor how protected the workers are during working hours. In this article we explain how it is possible to use DeepView ModelPack [1] and VisionPack [2] to build a higher end application capable of monitoring, and notifying in real-time, how safe workers are when executing hazardous tasks at work. For this experiment, a hard hat dataset was used to train ModelPack using eIQ Portal 2.5. After 25 epochs, the full integer quantized model achieved over 60% MAP (Mean Average Precision) and takes only 16ms (60 fps) to run the entire pipeline (load image, inference, decoding, and NMS (non-max-suppression)) when integrated with VisionPack on the i.MX 8MP Plus EVK or Au-Zone’s Maivin AI Vision Starter Kit.
Introduction
Despite advances in safety equipment, technology and training, for hazardous working environments, some industries like construction continues to face high rates of fatal and non-fatal injuries and accidents among its workers. According to [3], more than 950 people die every day and over 720,000 workers get hurt because of occupational accidents. For instance, in India, over 48,000 workers die annually because of occupational accidents and more than 37 million are out of work for at least 4 days for injuries [4]. All these accidents have a big impact in the gross national product worldwide. Annually, more than 3,023,718 million USD are paid to workers as compensation due to accidents. Beyond the economic impact, there are additional implications that impact the physical and psychological performance of millions of families every year.
An accident is a term that was initially introduced in 20th Centuries to relate undesired situations occurred around automobilist industry because of media manipulation. More recently, the concept was modified to be an unintended, normally unwanted event, that was not directly caused by humans [5] and implies that nobody should be blamed, but the event may have been caused by unrecognized or unaddressed risks (https://en.wikipedia.org/wiki/Accident). With the aim of solving this issue, protection equipment has been developed to keep workers as safe as possible while performing dangerous tasks. Hard hats, reflecting vests, specialized boots and gloves, safety glasses, are listed as the few more commonly used items. In most industries, it is required to use the right protection equipment, but often lacks the necessary supervision to ensure compliance.
In this article we present a framework for using Computer Vision at the edge for monitoring hazardous workplaces. Our framework can run in real-time (from 30 fps to 60 fps) on an embedded target device (EVK, Maivin) without sacrificing accuracy. This framework is based on two ready to use components from Au-Zone technologies, DeepView ModelPack and VisionPack.
We will describe all the steps needed to create a highly efficient pipeline to solve a real-world problem using edge computing and proprietary software. Our solution will be a real-time monitoring system aided by object detection and vision pipelines capable of notifying every time a worker is not wearing the complete set of safety equipment required in the workplace. The following diagram shows the main building blocks utilized by our system.

Architecture diagram using the Maivin platform.
This application takes the outputs from two ModelPack instances running on the same target, and combines them. One instance of ModelPack is trained on a pedestrian detection dataset and will be used to detect people. The other ModelPack instance is trained on the Hard Hats dataset and the model will be executed only on frames that have detected a person. Finally, our routines will compute some heuristics to infer if each person is wearing the full protection equipment or not. Taking this into consideration, we will be using the following visualization scheme (reference the cover graphic):
- Safe (green): The person is wearing the entire protection equipment
- Warning (orange): The person is only wearing 1 piece of equipment (Vest or Hard Hat)
- Danger (red): The person is not wearing any protection equipment
The rest of the paper is distributed as follows. Section 2 (Related Work) lists the current research in Object Detection and how this problem has been solved so far in Computer Vision. Section 3 explains in more detail how every piece of software is connected while section 4 explains potential transformations we had to apply to the dataset, training configuration, quantization, results, and main contributions. In section 5 conclusions are given and finally, section 6 covers future research and use cases that can be showcased when combining DeepView ModelPack with VisionPack.
Related Work
Object detection algorithms are highly involved in most of Vision-Based problems from real world. People detection has been one of the hottest topics in object detection field due to its high impact in different industries such as surveillance, monitoring, recreation, robotics, and autonomous driving [7,8]. This field has also been extended to the 3D case [9] with high impact in autonomous driving. To know where people are is an attractive solution that helps make decisions in different environments.
