
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
AI device powered by Qualcomm Dragonwing boosts productivity and reduces cloud dependence in Capgemini’s monitoring application for grade crossings
-
Capgemini moved from their previous hardware solution to an edge AI device powered by the Qualcomm® Dragonwing™ QCS6490 platform.
-
By using the Qualcomm® Hexagon™ NPU, Capgemini reduced memory utilization by almost one-third and CPU usage by 5 percent, with an AI inference time of 18 milliseconds per frame.
-
The Dragonwing QCS6490 solution offers the benefits of long lifecycle support and inputs for up to five concurrent cameras.
When a vehicle stalls on a railway crossing, how many seconds are there to avert a train wreck?
In a modern railway communications system, the important factor is the amount of time required to detect that the vehicle is stalled. The shorter that delay, the sooner alerts can go out to train crews, railway safety managers and first responders.
In developing railway safety applications, Capgemini Engineering looked for ways to improve the productivity and execution of its artificial intelligence (AI) models to detect dangerous conditions sooner. Through an integration project with Qualcomm Technologies, Inc., Capgemini moved from their previous hardware solution to an edge AI device powered by the Qualcomm® Dragonwing™ QCS6490 platform.
Aa s result, they reduced memory utilization by 32.92 percent and CPU usage by 5 percent, with an AI inference time of 18 milliseconds per frame. By increasing the efficiency of their edge computing, they decreased the need for network transfers and cloud computing and increased the productivity of the solution by up to 40 percent.
This article describes the project in detail. AI solution architects and developers will see how to integrate smoothly from other hardware products to Qualcomm Technologies’ industrial embedded IoT processors.
Using mobile communication and AI for railway safety
For an American Class-1 freight railroad client, Capgemini developed a video analytics solution and the wayside hardware device for monitoring highway-rail grade crossings (HRGC) and mainline stretches of track. Rail operators constantly seek ways to reduce the risk of collisions with vehicles and other obstacles; in the U.S. alone, HRGC incidents occur about 2,000 times per year. Besides the financial and operational impact of such incidents, more than 40 percent of them result in a fatality or injury.
Capgemini’s device includes an AI model and algorithm to monitor crossings and mainline track and send an alert over a data network whenever the algorithm identifies a potentially dangerous condition. Appropriate railroad personnel would then handle the alert by directing affected train traffic, clearing the blockage, involving public authorities or taking other necessary measures.
To create the AI model, Capgemini used the PyTorch framework and the publicly available YOLOv8 object detection model. They trained the model with a data set of images chosen so that the algorithm could accurately predict an imminent collision. They validated the resulting model against a data set of real-time data and images. Once they were satisfied with the accuracy of the model, they deployed it to a local device dedicated to AI inference, with a connection to the cloud.
Turning to Qualcomm technology for greater productivity and efficiency
But the solution had limitations in several areas:
- Dependence on cloud – Although the local device performed inference on the video stream and transmitted results to the cloud, it used the cloud to send alerts and store data. That meant that the overall solution relied on the cloud – communication latency, network traffic, compute resources, processing time – more than Capgemini wanted.
- Memory usage – The combination of the operating system, Python, YOLOv8 model and background applications used most of the RAM on the device. Capgemini wanted a solution with a smaller memory footprint.
- Camera inputs – The device was capable of running inference concurrently on a video stream from a camera. However, Capgemini also wanted to use the same software-hardware combination for other safety use cases in railroad coaches, rail stations and rail infrastructure. That called for a device that could scale up to handle multiple concurrent video streams, with simultaneous inference against multiple AI models.
- Processing – The device ran inference on GPU, which was an improvement over running on CPU alone. However, Capgemini wanted a software-hardware combination built around a neural processing unit (NPU) that would run more efficiently with the same or better accuracy.
