
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Our latest whitepaper shows that a new floating-point format doesn’t measure up to integer when you’re quantizing AI models to run on edge devices
Artificial intelligence (AI) has become pervasive in our lives, improving our phones, cars, homes, medical centers, and more. As currently structured, these models primarily run in power-hungry, network-dependent data centers. Running AI on edge devices such as smartphones and PCs would improve reliability, latency, privacy, network bandwidth usage, and overall cost.
To move AI workloads to devices, we need to make neural networks considerably more efficient. Qualcomm has been investing heavily in the tools to do so, most recently showcasing the world’s first Stable Diffusion model on an Android phone. Bringing models like GPT, with its hundreds of billions of parameters, to devices will require even more work.
The Qualcomm AI Research team has been making advances in deep learning model efficiency for the past years with state-of-the-art results in neural architecture search, compilation, conditional compute, and quantization. Quantization, which reduces the number of bits needed to represent information, is particularly important because it allows for the largest effective reduction of the weights and activations to improve power efficiency and performance while maintaining accuracy. It also helps enable use cases that run multiple AI models concurrently, which is relevant for industries such as mobile, XR, automotive, and more.
Recently, a new 8-bit floating-point format (FP8) has been suggested for efficient deep-learning network training. As some layers in neural networks can be trained in FP8 as opposed to the incumbent FP16 and FP32 networks, this format would improve efficiency for training tremendously. However, the integer formats such as INT4 and INT8 have traditionally been used for inference, producing an optimal trade-off between network accuracy and efficiency.
We investigate the differences between the FP8 and INT8 formats for efficient inference and conclude that the integer format is superior from a cost and performance perspective. We have also open sourced the code for our investigation for transparency.
Differences between floating point and integer quantization
Our whitepaper compares the efficiency of floating point and integer quantization. For training, the floating-point formats FP16 and FP32 are commonly used as they have high enough accuracy, and no hyper-parameters. They mostly work out of the box, making them easy to use.
Going down in the number of bits improves the efficiency of networks greatly, but the ease-of-use advantage disappears. For formats like INT8 and FP8, you have to set hyper-parameters for the representable range of the distributions. To get your original network accuracy back, you also have to spend some extra time quantizing these networks. Either in some simple quantization steps called post-training-quantitation (PTQ), or by training the network in a quantized way all together, called quantization-aware-training (QAT).
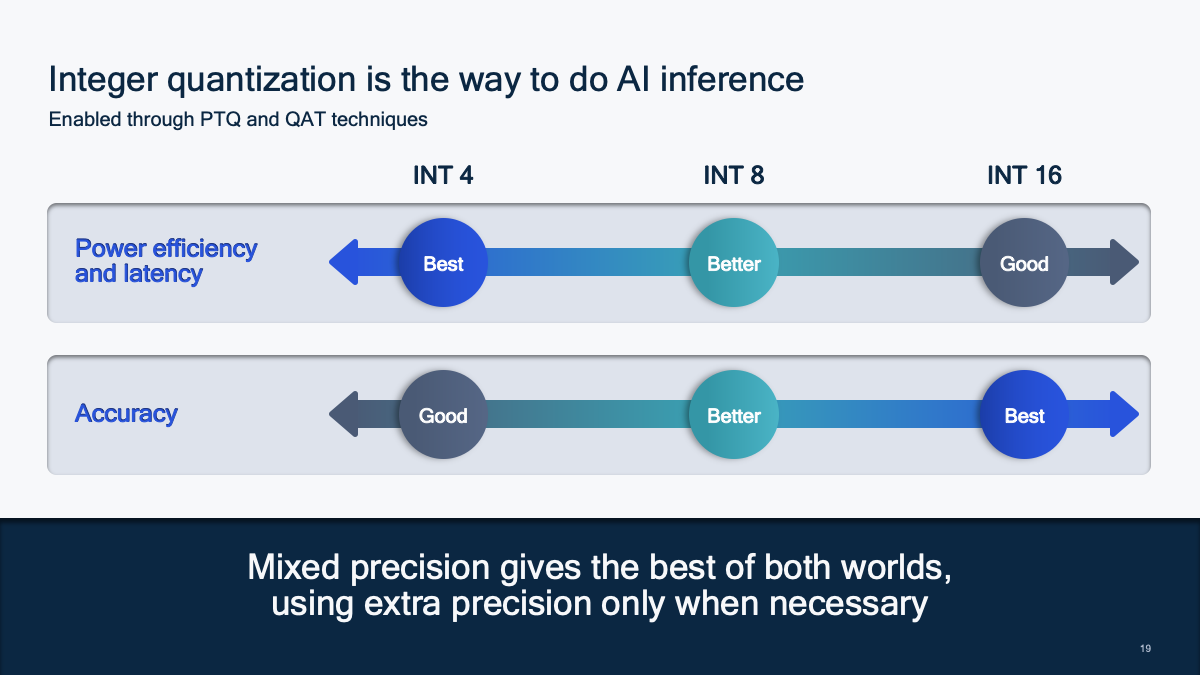
Figure 1: Comparison of different INT formats.