With the power of embedded computing, multiple areas of application have emerged. Monitoring safe working areas is an interesting use case capable of measuring the grade of protection each worker has while performing a task. According to [14], safety performance is generally measured by reactive (after the event) and proactive indicators. For the sake of simplicity and application scope, our work is focused on proactive monitoring. In [10] it was proposed a solution based on internal traffic planning and object detection to evaluate the risk when executing the task from aerial images. A closer to reality idea was presented in [11] where authors used Yolo V4, trained on Darknet framework to detect personal protective equipment (PPE). R-CNN is also used to detect non hardhat usage in videos [12]. Another attempt of detecting the usage of hard hats while working at construction is made in [13], this time using Yolo v3.
The main disadvantage of the solutions above is they lack practical application and granularity. A vast majority of solutions reported in this field are based on using a heavy model that produces a very good accuracy sacrificing the scalability and viability of the product. It is practically impossible to have these algorithms working in real time at the edge since they are considerable large. For that reason, we proposed to combine specialized in edge computing technologies to solve the problem.
Safety Assessment with DeepView ModelPack and VisionPack
With the aim of solving the problem of monitoring if workers are wearing protection equipment, we built an application by combining ModelPack and VisionPack. Our application takes ModelPack trained over two different datasets, which result in a ModelPack-People-Detection and ModelPack-Safety-Gear. These two models are loaded into VisionPack and executed on each input frame. Finally, the results are combined into a simple strategy that matches a person with their safety gear and produces a bounding box for the entire person colored according to the scheme explained above (green, orange, red). In this section we explain in detail what ModelPack and VisionPack are. Also, we dedicate a section to show the way the pieces are connected.
DeepView ModelPack
ModelPack for Detection provides a state-of-the-art detection algorithm [6] featuring real-time performance on i.MX 8M Plus platforms. It is especially well optimized for utilizing the NPU and GPU found on this platform and has been fine tuned to support full per-tensor quantization while preserving high accuracy in comparison with the float model. DeepView ModelPack is fully compatible with DeepView Creator and eIQ Toolkit which provide an easy-to-use graphical interface for creating datasets, training, model validation, and deploying optimized models to i.MX 8M Plus platforms.
A key feature on ModelPack is we can find higher optimized weights that lead training sessions to be successful since the beginning, showing higher accuracy and speed on convergence. Since ModelPack is based on Yolo V4 algorithm, the anchors generation occur in an automatic way, which are refined using genetic algorithm in a second stage. Programming languages, complicated loss functions, data augmentation and training frameworks are transparent to the user since the integration with the GUI is straightforward and easy to use.
 |
 |
 |
Architecture diagram using the Maivin AI Vision Starter Kit.
The above figure shows different working scenarios related with construction. There, it is observed how some of the workers are using all the protection equipment while the rest are using none of them. These images were created by running one of the resulting ModelPack checkpoints on VisionPack, this last one oversees controlling the execution pipeline at the edge.
DeepView VisionPack
DeepView VisionPack provides vision pipeline solutions for edge computing and embedded machine learning applications. Whether targeting NXP i.MX Application Processors and i.MX RT Crossover MCUs, Au-Zone tunes these pipelines for maximum efficiency. VisionPack provides end-to-end optimizations, including sensor support, pre-processing, and full integration with Au-Zone’s DeepViewRT runtime engine. At the edge, VisionPack can detect your model and establish the right communication with the decoder so the boxes can be extracted from the raw inference in an automatic way. Highly optimized non-max-suppression algorithms are included as well as a ready to use Python API that allows you to connect with DeepViewRT runtime engine and get inference in three lines of code.
For solving this problem, we decided to use VisionPack since it acts like a higher end application library that will connect your model with the production environment in few lines of code. Using VisionPack enabled us to focus on solving the vision problem, and not how to implement the vision pipeline, allowing a full prototype to be developed in only 2 days.

