
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Not all TOPS are created equal — let’s demystify how TOPS measurement can reflect AI performance
What you should know:
-
While TOPS is a useful metric to evaluate the performance of neural processing units, it can be misleading if not properly understood. At Qualcomm Technologies, TOPS usually refers to dense TOPS, which represents the true hardware performance of the processing unit
-
Some companies disclose sparse TOPS, which is achieved using sparsity methods to run neural networks more efficiently on hardware. While sparsity comes with advantages, this method tends to reduce neural network accuracy, requires additional effort during training, the need for more complex hardware and software and introduces a more complex developer workflow.
-
Industry benchmarks and tangible use cases can also give insight on the real-world performance and efficiency of AI processors in practical situations, making the metrics more relevant and understandable than just abstract numbers.
In our previous blog post, “A Guide to AI TOPS and NPU Performance Metrics,” we explored the significance of tera operations per second (TOPS) in evaluating the performance of neural processing units (NPUs) for edge computing. We discussed how TOPS, while a useful metric, can be misleading if not properly understood. In this follow-up, we will dive deeper into the importance of identifying the two common ways of measuring AI performance — dense versus sparse TOPS — and provide a comprehensive look at both. We’ll also touch on two aspects that ultimately determine the AI capabilities of a processor: the real-world AI benchmarks, and actual AI use cases that users experience every day.
Dense TOPS — what is it?
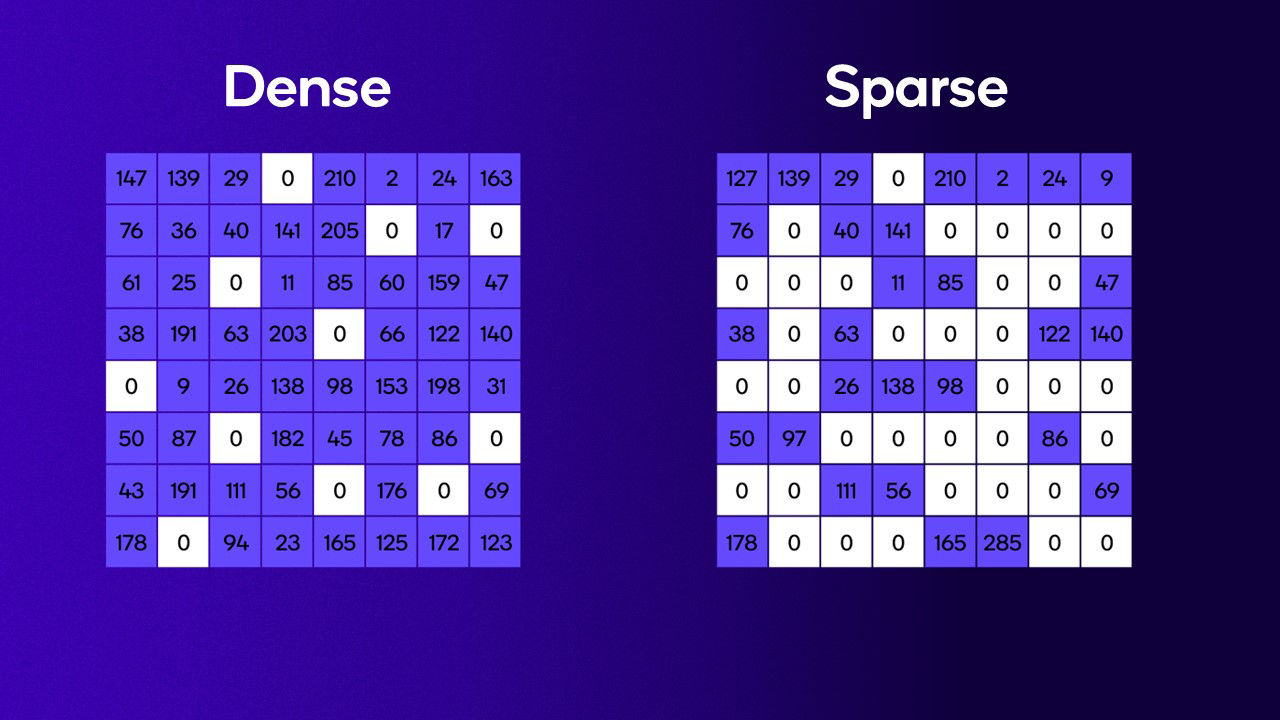
In the previous blog, the TOPS we mentioned is what the industry calls dense TOPS. It’s a reliable and straightforward metric that measures the peak-compute capability of a processing unit for neural-network tasks. Modern neural networks rely heavily on matrices and matrix operations. The term “dense” originated from “dense matrix”, an unmodified matrix where most or all of the elements are non-zero.
