by Jeff Bier
Founder and President, BDTI
September 29, 2011
This paper was originally published at the 2011 Embedded Systems Conference Boston.
Abstract—With the emergence of increasingly capable processors, it’s becoming practical to incorporate computer vision capabilities into a wide range of embedded systems, enabling them to analyze their environments via video inputs. Products like Microsoft’s Kinect game controller and Mobileye’s driver assistance systems are raising awareness of the incredible potential of embedded vision technology. As a result, many embedded system designers are beginning to think about implementing embedded vision capabilities. In this presentation, we’ll explore the potential of embedded vision and introduce some of the key ingredients for implementing it. After examining some example applications, we’ll introduce processors, algorithms, tools, and techniques for implementing embedded vision.
I. INTRODUCTION
We use the term “embedded vision” to refer to the use of computer vision technology in embedded systems. Stated another way, “embedded vision” refers to embedded systems that extract meaning from visual inputs. Similar to the way that wireless communication has become pervasive over the past 10 years, we believe that embedded vision technology will be very widely deployed in the next 10 years.
It’s clear that embedded vision technology can bring huge value to a vast range of applications. Two examples are Mobileye’s vision-based driver assistance systems, intended to help prevent motor vehicle accidents, and MG International’s swimming pool safety system, which helps prevent swimmers from drowning. And for sheer geek appeal, it’s hard to beat Intellectual Ventures’ laser mosquito zapper, designed to prevent people from contracting malaria.
Just as high-speed wireless connectivity began as an exotic, costly technology, embedded vision technology has so far typically been found in complex, expensive systems, such as a surgical robot for hair transplantation and quality control inspection systems for manufacturing.
Advances in digital integrated circuits were critical in enabling high-speed wireless technology to evolve from exotic to mainstream. When chips got fast enough, inexpensive enough, and energy efficient enough, high-speed wireless became a mass-market technology. Today one can buy a broadband wireless modem for under $100.
Similarly, advances in digital chips are now paving the way for the proliferation of embedded vision into high-volume applications. Like wireless communication, embedded vision requires lots of processing power—particularly as applications increasingly adopt high-resolution cameras and make use of multiple cameras. Providing that processing power at a cost low enough to enable mass adoption is a big challenge. This challenge is multiplied by the fact that embedded vision applications require a high degree of programmability. In contrast to wireless applications where standards mean that, for example, algorithms don’t vary dramatically from one cell phone handset to another, in embedded vision applications there are great opportunities to get better results—and enable valuable features—through unique algorithms.
With embedded vision, we believe that the industry is entering a “virtuous circle” of the sort that has characterized many other digital signal processing application domains. Although there are few chips dedicated to embedded vision applications today, these applications are increasingly adopting high-performance, cost-effective processing chips developed for other applications, including DSPs, CPUs, FPGAs, and GPUs. As these chips continue to deliver more programmable performance per dollar and per watt, they will enable the creation of more high-volume embedded vision products. Those high-volume applications, in turn, will attract more attention from silicon providers, who will deliver even better performance, efficiency, and programmability.
II. APPLICATIONS
Computer vision research has its origins in the 1960s. In more recent decades, embedded computer vision systems have been deployed in niche applications such as target-tracking for missiles, and automated inspection for manufacturing plants. Now, as lower-cost, lower-power, and higher-performance processors emerge, embedded vision is beginning to appear in high-volume applications. Perhaps the most visible of these is the Microsoft Kinect, a peripheral for the Xbox 360 game console that uses embedded vision to enable users to control video games simply by gesturing and moving their bodies. Another example of an emerging high-volume embedded vision application is automotive safety systems based on vision. A few automakers, such as Volvo, have begun to install vision-based safety systems in certain models. These systems perform a variety of functions, including warning the driver (and in some cases applying the brakes) when a forward collision is imminent, or when a pedestrian is in danger of being struck. A third example of an emerging high-volume embedded vision application is “smart” surveillance cameras, which are cameras with the ability to detect certain kinds of activity. For example, the Archerfish Solo, a consumer-oriented smart surveillance camera, can be programmed to detect people, vehicles, or other motion in user-selected regions of the camera’s field of view.
Enabled by the same kinds of chips and algorithms powering the above examples, we expect embedded vision functionality to proliferate into a wide range of products in the next few years. There are obvious places where vision can add tremendous value to equipment in consumer electronics, automotive, entertainment, medical, and retail applications, among others. In other cases, embedded vision will enable the creation of new types of equipment.
