
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Advanced techniques powering fast, efficient and accurate on-device generative AI models
As generative artificial intelligence (AI) adoption grows at record-setting speeds and computing demands increase, on-device AI processing is more important than ever. At MWC 2023, we showcased the world’s first on-device demo of Stable Diffusion running on an Android phone. We’ve made a lot of progress since then.
Fresh off of Snapdragon Summit 2023, we showed several amazing generative AI demos on smartphones powered by Snapdragon 8 Gen 3 Mobile Platform and laptops powered by Snapdragon X Elite Platform. Now, you’ll get a peek behind the curtain as I cover advanced techniques coupled with full-stack AI optimizations by Qualcomm AI Research to make these on-device generative AI demo experiences fast and efficient. Be sure to check out my webinar for more in-depth details.
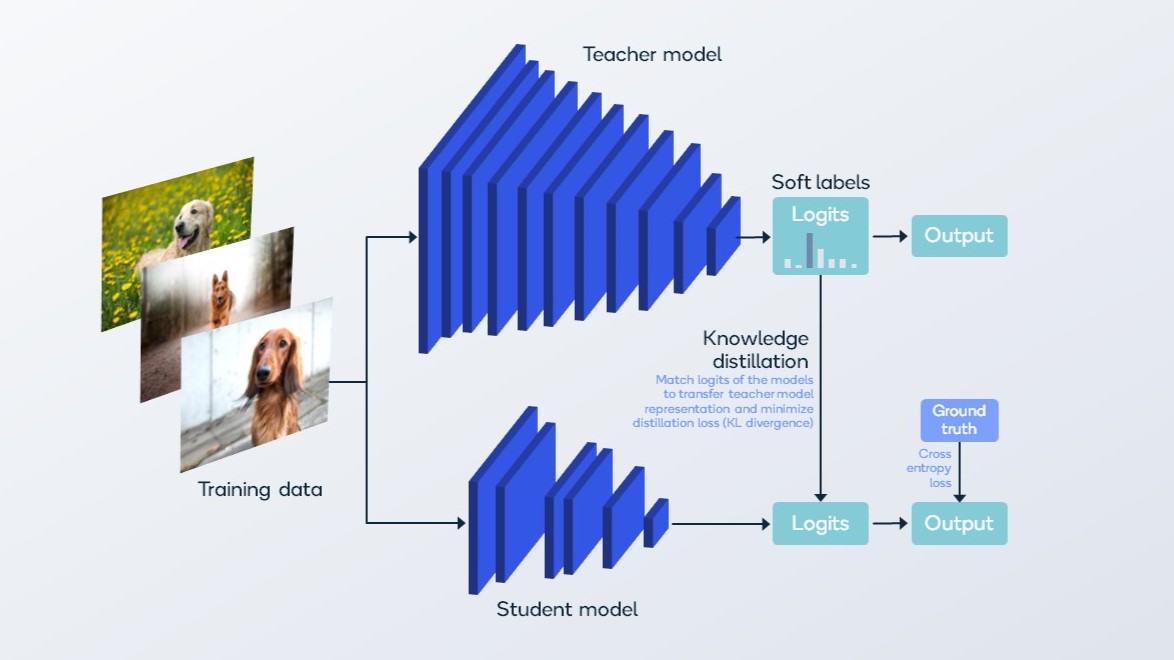
Knowledge distillation trains a much smaller student model to mimic a larger teacher model.
Efficient AI through knowledge distillation and quantization-aware training
Two powerful AI techniques that we used to make models smaller, faster and more efficient are knowledge distillation and quantization.
Knowledge distillation is a transfer learning method, where you train a smaller “student” model to mimic a larger “teacher” model while maintaining as much accuracy as possible. How it works is you try to match the logits of the models, thereby transferring the teacher model representation to the student and minimizing the distillation loss. The benefits of knowledge distillation are that it creates a smaller model resulting in faster inference, without needing to use the same training pipeline needed for the teacher.
Quantization reduces the bit precision used to represent the weight parameters and activation calculations. We have done foundational research to reduce quantization errors and develop techniques to overcome them — many of these techniques realized now in the AI Model Efficiency Toolkit (AIMET), accessible through the Qualcomm AI Stack and GitHub. Post-training quantization requires no training but sometimes cannot achieve the desired accuracy when going to certain bit precisions. In that case, quantization-aware training allows the model to maintain more accuracy by simulating quantization during a subsequent fine-tuning process to reduce the loss.