Dense TOPS reflects the number of multiply-accumulate (MAC) units available in the processing unit at a specific precision format (e.g., INT4, INT8, FP16), providing a clear indication of the hardware’s theoretical performance. It’s important to pay attention to the specifications of the supported precision formats since the TOPS and floating point operations per second (FLOPS) could significantly vary, with lower-precision formats generally having significantly more operations per second. For AI applications, dense TOPS offers a practical and realistic measure of performance.
At Qualcomm Technologies, we use dense TOPS to represent Qualcomm Dragonwing and Snapdragon products’ neural processing capabilities.
Sparse TOPS — what is it?
You might have seen different ways companies disclose TOPS figures. Some use sparse TOPS, which is a very different way of looking at hardware performance. The term “sparse” originated from “sparse matrix”, which primarily contains zeros, unlike a dense matrix which contains mostly non-zero elements. For hardware designed to leverage sparse matrices, there can be benefits in terms of latency.
There are two ways to achieve sparsity. One is called unstructured sparsity, where the elements are turned into zero in no specific order.
Figure 2: Unstructured sparsity.
The other method is called structured sparsity, which consists of applying a bitmask to a given neural network, usually in a 2:4 pattern, to structurally turn two elements into zero within every four continuous elements.
Figure 3: 2:4 structured sparsity.
While sparse matrices come with advantages, this method tends to reduce network accuracy, requires additional effort during training, the need for more complex hardware and software and introduces a more complex developer workflow.
With the 2:4 sparsity method and a processing unit that supports it, a 50 dense TOPS processor is the equivalent of having 100 sparse TOPS.
sparse TOPS (2:4 sparsity) = 2x dense TOPS
When comparing TOPS between products, it is best to identify whether the metric refers to dense or sparse TOPS — and at what precision. At Qualcomm Technologies, TOPS usually refers to dense TOPS, which represents the true hardware performance of the processing unit.
An alternative to sparse matrices: Quantization
There are other ways of allowing hardware to run neural networks more efficiently, such as quantization. This technique refers to the process of reducing the precision of elements and operations. Instead of turning elements in the neural network to zero, as the sparsity method would, quantization keeps all the elements in the neural network and converts them from a higher precision to a lower precision. This results in a decreased model size and increased computational efficiency. Note that the hardware needs to support precision format to fully harness the computational efficiency.
Our self-developed quantization techniques, such as the AI Model Efficiency Toolkit (AIMET) library, provide advanced quantization and compression techniques for trained neural network models to make the models smaller and leaner so the hardware is better utilized.
For example, quantizing a model from FP16 to INT8 can speed up model inference by two times, and even higher by going to INT4. This makes performance comparable and often better than sparse inference, depending on the processor’s capabilities. Analytical analysis also backs up choosing quantization. Our research paper accepted at NeurIPS, “Pruning vs Quantization: Which is Better?”, concluded that quantization generally outperforms pruning sparsity for neural networks.
Figure 4: A 4-bit quantization to fit two 4-bit elements.
The importance of benchmarks and real-world use cases
Metrics like TOPS is just one piece of the puzzle to true AI performance. It’s like comparing horsepower on a car without factoring in the car’s type, weight, tires, suspension, etc. On a racetrack, the same horsepower in a sedan will get you very different results than in a semi-truck.
To truly understand how a processor performs in practical applications, it’s essential to evaluate it using real-world benchmarks and actual use cases. AI benchmarks and use cases help bridge the gap between theoretical metrics and real-world performance, where factors like latency, throughput and energy efficiency are crucial.
To evaluate the real-world performance of processors, several key performance indicators (KPIs) are essential:
- Inferences per second (IPS): Measures performance of an AI model by measuring its IPS running on the AI processor, providing a direct indication of the hardware’s capabilities.
- Power efficiency (performance per watt): Evaluates the energy efficiency of the AI processor, which is particularly important for edge devices where power consumption is a significant concern.
- Double data rate (DDR) bandwidth usage: Indicates how efficiently the AI processor uses memory bandwidth, which can impact overall performance and power consumption. For memory-bound applications, memory bandwidth rather than compute TOPS is the bottleneck (e.g., LLM token generation).
