
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
How we are pushing the boundaries of integer quantization and making it possible at scale.
Artificial intelligence (AI) is enhancing our daily lives, whether it’s improving collaboration, providing entertainment, or transforming industries through autonomous vehicles, digital health, smart factories, and more. However, these AI-driven benefits come at a high energy consumption cost. To put things in perspective, it is expected that by 2025 deep neural networks will have reached 100 trillion weight parameters, which is similar to the capacity of the human brain, or at least the number of synapses in the brain.
Why quantization continues to be important for edge AI
To make our vision of intelligent devices possible, AI inference needs to run efficiently on the device — whether a smartphone, car, robot, drone, or any other machine. That is why Qualcomm AI Research continues to work on holistic model efficiency research, which covers areas such as quantization, neural architecture search, compilation, and conditional compute. Quantization is particularly important because it allows for automated reduction of weights and activations to improve power efficiency and performance while maintaining accuracy. Based on how power is consumed in silicon, we see an up to 16X increase in performance per watt and a 4X decrease in memory bandwidth by going from 32-bit floating point (FP32) to 8-bit integer quantization (INT8), which equates to a lot of power savings and/or increased performance. Our webinar explores the latest findings in quantization.
AI engineers and developers can opt for post-training quantization (PTQ) and/or quantization-aware training (QAT) to optimize and then deploy their models efficiently on the device. PTQ consists of taking a pre-trained FP32 model and optimizing it directly into a fixed-point network. This is a straightforward process but may yield lower accuracy than QAT. QAT requires training/fine-tuning the network with the simulated quantization operations in place, but yields higher accuracy, especially for lower bit-widths and certain AI models.

Integer quantization is the way to do AI inference