To overcome those limitations, Capgemini engineers turned to the Qualcomm technology built into the AIM-Edge QC01 device from Inventec. The device is powered by the Dragonwing QCS6490, designed for industrial and commercial IoT applications. The Dragonwing QCS6490 offers enterprise-grade Wi-Fi 6/6E, support for up to five concurrent cameras and a Qualcomm® Hexagon™ Processor (NPU) for AI acceleration.
The engineers’ proof-of-concept tests convinced them that performance would be better on the Dragonwing QCS6490 than on existing hardware. They proceeded to take their monitoring application for grade crossings and build it out on the Inventec device powered by the Dragonwing QCS6490.
Integrating the model with Qualcomm hardware
Figure 1 shows the steps Capgemini followed in the integration project. It was not necessary to modify the base model, so they did not need to repeat the work they had already done in training, validating, freezing and converting it to the Open Neural Network Exchange (ONNX) format.
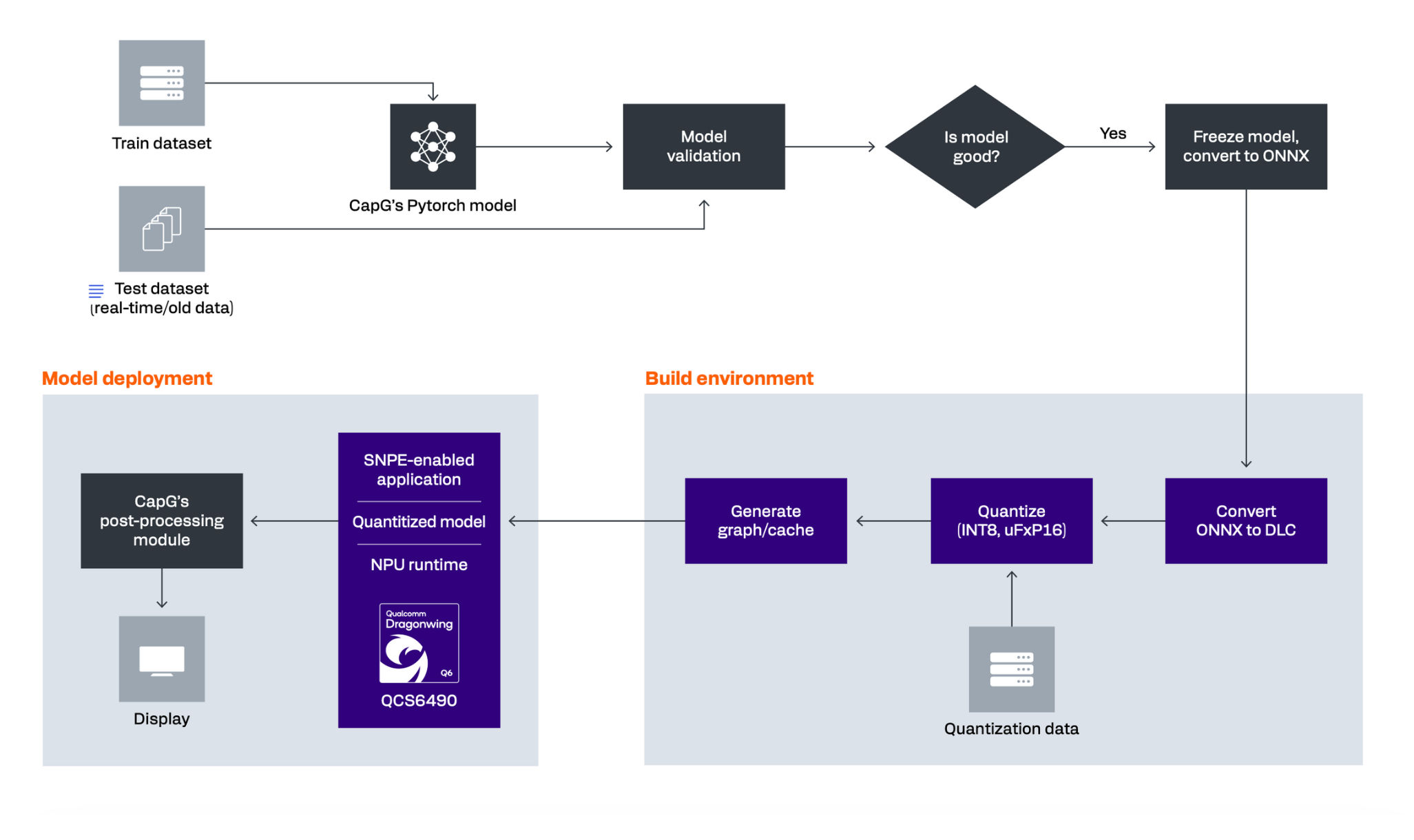
To take advantage of hardware acceleration on Qualcomm Technologies’ NPUs, the engineers modified the data pipeline for the model, first in their build environment, then in their model deployment.