- Time to first token (TTFT) and time per output token (TPOT) for LLMs: Measures the time it takes for an AI model to generate the first output token after receiving an input, and the average time it takes for an AI model to generate each subsequent token in the output sequence. Both metrics indicate the responsiveness of AI tasks.
In addition to metrics, it’s important to consider the variables that impact the performance of hardware and software AI processing capabilities, including the number of parameters of the model, context size, precision and batch size.
Notable AI benchmarks
Several benchmarks are available to evaluate AI’s real-world performance. For example, MLPerf, AI-Benchmark and Antutu feature benchmarks that can be used to evaluate the performance of mobile hardware.
- MLPerf: A widely recognized benchmark suite that measures the performance of machine-learning hardware, software and services. MLPerf includes a variety of tasks, such as image classification, object detection and translation, and provides detailed insights into the performance of different NPUs. Our Snapdragon 8 Elite is currently ranked the No. 1 in the mobile MLPerf inference leaderboard.
- AI-Benchmark: A comprehensive benchmark that evaluates the AI performance of mobile devices. It includes a range of tests, such as image recognition, object detection, and natural language processing, providing a detailed score that reflects the overall AI capabilities of the device. Our Snapdragon 8 Elite is also currently ranked the No. 1 in this leaderboard.
- Antutu: A benchmark that focuses on the end-to-end performance of machine-learning models, including training and inference times. Antutu is particularly useful for evaluating the efficiency and scalability of NPUs in real-world scenarios, providing a holistic view of performance across various tasks and models. And no surprise, Snapdragon 8 Elite is also currently ranked No. 1 in the leaderboard.
These benchmarks help stakeholders make informed decisions by providing a more accurate and comprehensive picture of AI performance in practical applications.
The Snapdragon 8 Elite platform currently ranks No. 1 in the MLPerf, AI-Benchmark and Antutu leaderboards.
Alternative to benchmarks: Real-world use cases
Benchmarks are not the only way to evaluate AI performance. Tangible use cases that users can easily relate to can give insight on the real-world performance and efficiency of AI processors.
In spatial computing, for example, Qualcomm Technologies demonstrated the first generative AI (GenAI) conversation running on AI glasses powered by Snapdragon AR1+ Gen 1, without relying on a smartphone or the cloud. The model, Llama 3.2 1B-instruct with 1.2B parameters, delivered a six token-per-second throughput and 185 ms time-to-first-token.
In compute, we compared a local image generation experience using Stable Diffusion 1.5 and GIMP on a Snapdragon X Elite and Intel Core Ultra 7 155H CPU. The Snapdragon X Elite took 7.25 seconds to generate a single image, compared to 22.26 seconds for the Intel Core Ultra 7 155H, making the Snapdragon X Elite over three times faster. In a test generating multiple images, the Snapdragon X Elite generated 10 images while Intel Core Ultra 155H generated just one.
In the context of smart city, enterprise safety and advanced retail analytics, AI performance isn’t only about TOPS, but also the capacity of sustaining a given TOPS metric while running multiple AI streams simultaneously. We ran 35 concurrent complex AI streams on the Qualcomm Dragonwing IQ9 processor while maintaining 100 TOPS.
Similarly, our automotive SA8650P Platform, which provides 100 TOPS (38 less than the competitor’s alternative) delivers up to 30% higher inferences per second and seven times lower DDR bandwidth consumption than its competitor1 when running proprietary models.2
These real-world examples reflect applications that consumer and enterprise users might encounter in their daily lives. They help demonstrate an AI processor’s performance in practical situations within a given software and hardware context, making the metrics more relevant and understandable than just abstract numbers.
Future trends in NPU performance metrics
As technology advances and the demands of digital transformation continue to shape diverse industries, the future of NPU performance metrics is expected to evolve. While TOPS is one of many metrics that determine performance, there will be an increasing need to evaluate metrics that go beyond just raw computational power. These metrics will focus on ease of use, adaptability, scalability and relevance to real-world applications, with a particular emphasis on latency, throughput and energy efficiency.
References
- Competition processor is based on GPU architecture; performance are estimates or public data.
- Based on select automotive perception and fusion neural networks including BEVFormer, Resnet, Efficient Former, DETR.
Vinesh Sukumar
VP, Product Management of AI/GenAI, Qualcomm Technologies, Inc.