For the same numbers of bits, integers and floating-point formats have the same number of values but different distributions. Many assume that floating point is more accurate than integer, but it really depends on the distribution of the model. For example, FP8 is better at representing distributions with outliers than INT8, but it is less practical as it consumes more power — also note that for distributions without outliers, INT8 provides a better representation. Furthermore, there are multiple FP8 formats in existence, rather than a one-size-fits-all. Finding the best FP8 format and supporting it in hardware comes at a cost. Crucially, with QAT the benefits offered by FP8 in outlier-heavy distributions are mitigated, and the accuracy of FP8 and INT8 becomes similar — refer to our NeurIPS 2022 paper for more details. In the case of INT16 and FP16, PTQ mitigates the accuracy differences, and INT16 outperforms FP16.
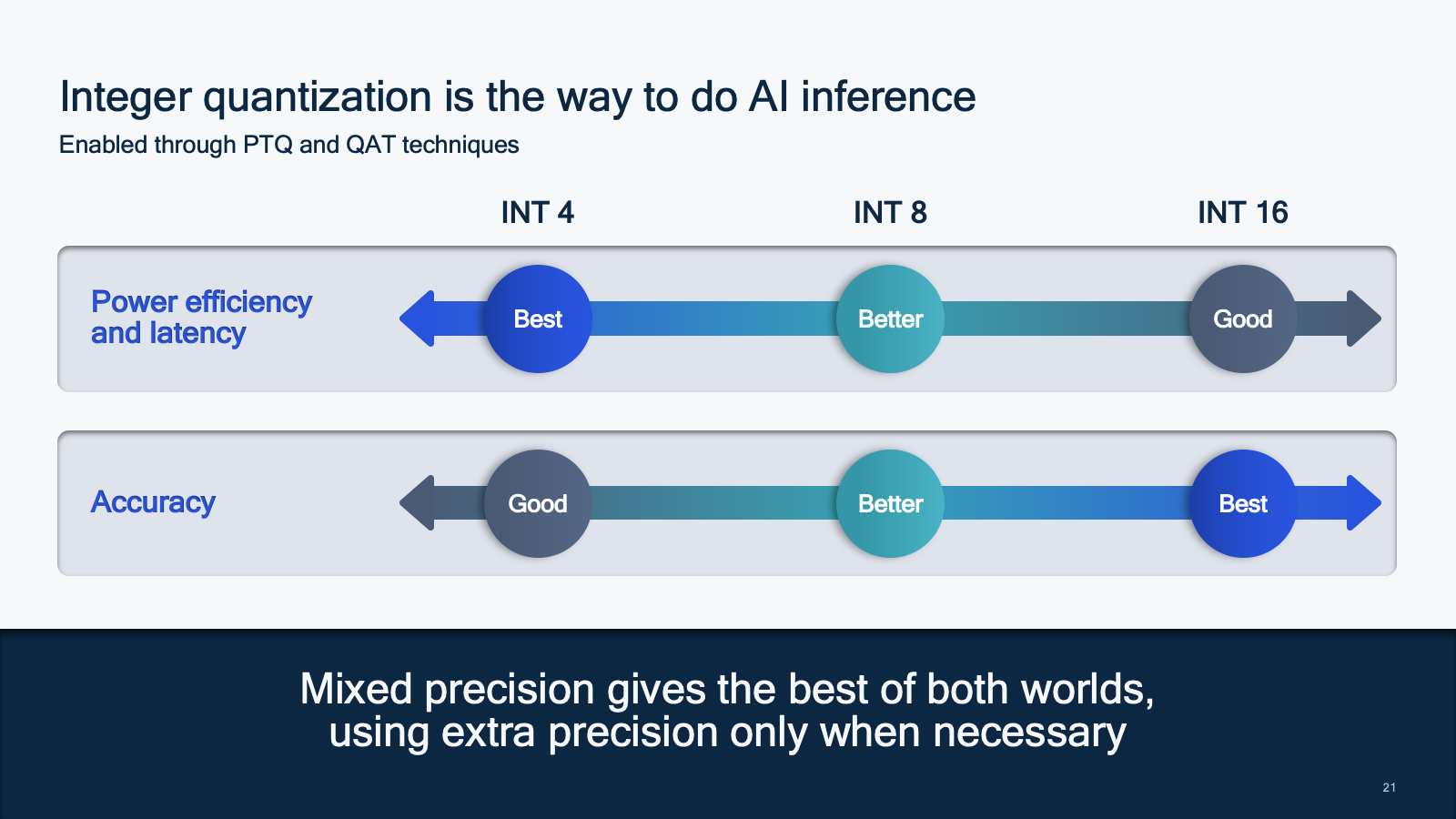
Making 4-bit integer quantization possible
The latest findings by Qualcomm AI Research go one step further and address another issue harming the model accuracy: oscillating weights when training a model. In our ICML 2022 accepted paper, “Overcoming Oscillations in Quantization-Aware Training,” we show that higher oscillation frequencies during QAT negatively impact accuracy, but it turns out that this issue can be solved with two state-of-the-art (SOTA) methods called oscillation dampening and iterative freezing. SOTA accuracy results are achieved for 4-bit and 3-bit quantization thanks to the two novel methods.
Enabling the ecosystem with open-source quantization tools
Now, AI engineers and developers can efficiently implement their machine learning models on-device with our open-source tools AI Model Efficiency Toolkit (AIMET) and AIMET Model Zoo. AIMET features and APIs are easy to use and can be seamlessly integrated into the AI model development workflow. What does that mean?
- SOTA quantization and compression tools
- Support for both TensorFlow and PyTorch
- Benchmarks and tests for many models
AIMET enables accurate integer quantization for a wide range of use cases and model types, pushing weight bit-width precision all the way down to 4-bit.