Given that most training in the industry is currently conducted with entire networks in FP32, or sometimes FP16 with mixed precision, the step to having some parts of a network run in FP8 is an appealing potential speed-up for the costly and time-intensive training procedures in deep learning. This topic has gained quite some traction lately, so we set out to find out what this development means for efficient inference on edge devices. Specifically, we look at both the hardware considerations for the formats and the effect of the chosen formats on neural network accuracy.
Our whitepaper shows that the hardware implementation of the FP8 format is somewhere between 50% to 180% less efficient than INT8 in terms of chip area and energy usage. This is because of the additional logic needed in the accumulation of FP formats versus integer formats. This seems like a broad range, but the actual efficiency depends on many hardware design choices that vary greatly. A similar conclusion was reached recently by Microsoft and Meta: Floating-point arithmetic is just much less efficient than integer arithmetic.
This means that FP8 will have to be significantly more accurate than INT8 to be worthwhile from a hardware-efficiency perspective.
The hardware implementation of the FP8 format is somewhere between 50% to 180% less efficient than INT8 in terms of chip area and energy usage.
Quantization-aware training (QAT) results
Quantization-aware training is the quantization scenario most like how a format like FP8 would be used in practice, you train with the format while optimizing your neural network. We show the QAT results below for different tested formats. We see that all quantized networks get close to their original floating-point performance. In most cases, we even see an improvement over the baseline results of FP32. The reason for this is simply that training these models for longer generally improves results, even if we would train longer in FP32.