DeepView VisionPack Overview
Pipeline Integration
The safety framework starts by connecting VisionPack to the input source. VisionPack will load two models: ModelPack-People-Detection and ModelPack-Safety-Gear. The first one will be executed every frame while the second one is conditioned by the outcome of the first one. If no person was detected, the second model won’t be executed. For the case the first model detects the second model will be executed and all the objects in the frame will be retrieved with their respective bounding boxes (hardhat, no_hardhat, no_vest, and vest). Finally, the following heuristic is applied to check the safety status of each worker.

Where S is the heuristic function, x is the outcome of ModelPack-People-Detection and y is the outcome of ModelPack-Safety-Gear. The final application will draw the boxes around people taking the following color scheme:
- Red: Danger
- Orange: Warning
- Green: Safe

Visualization of the monitoring.
People wearing vest and hard hats will be drawn in green. People wearing only one of the protection equipment (hard hat or vest) will be drawn on orange, otherwise, people are unsafe and will be drawn in red because they are not wearing any protection equipment.
Notifications will be sent according to the requirements of each working area.

In the above figure is described the entire workflow of our application. The application logic is implemented in node S (heuristic).
Experiments and Contributions
For developing this system, the first difficult task was dataset cleaning. The dataset is from public domain and was taken from this resource (https://drive.google.com/drive/u/2/folders/14zw_X1ImyOo71jEGyxT7ARxVV8t1rYDU) avoiding the planer_images as the author says in his Youtube channel. The dataset is in yolo format and contains 4 classes (hard hat, boots, mask, vest). In our case we suppressed the boots and mask classes since they lack importance for this demo. Next the dataset was reviewed and we corrected bad annotations and re-annotated all images with two more classes (no-vest and not-hard-hat). All dataset manipulation was completed using eIQ Portal (class removal, dataset review and correction, and new classes annotations).
Dataset
The resulting dataset has a large unbalance factor since the two new classes (no_hardhat and no_vest) were included to reduce the false positives. Initially, the dataset with two classes was accurately detecting vests, but predictions were full of false positives as well. By adding these two classes we mitigate these false detections. To add these two classes was easy to do using the eIQ GUI.
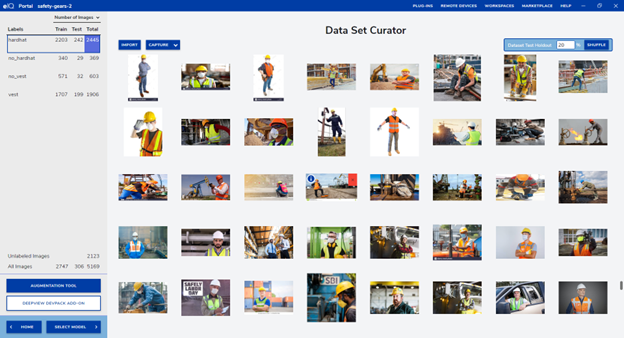
Dataset Curator
Finally, the dataset and class distribution are shown the following chart.

Train and Test annotations distribution across all the classes in the dataset.
DeepView ModelPack Customization
To make ModelPack accurate on both problems, people detection and safety gear detection, we used a ModelPack from DeepView Zoo, trained on COCO-2017 dataset for solving the first problem (people detection). For the case of the second problem (safety gear detection) we had to train ModelPack on the safety-gear dataset.
To do that, we used the following hyperparameters:
- Input Resolution: 416 x416
- Learning-Rate: Linear decay, starting at 1e-3 with a decay factor of 0.9 executed after 5 epochs.
- Batch size: 10
- Number of Epochs: 25
- Augmentation: Default-Oriented Augmentation

ModelPack training graph after 25 epochs
Once the training process ended, we validated the model and get 52.42% mAP@50. This validation was performed over the per-tensor quantized model, using uint8 input and int8 output. As a benchmark, we also tested the free SSD model contained in eIQ Portal, which was only 37% map@50.
