This blog post was originally published at BrainChip’s website. It is reprinted here with the permission of BrainChip.
TENN, or Temporal Event-based Neural Network, is redefining the landscape of artificial intelligence by offering a highly efficient alternative to traditional transformer models. Developed by BrainChip, this technology aims to address the substantial energy and computational demands of existing AI systems. TENN specializes in sequential, or continuous data streams for edge and event-based processing, making it ideal for applications in smart home, automotive, healthcare, and industrial sectors.
By integrating the concepts of state space models, entirely developed in parallel, independently, and from a generalization of convolution kernels, TENN can handle various transformer tasks such as processing language, time-series, and spatiotemporal data. This capability not only broadens its applicability but also enhances its efficiency, offering a reduction in energy consumption by orders of magnitude compared to traditional models.
The Evolution of Kernel Representation
 |
 |
 |
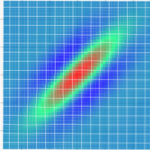
Figure 1. A) Receptive field of a simple cell in V1 (DeAngelis, et al, 1995), B) A Gabor Model of the receptive field of simple cell. C) Learned receptive fields of a CNN (Brachmann & Redies,2016)
The path from biological neurons to artificial neural networks has witnessed several innovations, with each step bringing us closer to more efficient and capable AI systems. Initially, fixed, non-learnable kernels like the Gabor filter above mimicked the visual processing of the human brain Figure 1A, focusing on specific features within visual stimuli Figure 1B. These early models laid the groundwork for more complex representations.
With the advent of deep learning, learnable kernels became prevalent, allowing AI models to adapt their filters based on the data they processed (Figure 1C). However, this flexibility comes with increased computational demands and a surge in the number of parameters. TENN addresses these challenges by revisiting the foundation of kernel representation. It uses a structured approach to reduce parameter explosion and discretization issues, thereby maintaining computational efficiency while retaining flexibility.
Leveraging Polynomials for Advanced Data Representation
TENN utilizes a novel approach by employing orthogonal polynomials, such as Chebyshev and Legendre polynomials, to represent the convolution kernel. This mathematical technique allows TENN to achieve exponential convergence rates in approximating most kernels, even those characterized by discontinuities or complex behaviors. The choice of polynomials ensures that the network can dial in the desired accuracy while maintaining efficiency, even in challenging conditions. It also permits changing discretization, binning, input resolution and frame rate without the need to retrain.
The integration of these polynomials into TENN’s architecture allows to transform the network kernel convolutional computations from a buffer mode to a recurrent mode without loss of accuracy or retraining. The buffer mode facilitates efficient training on parallel hardware whereas the recurrent mode permits smaller memory footprint for data processing at the edge. This duality in processing modes ensures stable training and fast execution, which are crucial for real-time AI applications.
TENN’s Dual Modes: Enhancing Flexibility and Efficiency
One of the standout features of TENN is its dual-mode operation, which includes kernel convolutional computations in buffer and recurrent modes. This flexibility allows TENN to adapt to different computational tasks efficiently. In buffer mode, TENN behaves like traditional convolutional neural networks, processing data through various layers of kernel convolutions. In recurrent mode, it leverages the recurrence relationships of classical orthogonal polynomials to process data sequences more naturally and efficiently with much smaller memory requirements.
This dual capability not only makes TENN versatile but also enhances its performance across a wide range of applications. From real-time language translation to complex data analysis in autonomous vehicles, TENN’s dual modes enable it to deliver high performance during training while minimizing energy usage for inference at the edge.
Implementation and Future Directions
The implementation of TENN within BrainChip’s hardware in the Akida 2.0, showcases a significant step forward in hardware-accelerated AI. Akida 2.0’s architecture is designed to fully exploit TENN’s capabilities, featuring a mesh network of nodes each equipped with an event-based TENN processing unit. This design ensures scalability and enhances computational efficiency, making it suitable for deployment in environments where power and space are limited.
Looking ahead, BrainChip plans to continue refining TENN’s capabilities, focusing on enhancing activation sparsity and exploiting more of the polynomial space. These advancements are expected to further improve the efficiency and applicability of TENN in more complex AI tasks.