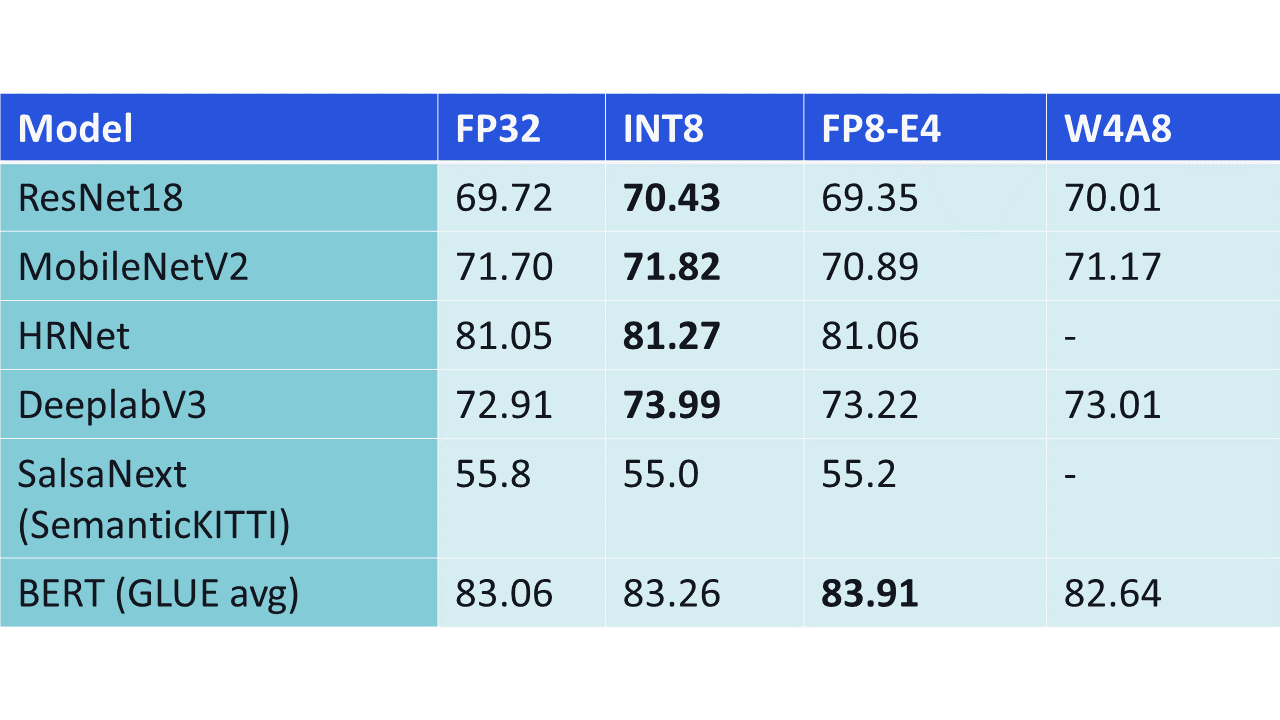
Figure 2: QAT results for different test formats. FP8-E4 is the most proposed FP8 format with 4 exponent bits. W4A8 is the INT format with 4-bit weights and 8-bit activations.
The results are quite clear: INT8 tends to perform better than other formats for most types of networks. It is only for transformers that FP8 performs better, but in the paper, we delve deeper into transformers and show that this difference is easily mitigated. The conclusion is simple however: there is no a-priori reason to believe that the FP8 format is more accurate for neural networks. In some cases, even when going as low as 4-bit weights with the W4A8 format (as indicated in the rightmost column of Figure 2), the accuracy is comparable to the FP8 format.
Can we convert FP8 to INT8 with good accuracy?
Since there are some benefits to using the FP8 data format for training, we also investigated the performance when FP8-E4 (a FP8 format with 4 exponent bits) trained networks are converted naively to INT8 for inference. We found that INT8 can precisely represent roughly 90% of the range covered by the FP8-E4 format without any quantization error. The remaining 10% of the range close to 0 incurs a small quantization error.
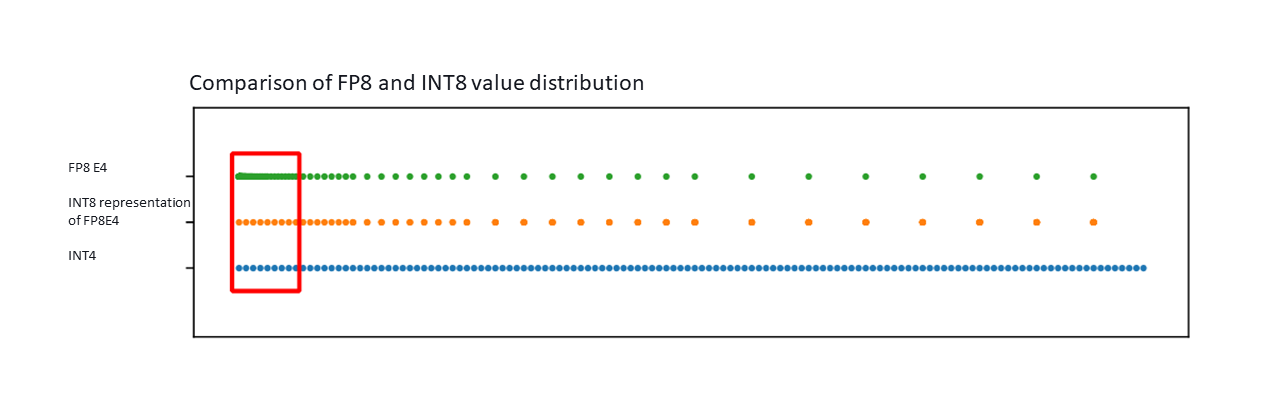
Figure 3: The FP8-E4 and INT8 distributions overlayed. The numbers inside the red box incur a small error when converted from FP8 to INT8, however, the larger values away from 0 can be perfectly captured by the INT8 format without an error.