Our full-stack AI optimizations for fast Stable Diffusion included system optimization, model efficiency, compilation and hardware acceleration.
Achieving the world’s fastest Stable Diffusion on a phone
At Snapdragon Summit, we demonstrated our fast implementation of Stable Diffusion running at less than one second.
How did we achieve that? Stable Diffusion, as its name implies, is a diffusion model that generates images through a reverse diffusion process that is conditioned based on the input prompt. To speed it up, the bottleneck needs to be identified.
In the Stable Diffusion architecture, the UNet is the biggest component model and is repeated many times to denoise the image for a number of steps until the output image is created. Often, 20 steps or more are used for generating high-quality images. Repeating the UNet is the compute bottleneck. Therefore, our system optimizations focused on reducing the overall computations needed in the denoising process.
Our research then applied knowledge distillation toward developing an efficient UNet, guidance conditioning and step distillation. For example, we pruned the attention blocks in the first layer of the UNet, which saves significant compute, and we were able to recover the accuracy of the model through knowledge distillation. To reduce the number of steps, we again used knowledge distillation in which the student model is taught to achieve accuracy closer to a teacher, which uses many more steps.

Our fast implementation of Stable Diffusion produces image quality similar to the original model.
Our results: fast image generation at nice quality
By combining all of these approaches, we developed the world’s fastest diffusion-based text-to-image generation on a phone. We achieved a 9x speedup versus the baseline Stable Diffusion when running on a phone powered by Snapdragon 8 Gen 3 — it’s also an over 25x speedup beyond what we achieved at MWC 2023 on phone.
In terms of image quality, we had very promising results in perceptual metrics given by CLIP and FID as well as nice qualitative results that you can see in the images above. Overall, generating high-quality images in under a second results in a great user experience and opens the door to even more generative AI use cases.
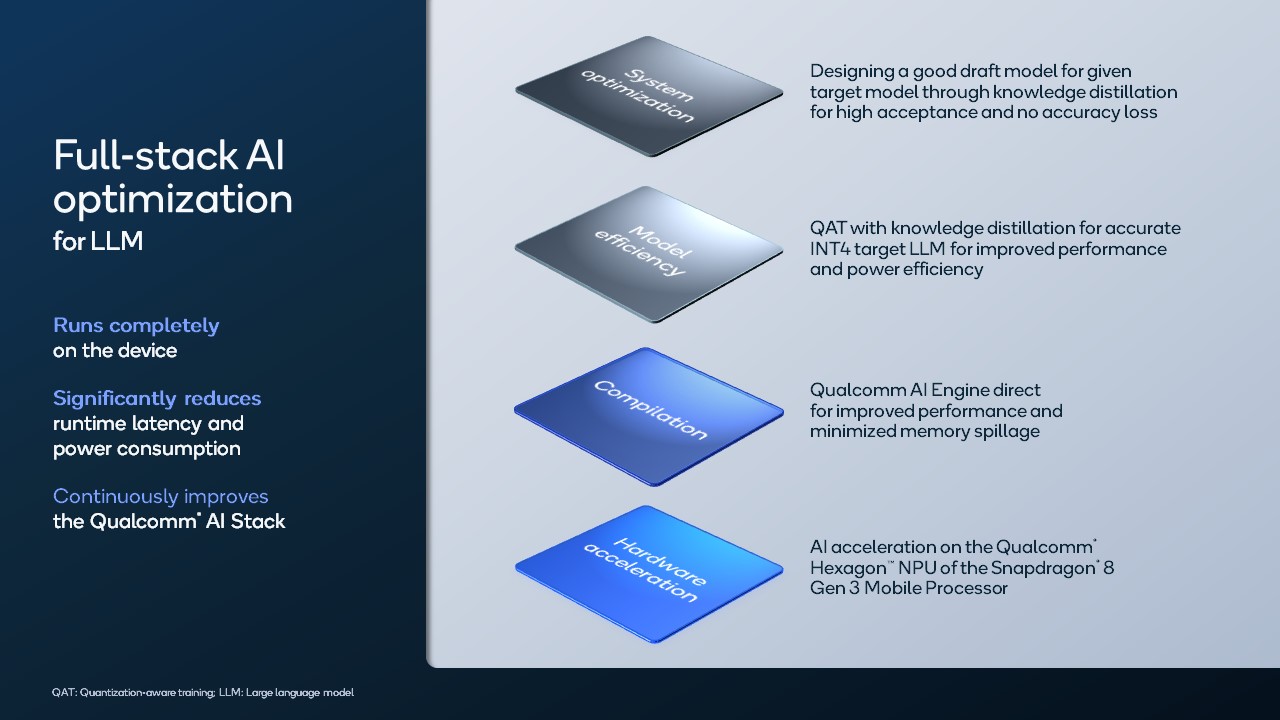
Our full-stack AI optimizations for fast Llama 2 utilized knowledge distillation, quantization-aware training, and speculative decoding.