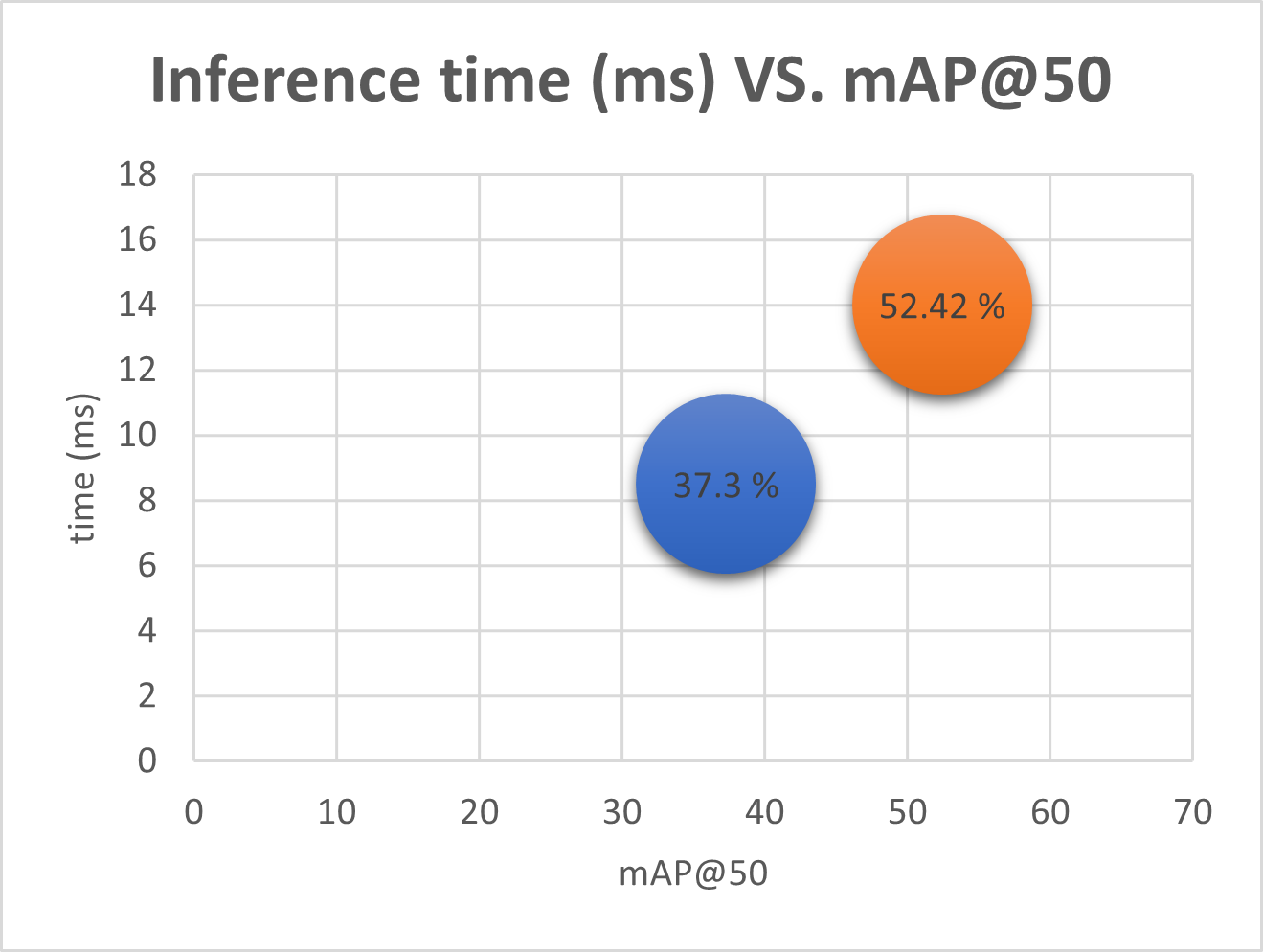
Inference time vs mAP@50. SSD vs ModelPack.