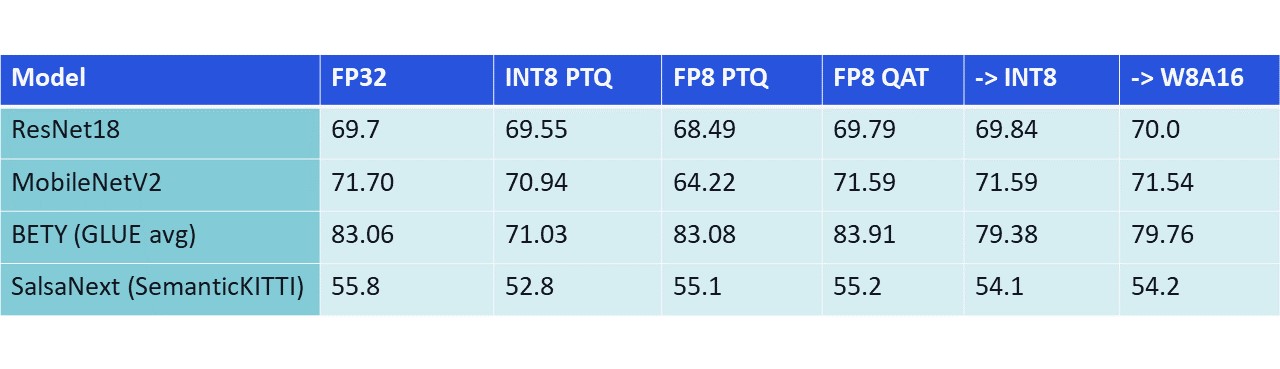
Figure 4: What happens when we take a FP32 network, quantize it with QAT to FP8-E4, and then naively convert it to INT8? The conversion is smooth most of the time.
The general conclusion is that for networks that were originally easy to quantize from FP32 to INT8, the conversion is expected to be smooth, and can in several cases be done directly.
For networks that were already problematic to convert to INT8 from FP32 with simple PTQ techniques, mostly networks with significant outliers, similar issues will arise when converting from FP8 to INT8. However, since these latter networks are trained to deal with the reduced precision of the FP8 format, the INT8 conversion results from FP8 are better when compared against INT8 simple conversion from FP32. Moreover, INT8 QAT can be further employed to recover more accuracy in such cases.
The path towards better AI inference on device
Overall, integer quantization is still the way to do efficient AI inference. With varying effort levels, you can achieve significant efficiency benefits without sacrificing much accuracy.

Figure 5: The INT quantization paradigm.
For optimizing networks even further, opting for QAT can get the networks into the W4A8 (4-bit weight and 8-bit activation) regime. This is very achievable for a wide range of networks. Transformer-based large language models such as GPT, Bloom and Llama tend to benefit greatly from this jump in efficiency from 8- to 4-bit, as they are weight-bounded. Several works have shown that 4-bit weights are not only possible for large language models, but this is also optimal and possible to do in the PTQ setting. This is an efficiency boost that currently does not exist in the floating-point world.
To sum it all up, we see that floating-point format FP8-E4 is not a replacement for INT8 in terms of performance and accuracy. In most cases, they perform worse. Only in some extremely specific scenarios where layers have significant outliers, can the floating-point format perform better in terms of accuracy. We are confident that our proposed solutions will lead to a better and more seamless implementation of large AI models on edge devices. For this purpose, the Qualcomm Innovation Center has open-sourced the AI Model Efficiency Toolkit (AIMET). This allows developers to quantize their models more easily and implement AI on device more efficiently.
More of the latest in AI technology
Vinesh Sukumar
Senior Director, Product Management, Qualcomm Technologies, Inc.
Tijmen Blankevoort
Director, Engineering, Qualcomm Technologies Netherlands B.V.