
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Find out how Qualcomm AI Research reduced the latency of generative AI
Generative artificial intelligence (AI) is rapidly changing the way we create images, videos, and even three-dimensional (3D) content. Leveraging the power of machine learning, generative AI can now create stunning, high-quality content in a fraction of the time it would take to create it manually. This technology is already being used in a variety of industries, from entertainment to advertising to extended reality (XR).
But at what cost? While this technology has immense potential, it faces challenges because the machine learning models have high computation, large memory requirements and data inefficiency. As generative AI adoption grows at record-setting speeds, running it on device is key, as it brings with it advantages in cost, performance, energy, personalization and privacy. We asked ourselves how we can make this technology more efficient and eventually bring it on device.
The main challenges for generative AI to overcome are:
- High computation and latency: Generative AI requires immense computational power and infrastructure.
- Memory costs: Models demand a lot of memory to perform well and sometimes need to run concurrently.
- Data inefficiency: Models require billions of training samples and that makes it hard to adapt them to new domains.
Qualcomm AI Research has achieved state-of-the-art results in efficient generative AI for computer vision, and our on-demand webinar covers some key techniques developed that address these challenges.

Low-resolution and high-resolution features degrade from perturbations at a different pace.
Efficient image generation
Many realistic images and high-quality artworks are being generated by text-to-image models, like Stable Diffusion, with simple prompts. But how does that work? The UNet neural network is the biggest component model of Stable Diffusion and runs through several iterations to generate high-quality images, often more than 20 steps and consuming significant compute.
We set out to reduce the number of computations for the UNet. We discovered that it would be more efficient to run the UNet differently during sampling steps by alternating between processing the high-resolution paths (attributed to generating textures) and the low-resolution paths (attributed to generating scene layout). This is driven by our observation that the low-resolution features of a denoising UNet can be severely perturbed from the early diffusion steps without degrading the quality of the generated image (as seen in the image above).

The results from our Clockwork method are impressive both for image generation and for image editing tasks.
Clockwork architecture
We developed the Clockwork architecture, which creates an efficient approximation of low-resolution features by adapting from previous steps. This leads to lower compute and latency in generating imagery, while improving quality compared to Fast Stable Diffusion. More specifically, we see a 1.2 times speedup from previous state-of-the-art results. This holds true not only for generating images from scratch, but also for image editing tasks.
The possibilities of efficient image generation are endless. As this technology continues to develop, we can expect to see even more innovative, and ground-breaking uses for it in the years to come.