Broad Applications and Impressive Performance
TENN’s application range is impressive, extending from audio processing tasks like noise reduction and speech recognition to more demanding applications such as biomedical signal processing and industrial monitoring. Its ability to efficiently process large volumes of data in real-time makes it a potent tool for developing advanced AI applications in various sectors.
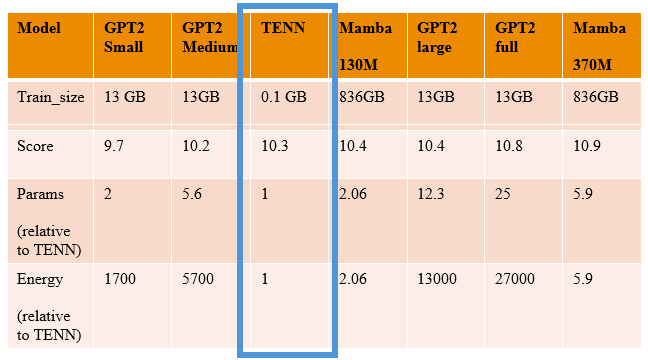
Figure 2. Comparison of TENNs on an NLP task sentence generation. The score we use is related to perplexity but transformed to so that the higher the score the better.
Performance metrics indicate that TENN not only holds its own against larger models like GPT-2 but often exceeds them in efficiency and speed, particularly in tasks that benefit from its event-based processing capabilities. TENN produced text at the rate of 2500 words/min vs 10 words/min on the same laptop CPU, single threaded performance.
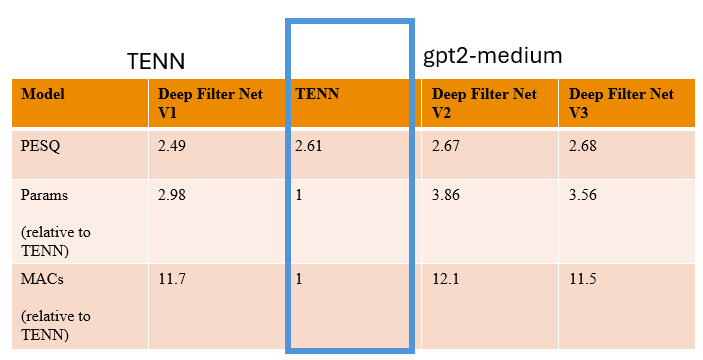
Figure 3. Audio denoised on standard benchmark. TENN processes audio directly, saving a power consuming data conversion step.
On speech enhancement through denoising, TENN was compared to the state of the art (SoTA) networks. While providing almost the same performance with this particular implementation, the number of parameters and number of operations (MACs) with TENN are nearly 3 times and 12 times less.
TENN is a spatiotemporal network that performs as well with visual inputs in either image sequence format or event-based visual data. Below is an example of gesture recognition on the DVS Hand Gesture Recognition dataset (IBM DVS128).

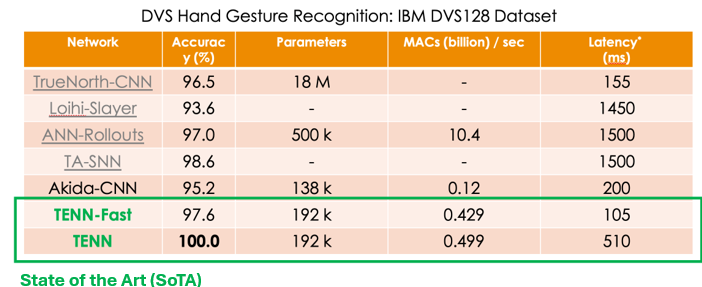
These results highlight TENN’s potential to reshape the future of AI, making it more accessible and sustainable.
Conclusion: A New Era of Efficient AI
BrainChip’s development of TENN marks a significant milestone in the evolution of artificial intelligence. By addressing key challenges related to power consumption and computational efficiency, TENN is poised to lead a new era of AI technology. As it continues to evolve, its impact is expected to grow, opening new possibilities for smart technology across global industries.
Dr. Tony Lewis
CTO, BrainChip
Olivier Coenen
Senior Research Scientist, BrainChip
Yan Ru Pei
Research Scientist, BrainChip