1. Build environment
Customizing the model to run on NPU required changes to the data pipeline for quantization and caching. Using the Qualcomm® Neural Processing SDK and other packages provided by Qualcomm Technologies, Capgemini engineers added steps to their build process.
Convert ONNX to DLC
The engineers first converted the model from ONNX to a Qualcomm Technologies-specific DLC (Deep Learning Container) file to be used by the Snapdragon® Neural Processing Engine pipeline and NPU runtime. The conversion tool generated statistics, including information about unsupported or non-accelerated layers, that enabled the engineers to adjust the design of the initial model.
Quantize
Using the Snapdragon Neural Processing Engine pipeline and SDK tools like snpe-dlc-quant, the team fed in calibration data and set the parameters, including the level of quantization needed. Their first attempt with INT8 quantization resulted in a working model, but the accuracy was not optimal.
By adjusting the model to use FP16 activations and INT8 weights and biases, the team achieved a much more accurate model, which they successfully deployed.
After the optimal settings were determined, the engineers were able to streamline model quantization using a single Snapdragon Neural Processing Engine command.
Generate graph/cache
The Dragonwing QSC6490 includes the Qualcomm Hexagon NPU for on-device AI processing. The NPU runtime in the Qualcomm Neural Processing SDK is designed for offline graph caching. The graph can help to reduce initialization time by directly loading the cache onto the device while executing the model.
Capgemini engineers used snpe-dlc-graph-prepare to generate a graph (cache record) of the model. The tool added the generated cache into the DLC without the need to repeat the quantization step.
2. Model deployment
Once the model had been converted and quantized, and the offline cache had been prepared and added, the DLC was ready for deployment (execution).
Run preliminary tests
To verify that the model was working, the engineers first used a command-line interface (CLI) for snpe-net-run to run the DLC against a single image. They saved an image of a vehicle in a grade crossing and provided the path to it in a text file as input to the CLI.
The raw output from the preliminary test was satisfactory, so they proceeded to run the model against a sample video stream.
Execute the model on target
As shown in Figure 1, the software stack consists of a Snapdragon Neural Processor Engine-enabled application running inference on a quantized DLC model with the NPU runtime. The hardware on which the software executes is the Dragonwing QCS6490 inside the Inventec AIM-Edge QC01, running Ubuntu.
The engineers used SNPE-Helper, a Python API wrapper for a C++ API provided by the Qualcomm Neural Processing SDK, and wrote out the entire program, including the pipe-in code. Snapdragon Neural Processing Engine Helper is designed to help developers use Python to run inference on DLC models on devices powered by Snapdragon. It is open-source software designed for Yocto Linux, so Capgemini engineers were able to modify paths and move files to run it on Ubuntu.
They did not need to modify anything on the Inventec device; they built their Snapdragon Neural Processing Engine-enabled app and the quantized DLC on development workstations. They then flashed the software to the device over Wi-Fi to deploy their components and the NPU runtime. Besides Ubuntu, the device runs a Python virtual environment adequate for AI inference.