For benchmarking purposes, we trained both models for 25 epochs only. Notice ModelPack has a 15% higher mAP than SSD.
From the above chart, we can infer than SSD is faster but less accurate than ModelPack. In our case, we decided to move forward with ModelPack since it is 14ms on NPU which can be translated into 60 FPS. Notice that our camera is limited to run at 30 FPS and 60 FPS speed won’t be observed in the result. This time, we decided to take the more accurate model and run two instances of the same model (people detection and safety gear detection) on the same device while keeping a detection rate of 30 FPS.
Conclusions
This article presents a use case based on real-time monitoring if workers are wearing protective equipment in the workplace. The system responds operates at a full 30 FPS, and alerts every time a worker is not wearing the appropriate protection equipment. Utilizing Au-Zone’s middleware, ModelPack and VisionPack, a solution was developed in < 3 days. Both software packages are highly specialized in optimizing edge computing tasks, which makes it possible to build a new vision based solution in record time. During experimentation, we noticed that the free model from eIQ Portal (SSD) is not as accurate for this dataset and to be faster is not a requirement in this case since we are limited by the camera speed (30 FPS). Finally, we tested our software in both environments, indoor and outdoor and the obtained results can be shown in the following videos.
Bibliography
- ModelPack: Au-Zone Technologies solution for Object Detection at the Edge. https://www.embeddedml.com/deepview-model-pack (May, 2022).
- VisionPack: Higher end vision pipeline from Au-Zone Technologies for solving Computer Vision problems at the edge. https://www.embeddedml.com/deepview-vision-pack (May, 2022).
- Patel, Dilipkumar Arvindkumar, and Kumar Neeraj Jha. “An estimate of fatal accidents in Indian construction.” Proceedings of the 32nd annual ARCOM conference. Vol. 1. 2016.
- Hämäläinen, Päivi. “Global estimates of occupational accidents and fatal work-related diseases.” (2010).
- Woodward, Gary C. The Rhetoric of Intention in Human Affairs. Lexington Books, 2013.
- Bochkovskiy, Alexey, Chien-Yao Wang, and Hong-Yuan Mark Liao. “Yolov4: Optimal speed and accuracy of object detection.” arXiv preprint arXiv:2004.10934 (2020).
- Tian, Di, et al. “A review of intelligent driving pedestrian detection based on deep learning.” Computational intelligence and neuroscience 2021 (2021).
- Linder, Timm, et al. “Cross-Modal Analysis of Human Detection for Robotics: An Industrial Case Study.” 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021.
- Wang, Yingjie, et al. “Multi-modal 3d object detection in autonomous driving: a survey.” arXiv preprint arXiv:2106.12735 (2021).
- Kim, Kyungki, Sungjin Kim, and Daniel Shchur. “A UAS-based work zone safety monitoring system by integrating internal traffic control plan (ITCP) and automated object detection in game engine environment.” Automation in Construction 128 (2021): 103736.
- Kumar, Saurav, et al. “YOLOv4 algorithm for the real-time detection of fire and personal protective equipments at construction sites.” Multimedia Tools and Applications (2021): 1-21.
- Qi Fang, Heng Li, Xiaochun Luo, Lieyun Ding, Hanbin Luo, Timothy M. Rose, Wangpeng An, Detecting non-hardhat-use by a deep learning method from far-field surveillance videos, Automation in Construction, 2018.
- Hu, Jing, et al. “Detection of workers without the helments in videos based on YOLO V3.” 2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI). IEEE, 2019.
- Hinze, Jimmie, Samuel Thurman, and Andrew Wehle. “Leading indicators of construction safety performance.” Safety science 51.1 (2013): 23-28.
Reinier Oves Garcia
Senior Machine Learning Developer, Au-Zone Technologies