Our object-centric diffusion method is much faster than the current state-of-the-art video generation.
Efficient video generation
Video generation is another impactful application of generative AI that is ideal for applications, such as live streaming, virtual reality and augmented reality, where real-time video generation is essential. Given an input video and a text prompt describing the desired edit, the algorithm can generate a new video. These algorithms can edit the appearance or shape of a particular object as well as editing the holistic style of the scene. There are two key challenges to video generation and editing:
- Temporal consistency
- High computational cost
The state-of-the-art methods achieve a desired temporal consistency by relying on diffusion inversion and temporal attentions. Despite their effectiveness, both diffusion inversion and temporal attention comes at a high computational cost due to their memory and computational overheads.
Token merging
We propose object-centric diffusion to leverage the temporal redundancies existing in a video to reduce the memory and computational costs. More specifically, we propose a novel token merging method that merges the redundant tokens both in spatial and temporal dimensions especially on the background regions that are proven to be highly compressible.
After merging the redundant tokens, we perform computation on clusters and finally copy the output back into merged tokens. Moreover, we propose an object-centric diffusion sampling that performs more denoising steps around the foreground regions while reducing the sampling steps on the background regions without introducing bordering artifacts between the two regions. Our method leads to six to 10 times speedup in video generation with negligible drop in quality.
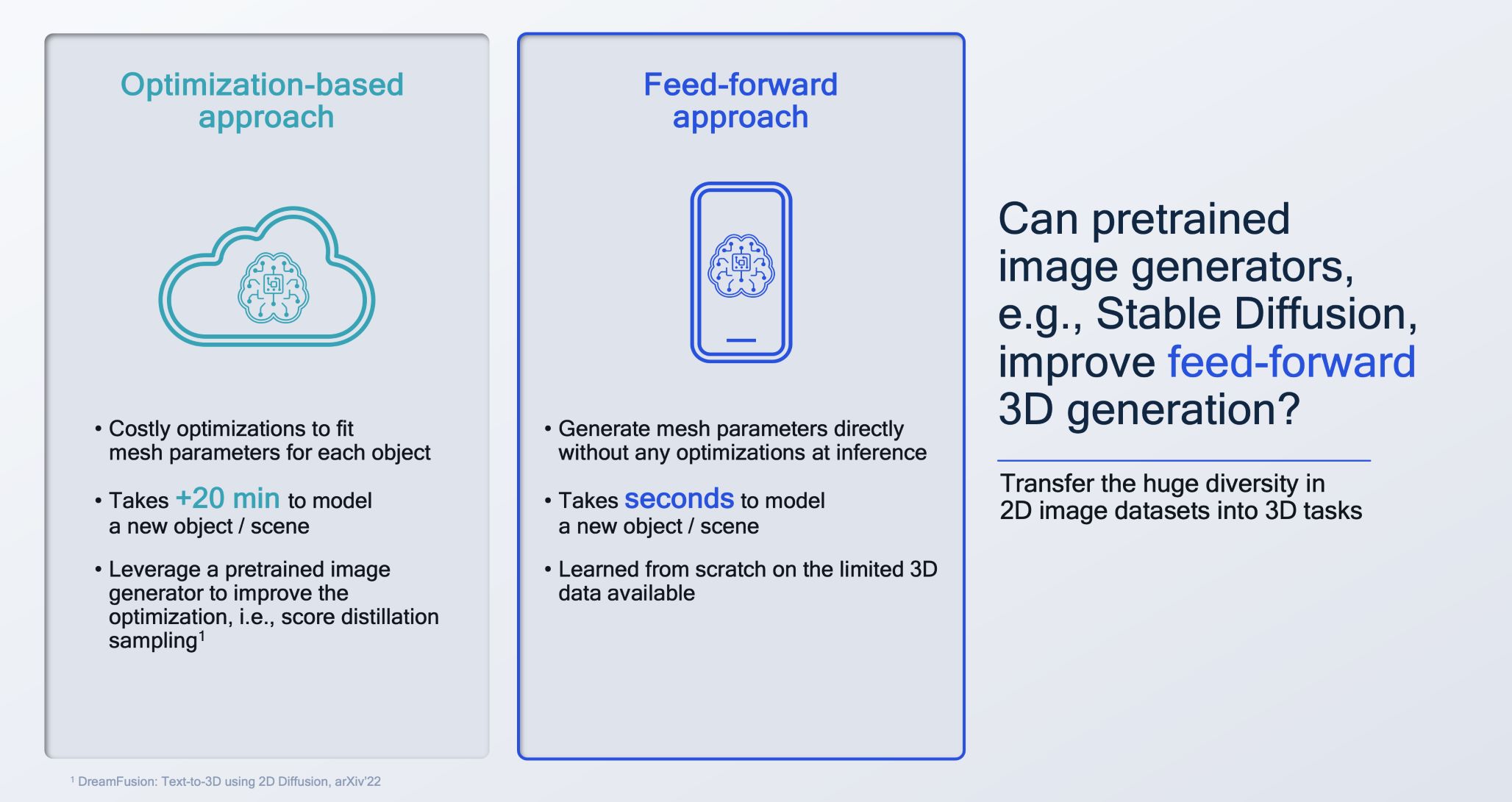
Can we get the best of both worlds for 3D generation, namely the high-quality output of optimization-based models and the low latency of zero-shot models?
Efficient 3D generation
Generative AI can also be used to create highly detailed 3D data with fewer resources and in less time than classic data gathering and creation. This can be a huge advantage for product design, architecture, engineering, XR and other applications.
The machine learning methods for generating the 3D meshes can currently be grouped under either optimization-based approaches or feed-forward approaches. Optimization-based approaches generate high-quality objects but take over 20 minutes to optimize the 3D parameters for each new object, while feed-forward based approaches are fast as they directly predict 3D parameters, i.e. by a generative model.
Training a foundation 3D generation model requires large-scale training data (e.g., billions of 3D objects), something that does not exist currently. As an alternative, we explore whether using billions of images, as encoded in a pre-trained 2D image generation model such as Stable Diffusion, can improve the 3D generation.

Our HexaGen3D method generates high-quality 3D data in only 7 seconds on server GPUs.
HexaGen 3D
Our method, called HexaGen3D, adapts a pre-trained Stable Diffusion model to generate 3D meshes in a triplanar latent representation. Compared to the optimization-based approaches, our HexaGen3D method significantly reduces the generation time from 22 minutes to seven seconds only, while preserving a good image quality.

VaLID performs better than the other models on all key metrics.
Variable Length Input Diffusion
Similarly, we tackled the challenge of Novel View Synthesis for 3D data, namely generating a novel view of an object from a target pose. How can we enable feed-forward model to handle multiple views without increasing compute? We developed a technique called VaLID (Variable Length Input Diffusion). This method tokenizes each view, aggregates over views, and uses the multi-view tokens as cross-attention conditioning. In this way, we avoid increasing the computations when fusing more views. Our method outperforms existing state-of-the-art results in quality, at a negligible computational cost.
Generative vision holds immense promise in revolutionizing image and video generation across various industries such as enterprise, entertainment, XR and automotive. The ability to efficiently generate visual content is crucial for achieving scalability, both in the cloud and on device. Recognizing this significance, Qualcomm AI Research has made remarkable strides in this field, attaining state-of-the-art results through the application of innovative techniques in image and video generation. This work paves the way for advancements that will shape the future of generative vision technology.
Watch the “Efficient generative AI for images and videos” on-demand webinar
Amirhossein Habibian
Director of Engineering, Qualcomm AI Research, Qualcomm Technologies Netherlands B.V.
Armina Stepan
Senior Marketing Comms Coordinator, Qualcomm Technologies Netherlands B.V.