Evaluating the results of integration
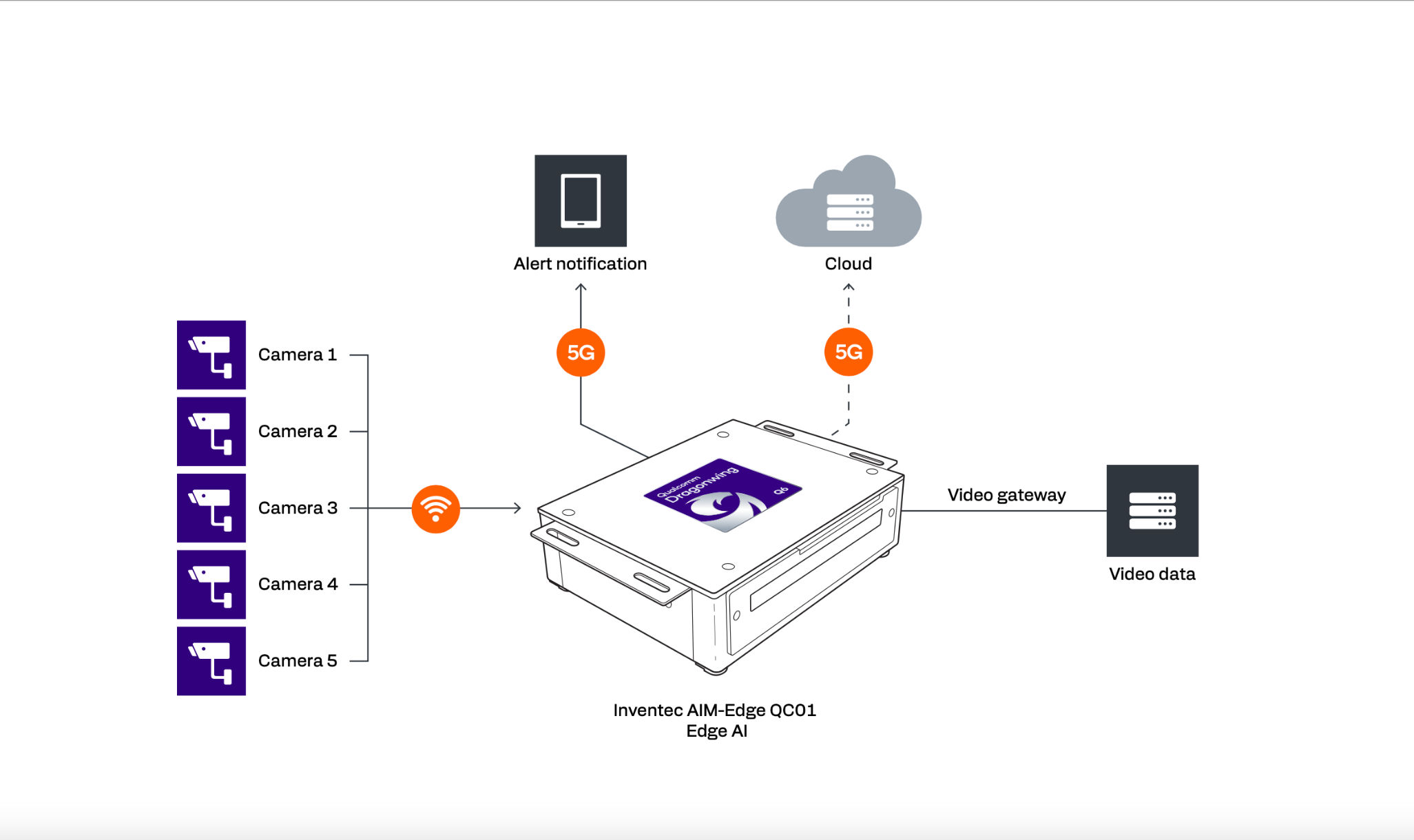
By running the grade crossing application on the Inventec AIM-Edge QC01 powered by the Dragonwing QCS6490, Capgemini has overcome the limitations of the hardware they used previously.