The purpose of this paper is to introduce some of the practical aspects of embedded vision technology—and to inspire system designers to imagine what can be done by incorporating vision capabilities into their designs.
III. ALGORITHMS
Algorithms are the essence of embedded vision. Through algorithms, visual input in the form of raw video or images is transformed into meaningful information that can be acted upon.
Computer vision has been the subject of vibrant academic research for decades, and that research has yielded a deep reservoir of algorithms. For many system designers seeking to implement vision capabilities, the challenge at the algorithm level will not be inventing new algorithms, but rather selecting the best existing algorithms for the task at hand, and refining or tuning them to the specific requirements and conditions of that task.
The algorithms that are applicable depend on the nature of the vision processing being performed. Vision applications are generally constructed from a pipelined sequence of algorithms, as shown in Figure 1. Typically, the initial stages are concerned with improving the quality of the image. For example, this may include correcting geometric distortion created by imperfect lenses, enhancing contrast, and stabilizing images to compensate for undesired movement of the camera.
Figure 1. A typical embedded vision algorithm pipeline.
The second set of stages in a typical embedded vision algorithm pipeline are concerned with converting raw images (i.e., collections of pixels) into information about objects. A wide variety of techniques can be used, identifying objects based on edges, motion, color, size, or other attributes.
The final set of stages in a typical embedded vision algorithm pipeline are concerned with making inferences about objects. For example, in an automotive safety application, these algorithms would attempt to distinguish between vehicles, pedestrians, road signs, and other features of the scene.
Generally speaking, vision algorithms are very computationally demanding, since they involve applying complex computations to large amounts of video or image data in real-time. There is typically a trade-off between the robustness of the algorithm and the amount of computation required.
A. Algorithm Example: Lens Distortion Correction
Lenses, especially inexpensive ones, tend to introduce geometric distortion into images. This distortion is typically characterized as “barrel” distortion or “pincushion” distortion, as illustrated in Figure 2.
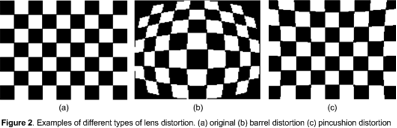
Figure 2. Typical lens distortion.
(based on “Lens Distortion Correction” by Shehrzad Qureshi; used with permission)
As shown in the figure, this kind of distortion causes lines that are in fact straight to appear curved, and vice-versa. This can thwart vision algorithms. Hence, it is common to apply an algorithm to reverse this distortion.
The usual technique is to use a known test pattern to characterize the distortion. From this characterization data, a set of image warping coefficients is generated, which is subsequently used to “undistort” each frame. In other words, the warping coefficients are computed once, and then applied to each frame. This is illustrated in Figure 3.
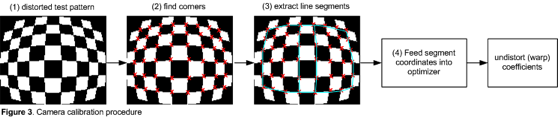
Figure 3. Lens distortion correction scheme.
One complication that arises with lens distortion correction is that the warping operation will use input data corresponding to pixel locations that do not precisely align with the actual pixel locations in the input frame. To enable this to work, interpolation is used between pixels in the input frame. The more demanding the algorithm, the more precise the interpolation must be—and the more computationally demanding.
For color imaging, the interpolation and warping operations must be performed separately on each color component. For example, a 720p video frame comprises 921,600 pixels, or approximately 2.8 million color components. At 60 frames per second, this corresponds to about 166 million color components per second. If the interpolation and warping operations require 10 processing operations per pixel, the distortion correction algorithm will consume 1.66 billion operations per second. (And that’s before we’ve even started trying to interpret the content of the images!)
B. Algorithm Example: Dense Optical Flow
“Optical flow” is a family of techniques used to estimate the pattern of apparent motion of objects, surfaces, and edges in a video sequence. In vision applications, optical flow is often used to estimate observer and object positions and motion in 3-d space, or to estimate image registration for super-resolution and noise reduction algorithms. Optical flow algorithms typically generate a motion vector for each pixel a video frame.
Optical flow requires making some assumptions about the video content (this is known as the “aperture problem”). Different algorithms make different assumptions. For example, some algorithms may assume that illumination is constant across the scene, or that motion is smooth.