Achieving the world’s fastest Llama 2-7B on a phone
To optimize a large language model (LLM) like Llama 2, it’s good to start with knowing where it’s bottlenecked. LLMs are autoregressive models, which means that future output values depend on its own previous values, so processing needs to be sequential.
LLMs generate a single token per inference, and each token is a unit of language generation like words, numbers, punctuation and so forth. All the parameters of the LLM are used to generate each output token of a response. For example, for Llama 2-7B, seven billion parameters must be read to generate each token, which means that significant bandwidth is required to read these weights for the computations. Compounding this, LLMs need to generate many tokens for typical responses in chatbot applications, such as a few sentences in a few seconds.
As a result, memory bandwidth is the bottleneck for LLMs, which means that they are bandwidth limited rather than compute limited. This insight drove our research to pursue the best ways to accelerate an LLM on device. We reduced the memory bandwidth through knowledge distillation, quantization-aware training, and speculative decoding.
Quantization-aware training with knowledge distillation
Llama 2 was trained with floating-point 16 (FP16), but we want its parameters to be 4-bit integer (INT4) to shrink the model by 4x. However, quantizing to an INT4 model can be challenging for a few reasons, such as post-training quantization may not be accurate enough, or the training pipeline (e.g., data or rewards) may not be available for quantization-aware training.
We use quantization-aware training with knowledge distillation to address these challenges and achieve an accurate and smaller INT4 model. Our results are a less than a one point drop in perplexity, which is a typical metric for LLM generation capability, and less than 1% drop in accuracy for reasoning tests.
Speculative decoding
Since LLMs are memory bound, we can use a speculative decoding method to speed up token rate by trading off compute for memory bandwidth, improving the user experience. Speculative decoding works by having a draft model, which is significantly smaller than the high-accuracy target model, rapidly and sequentially generate speculative tokens one at a time, and then by having the original target model check and correct these draft tokens.
As an example, let’s say the draft model sequentially generates three speculative tokens. The target model then processes all three speculative tokens in one model pass (as a batch), which means that the parameters of the model are read only once per pass. The target model decides which tokens to accept. Since LLMs are so memory bound, speculative decoding can lead to substantial speedup.
Our subsequent implementation became the world’s first demonstration of speculative decoding running on a phone, using the Llama 2-7B Chat model as the target. Using speculative decoding and other research techniques mentioned above to optimize Llama 2-7B, chat ran up to 20 tokens per second on a phone powered by Snapdragon 8 Gen 3.
We achieved the world’s fastest Llama 2-7B on a phone, demonstrating chat with an AI assistant that runs completely on the device.
Hybrid AI distributes processing between edge devices and the cloud.
Continuing to advance on-device generative AI
To scale, the center of gravity of AI processing is moving to the edge. On-device AI capabilities are key to enabling hybrid AI and allowing generative AI to reach global scale. How processing is split between the cloud and edge devices will depend on several factors, such as the capabilities of the device, privacy and security requirements, performance requirements and even business models.
We’ll continue to apply full-stack AI optimizations to our solutions and continue to push the limits of silicon at the edge. In less than 10 months, we have come so far and have dramatically accelerated generative AI on edge devices. I can’t wait to see how much further we can push it, and what the ecosystem will build with it.
Dr. Joseph Soriaga
Senior Director of Technology, Qualcomm Technologies