- Reduced dependence on the cloud – Besides performing inference and making decisions locally, the Dragonwing QCS6490 utilizes the Qualcomm® WCN6856 Wi-Fi companion system-on-chip to transmit alerts over Wi-Fi 6 and Wi-Fi 6E at up to 3.6 Gbps. Its on-board resources make for a solution that generates less network traffic to and from the cloud and depends less on the cloud for communication and storage. Capgemini estimates that performing the video analytics on the edge AI device reduces overall solution cost by 30 percent.
- Smaller memory footprint – For a single live video stream, the Dragonwing QCS6490 is able to perform inference at 18ms per frame while using 32.92 percent less memory than in the previous device.
- More camera inputs – Equipped with a triple image signal processor (ISP), the Dragonwing QCS6490 supports up to five concurrent cameras with video encode/decode at up to 4K30/4K60. That accommodates the full range of railway safety use cases.
- Processing on NPU – By running the model on the Hexagon NPU with 12 dense TOPS of AI performance, Capgemini realizes several benefits. CPU usage in the new solution is 5 percent lower. The compute-intensive workloads run on the NPU, freeing up capacity on the CPU and GPU for general functionality.
Plus, Capgemini reaps the ample benefit of long lifecycle support with the Dragonwing QCS6490. As enterprise-grade hardware, the processor comes with long-term support for upgrades to Android, Linux, Ubuntu and Windows 11 IoT Enterprise, including security updates.
Next steps
Once the Capgemini engineers refined their processes, subsequent integration projects were completed in just a few days. Pleased with the positive outcome of moving the grade crossing application, they applied their newfound knowledge to integrate other railway safety use cases, such as crowd monitoring, weapon detection, and violence detection. These additional models were developed within days.
Following the successful integration project, Capgemini anticipates that it will soon begin deploying the Inventec AIM-Edge QC01 in production environments with rail operators.
The lesson is that it is possible and profitable to integrate AI inference solutions with edge AI devices powered by Qualcomm Technologies’ industrial embedded IoT processors, in particular the Dragonwing QCS6490. Besides improvements in productivity, benefits include:
- Reduced dependence on the cloud
- Smaller memory footprint
- More camera inputs
- Processing on NPU
- Long lifecycle support
Qualcomm chipsets enable heterogeneous computing across CPU, GPU and NPU, and the Qualcomm® AI Runtime (QAIRT) compiler deploys neural network models flexibly and concurrently across those units. Unlike competing platforms that share compute and memory resources – limiting concurrency – the Qualcomm Hexagon NPU uses localized, tightly coupled memory, reducing memory bus load and enhancing performance.
For more information
AI solution architects and developers looking for inference on NPU with memory savings can find out more by contacting Qualcomm® IoT Sales and visiting Qualcomm® AI Hub
Contact Capgemini Engineering to learn more about their work on Rethinking Rail – The Digital Transformation in Railways – Capgemini
What else is trending for Internet of Things
- Read how CyberLink ports FaceMe to Qualcomm Hexagon NPU for facial recognition on edge devices
- Learn how to optimise your AI model for the Edge
- Browse highlights from Embedded World 2025
Watch developer Build Along sessions
- MCP IoT Agent for Snapdragon X Elite and Rubik Pi
- Using TensorFlow to accelerate models on Qualcomm IoT devices
- Docker and Qualcomm Dragonwing RB3 Gen 2 x FoundriesFactory
- AMA sessionw ith Qualcomm and Edge Impulse
- AprilTag and Qualcomm RB3 Gen 2
Vijay Anand
Senior Director and Chief IoT Architect, Qualcomm Technologies
Nadim Ferzli
Staff Manager, Qualcomm Technologies