Many optical flow algorithms exist. They can be roughly divided into the following classes:
- Block-based methods (similar to motion estimation in video compression codecs)
- Differential methods (Lucas-Kanade, Horn-Schunck, Buxton-Buxton, and variations)
- Other methods (discrete optimization, phase correlation)
A key challenge with optical flow algorithms is aliasing, which can cause incorrect results, for example when an object in the scene has a repeating texture pattern, or when motion exceeds algorithmic constraints. Some optical flow algorithms are sensitive to camera noise. Most optical flow algorithms are computationally intensive.
One popular approach is the Lucas-Kanade method with image pyramid. The Lucas-Kanade method is a differential method of estimating optical flow; it is simple but has significant limitations. For example, it assumes constant illumination and constant motion in a small neighborhood around the pixel position of interest. And, it is limited to very small velocity vectors (less than one pixel per frame).
Image pyramids are a technique to extend Lucas-Kanade to support faster motion. First, each original frame is sub-sampled to different degrees to create several pyramid levels. The Lucas-Kanade method is used at the top level (lowest resolution) yielding a coarse estimate, but supporting greater motion. Lucas-Kanade is then used again at lower levels (higher resolution) to refine the optical flow estimate. This is summarized in Figure 4.
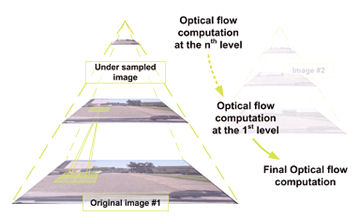
Figure 4. Lucas-Kanade optical flow algorithm with image pyramid. Used by permission of and © Julien Marzat.
C. Algorithm Example: Pedestrian Detection
“Pedestrian detection” here refers to detecting the presence of people standing or walking, as illustrated in Figure 5. Pedestrian detection might more aptly be called an “application” rather than an “algorithm.” It is a complex problem requiring sophisticated algorithms.

Figure 5. Prototype pedestrian detection application implemented on a CPU and an FPGA.
In Figure 6 we briefly summarize a prototype implementation of a stationary-camera pedestrian detection system implemented using a combination of a CPU and an FPGA.
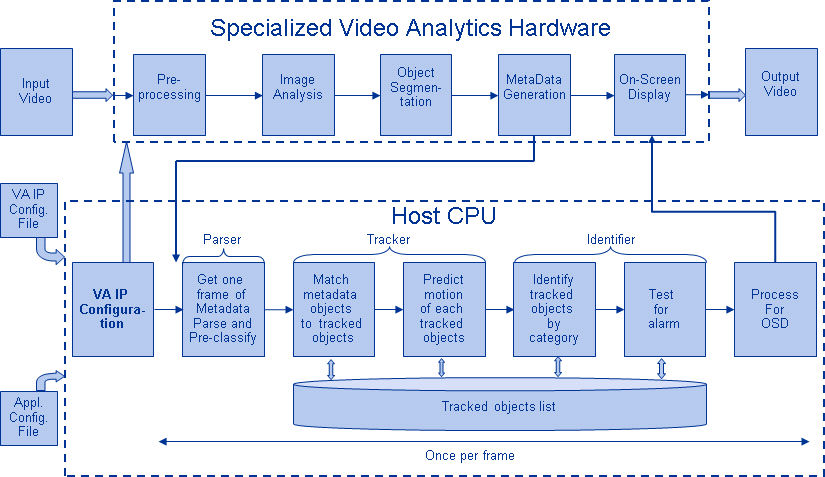
Figure 6: Block diagram of proof-of-concept pedestrian detection application using an FPGA and a CPU.
In the figure, the Pre-processing block comprises operations such as scaling and noise reduction, intended to improve the quality of the image. The Image Analysis block incorporates motion detection, pixel statistics such as averages, color information, edge information, etc. At this stage of processing, the image is divided into small blocks. The object segmentation step groups blocks having similar statistics and thus creates an object. The statistics used for this purpose are based on user defined features specified in the hardware configuration file.
The Identification and Meta Data generation block generates analysis results from the identified objects such as location, size, color information, and statistical information. It puts the analysis results into a structured data format and transmits them to the CPU.
Finally, the On-screen Display block receives command information from the host and superimposes graphics on the video image for display.
