
This blog post was originally published at Digica’s website. It is reprinted here with the permission of Digica.
In the previous article, I described attention mechanisms by using an example of natural language processing. This method was first used in language processing, but this is not its only usage. We can also use attention mechanisms in another major field, for computer vision.
Images can be presented as multichannel matrices. For example, RGB images have dimensions: height, width and also three channels for each colour.
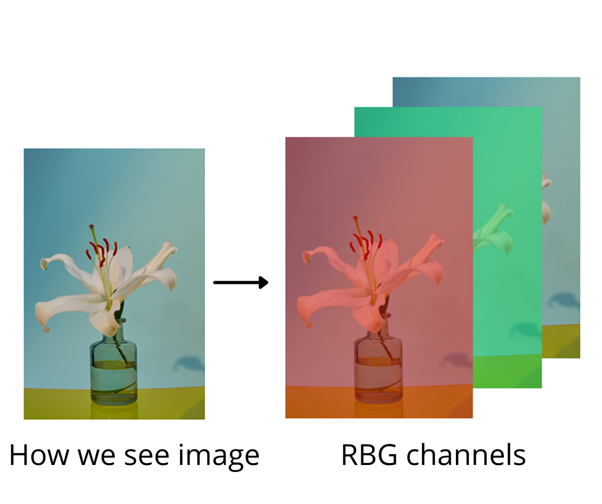
An attention mechanism can be applied to the channels.
Channel Attention Module (CAM) is the method which helps a model to decide “what to pay attention to”. This is possible because the module adaptively calculates the weights of each channel. The first concept of channel attention was presented in an article which introduced Squeeze-and-Excitation Networks: https://arxiv.org/abs/1709.01507.
In this type of network, the input is an image with three dimensions (channels x height x width). The first layer is Global Average Pooling (GAP), where feature maps are reduced to a single pixel, and also each channel is converted to a 1×1 spatial dimension. This layer produces a vector which has a length that is equal to the number of channels, and its shape is: channels x 1 x 1. This vector goes to the MultiLayer perceptron (MLP), which has an input that is equal to the ratio of the number of channels and the ratio of reduction. If this ratio is high, fewer neurons are in the MLP. In the output of the MLP there is a sigmoid function that maps values within the range of 0 to 1.
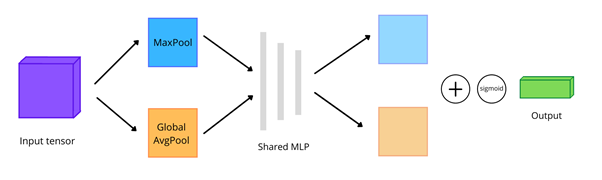
The difference between a Channel Attention Module and an SE Network is that Global Average Pooling generates not one, but two, vectors of shape (channels x 1 x 1). One vector is generated by GAP, and the second vector by Global Max Pooling. The advantage of this solution is that there is more information. Max-pooling can also provide features based on contextual information, such as edges. Average pooling loses this information because it gives a more smoothing effect. Both vectors are summed up and passed through sigmoid activation to generate weights of channels.
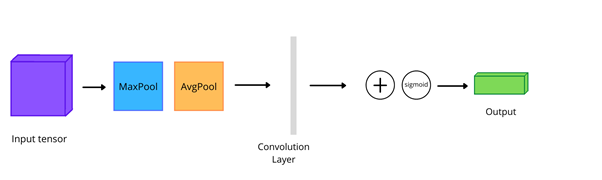
Attention mechanisms can be used to help the model to find “where to pay attention”. Spatial Attention Module (SAM) is useful for this task. There are three steps in using this method. In the first part step, there is a pooling operation through channels, where input in a shape (channels x height x width) is decomposed to two channels, which represent Max Pooling and Average Pooling across the channels in the image. Each pooling generates a feature map with the shape of: 1 x height x width. After that, there is a convolutional layer and batch norm layer for normalizing output. And, at the end, just like in the attention module described above, a sigmoid function is used to map values in the range of 0 to 1. This SAM is then applied to all the feature maps in the input tensor using a simple element-wise product.
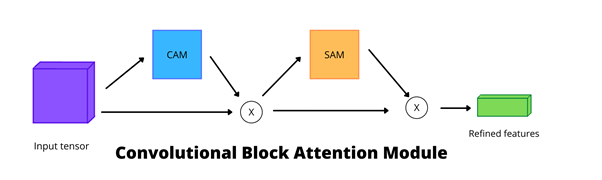
It is also possible to join those two methods together, which creates a Convolutional Block Attention Module (CBAM). This can be applied as a layer to every convolutional block in the model. It needs a feature map, which is generated by a convolutional layer, first from an applied CAM, and then from a SAM. After that, there are refined feature maps in the output.
The attention mechanisms described in this article provide very effective and efficient methods of improving results in a wide range of tasks related to computer vision, such as image classification, object detection, image generation and super-resolution.
Joanna Piwko
Data Scientist, Digica