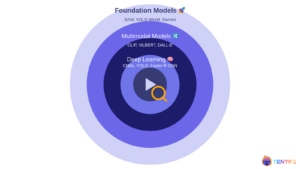
Scalable Video Search: Cascading Foundation Models
This article was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks. Video has become the lingua franca of the digital age, but its ubiquity presents a unique challenge: how do we efficiently extract meaningful information from this ocean of visual data? In Part 1 of this series, we navigate
Building a Simple VLM-based Multimodal Information Retrieval System with NVIDIA NIM
This article was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA. In today’s data-driven world, the ability to retrieve accurate information from even modest amounts of data is vital for developers seeking streamlined, effective solutions for quick deployments, prototyping, or experimentation. One of the key challenges in information retrieval

Vision Language Model Prompt Engineering Guide for Image and Video Understanding
This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA. Vision language models (VLMs) are evolving at a breakneck speed. In 2020, the first VLMs revolutionized the generative AI landscape by bringing visual understanding to large language models (LLMs) through the use of a vision encoder. These

SAM 2 + GPT-4o: Cascading Foundation Models via Visual Prompting (Part 2)
This article was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks. In Part 2 of our Segment Anything Model 2 (SAM 2) Series, we show how foundation models (e.g., GPT-4o, Claude Sonnet 3.5 and YOLO-World) can be used to generate visual inputs (e.g., bounding boxes) for SAM 2. Learn

SAM 2 + GPT-4o: Cascading Foundation Models via Visual Prompting (Part 1)
This article was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks. In Part 1 of this article we introduce Segment Anything Model 2 (SAM 2). Then, we walk you through how you can set it up and run inference on your own video clips. Learn more about visual prompting

AI Disruption is Driving Innovation in On-device Inference
This article was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm. How the proliferation and evolution of generative models will transform the AI landscape and unlock value. The introduction of DeepSeek R1, a cutting-edge reasoning AI model, has caused ripples throughout the tech industry. That’s because its performance is on

From Seeing to Understanding: LLMs Leveraging Computer Vision
This blog post was originally published at Tryolabs’ website. It is reprinted here with the permission of Tryolabs. From Face ID unlocking our phones to counting customers in stores, Computer Vision has already transformed how businesses operate. As Generative AI (GenAI) becomes more compelling and accessible, this tried-and-tested technology is entering a new era of
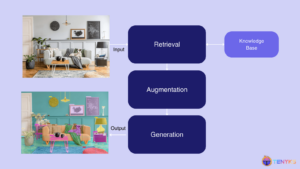
RAG for Vision: Building Multimodal Computer Vision Systems
This blog post was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks. This article explores the exciting world of Visual RAG, exploring its significance and how it’s revolutionizing traditional computer vision pipelines. From understanding the basics of RAG to its specific applications in visual tasks and surveillance, we’ll examine

The Future of AI in Business: Trends to Watch
This blog post was originally published at Digica’s website. It is reprinted here with the permission of Digica. In a world increasingly shaped by the rapid evolution of artificial intelligence, 2024 stands as another momentous year, with advancements that continue to reshape how we live, work, and imagine our future. From the rapid acceleration in
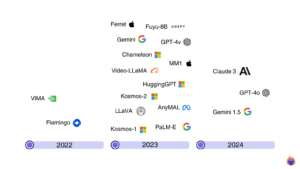
Multimodal Large Language Models: Transforming Computer Vision
This blog post was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks. This article introduces multimodal large language models (MLLMs) [1], their applications using challenging prompts, and the top models reshaping computer vision as we speak. What is a multimodal large language model (MLLM)? In layman terms, a multimodal

Harnessing the Power of LLM Models on Arm CPUs for Edge Devices
This blog post was originally published at Digica’s website. It is reprinted here with the permission of Digica. In recent years, the field of machine learning has witnessed significant advancements, particularly with the development of Large Language Models (LLMs) and image generation models. Traditionally, these models have relied on powerful cloud-based infrastructures to deliver impressive

AI On the Road: Why AI-powered Cars are the Future
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm. AI transforms your driving experience in unexpected ways as showcased by Qualcomm Technologies collaborations As automotive technology rapidly advances, consumers are looking for vehicles that deliver AI-enhanced experiences through conversational voice assistants and sophisticated user interfaces. Automotive

Edge Intelligence and Interoperability are the Key Components Driving the Next Chapter of the Smart Home
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm. The smart home industry is on the brink of a significant leap forward, fueled by generative AI and edge capabilities The smart home is evolving to include advanced capabilities, such as digital assistants that interact like friends

Accelerate Custom Video Foundation Model Pipelines with New NVIDIA NeMo Framework Capabilities
This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA. Generative AI has evolved from text-based models to multimodal models, with a recent expansion into video, opening up new potential uses across various industries. Video models can create new experiences for users or simulate scenarios for training

How AI On the Edge Fuels the 7 Biggest Consumer Tech Trends of 2025
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm. From more on-device AI features on your phone to the future of cars, 2025 is shaping up to be a big year Over the last two years, generative AI (GenAI) has shaken up, well, everything. Heading into

NVIDIA Expands Omniverse With Generative Physical AI
New Models, Including Cosmos World Foundation Models, and Omniverse Mega Factory and Robotic Digital Twin Blueprint Lay the Foundation for Industrial AI Leading Developers Accenture, Altair, Ansys, Cadence, Microsoft and Siemens Among First to Adopt Platform Libraries January 6, 2025 — CES — NVIDIA today announced generative AI models and blueprints that expand NVIDIA Omniverse™