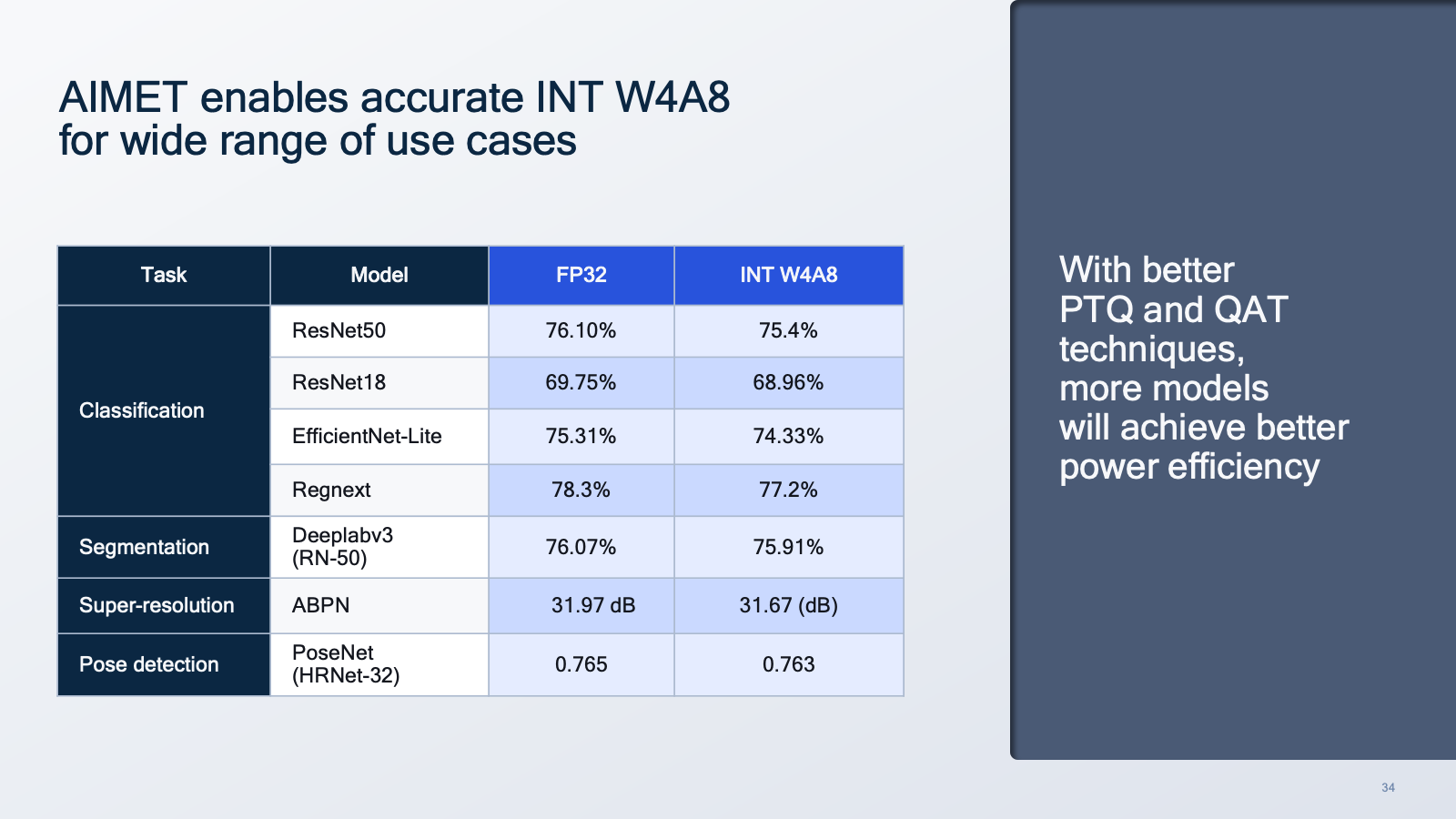
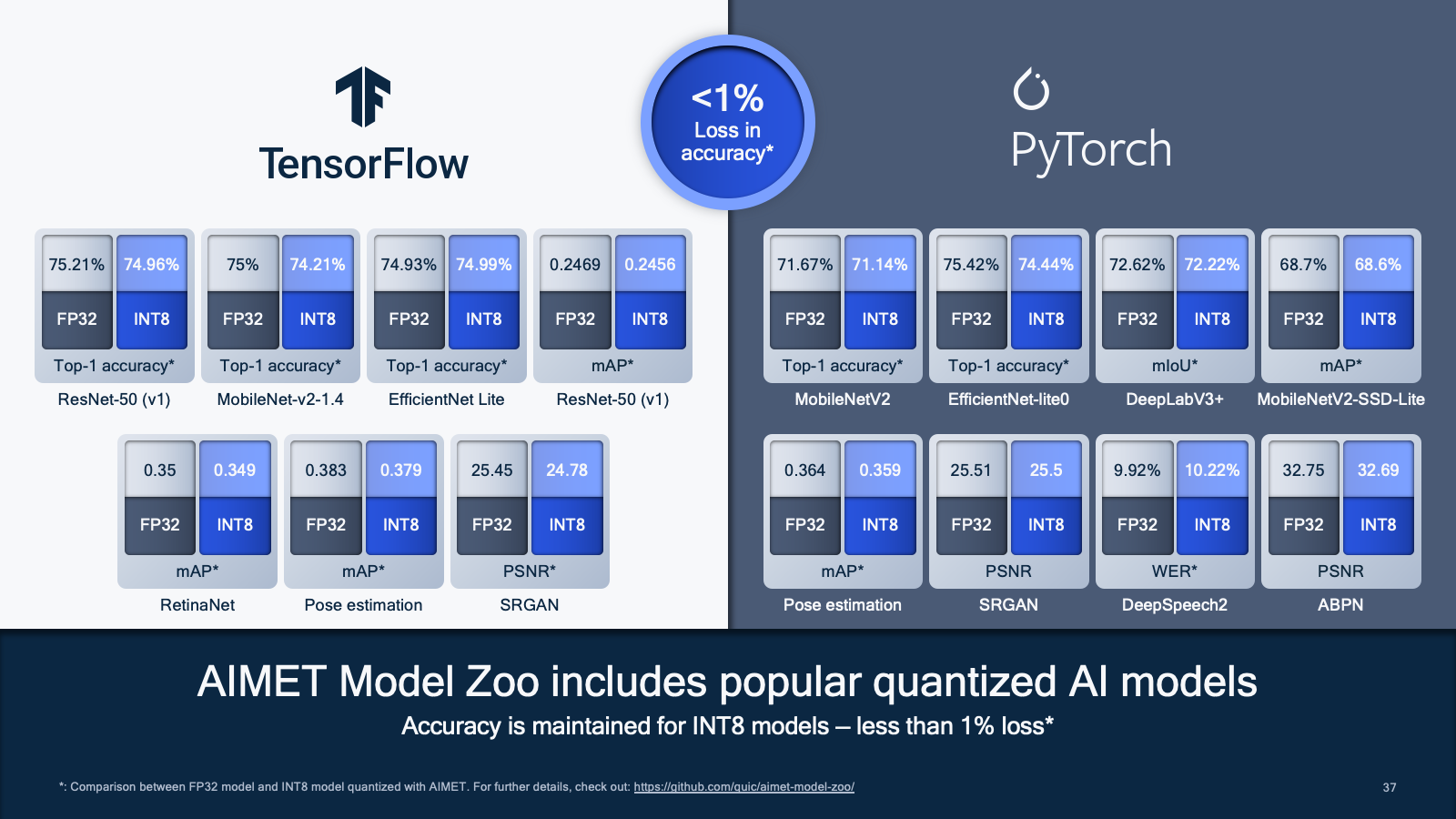
In addition to AIMET, Qualcomm Innovation Center has also made the AIMET Model Zoo available: a broad range of popular pre-trained models optimized for 8-bit inference across a broad range of categories from image classification, object detection, and semantic segmentation to pose estimation and super resolution. AIMET Model Zoo’s quantized models are created using the same optimization techniques as found in AIMET. Together with the models, AIMET Model Zoo also provides the recipe for quantizing popular 32-bit floating point (FP32) models to 8-bit integer (INT8) models with little loss in accuracy. In the future, AIMET Model Zoo will provide more models covering new use cases and architectures while also enabling models with 4-bit weights quantization via further optimizations. AIMET Model Zoo makes it as simple as possible for an AI developer to grab an accurate quantized model for enhanced performance, latency, performance per watt, and more without investing a lot of time.
Model efficiency is key for enabling on-device AI and accelerating the growth of the connected intelligent edge. For this purpose, integer quantization is the optimal solution. Qualcomm AI Research is enabling 4-bit quantization without loss in accuracy, and AIMET makes this technology available at scale.
Tijmen Blankevoort
Director, Engineering, Qualcomm Technologies Netherlands B.V.
Chirag Patel
Engineer, Principal/Mgr., Qualcomm Technologies