This prototype system, operating on 720p resolution video at 60 frames per second, was implemented by BDTI on a combination of a Xilinx Spartan-3A DSP 3400 FPGA and a Texas Instruments OMAP3430 CPU. The total compute load is on the order of hundreds of billions of operations per second.
IV. PROCESSORS
As we’ve mentioned, vision algorithms typically require high compute performance. And, of course, embedded systems of all kinds are usually required to fit into tight cost and power consumption envelopes. In other digital-signal-processing application domains, such as digital wireless communications, chip designers achieve this challenging combination of high performance, low cost, and low power by using specialized coprocessors and accelerators to implement the most demanding processing tasks in the application. These coprocessors and accelerators are typically not programmable by the chip user, however. This trade-off is often acceptable in wireless applications, where standards mean that there is strong commonality among algorithms used by different equipment designers.
In vision applications, however, there are no standards constraining the choice of algorithms. On the contrary, there are often many approaches to choose from to solve a particular vision problem. Therefore, vision algorithms are very diverse, and tend to change fairly rapidly over time. As a result, the use of non-programmable accelerators and coprocessors is less attractive for vision applications compared to applications like digital wireless and compression-centric consumer video equipment.
Achieving the combination of high performance, low cost, low power, and programmability is challenging. Special-purpose hardware typically achieves high performance at low cost, but with little programmability. General-purpose CPUs provide programmability, but with weak performance or poor cost-, energy-efficiency.
Demanding embedded vision applications most often use a combination of processing elements, which might include, for example:
- A general-purpose CPU for heuristics, complex decision-making, network access, user interface, storage management, and overall control
- A high-performance DSP-oriented processor for real-time, moderate-rate processing with moderately complex algorithms
- One or more highly parallel engines for pixel-rate processing with simple algorithms
While any processor can in theory be used for embedded vision, the most promising types today are:
- High-performance embedded CPU
- Application-specific standard product (ASSP) in combination with a CPU
- Graphics processing unit (GPU) with a CPU
- DSP processor with accelerator(s) and a CPU
- Mobile “application processor”
- Field programmable gate array (FPGA) with a CPU
In this section, we’ll briefly introduce each of these processor types and some of their key strengths and weaknesses for embedded vision applications.
A. High-performance Embedded CPU
In many cases, embedded CPUs cannot provide enough performance—or cannot do so at acceptable price or power consumption levels—to implement demanding vision algorithms. Often, memory bandwidth is a key performance bottleneck, since vision algorithms typically use large amounts of memory bandwidth, and don’t tend to repeatedly access the same data. The memory systems of embedded CPUs are not designed for these kinds of data flows. However, like most types of processors, embedded CPUs become more powerful over time, and in some cases can provide adequate performance.
And there are some compelling reasons to run vision algorithms on a CPU when possible. First, most embedded systems need a CPU for a variety of functions. If the required vision functionality can be implemented using that CPU, then the complexity of the system is reduced relative to a multiprocessor solution.
In addition, most vision algorithms are initially developed on PCs using general-purpose CPUs and their associated software development tools. Similarities between PC CPUs and embedded CPUs (and their associated tools) mean that it is typically easier to create embedded implementations of vision algorithms on embedded CPUs compared to other kinds of embedded vision processors.
In addition embedded CPUs typically are the easiest to use compared to other kinds of embedded vision processors, due to their relatively straightforward architectures, sophisticated tools, and other application development infrastructure, such as operating systems.
An example of an embedded CPU is the Intel Atom E660T.
B. Application-specific standard product (ASSP) in combination with a CPU
Application-specific standard products (ASSPs) are specialized, highly integrated chips tailored for specific applications or application sets. ASSPs may incorporate a CPU, or use a separate CPU chip.
By virtue of specialization, ASSPs typically deliver superior cost- and energy-efficiency compared with other types of processing solutions. Among other techniques, ASSPs deliver this efficiency through the use of specialized coprocessors and accelerators. And, because ASSPs are by definition focused on a specific application, they are usually provided with extensive application software.
The specialization that enables ASSPs to achieve strong efficiency, however, also leads to their key limitation: lack of flexibility. An ASSP designed for one application is typically not suitable for another application, even one that is related to the target application. ASSPs use unique architectures, and this can make programming them more difficult than with other kinds of processors. Indeed, some ASSPs are not user-programmable.
Another consideration is risk. ASSPs often are delivered by small suppliers, and this may increase the risk that there will be difficulty in supplying the chip, or in delivering successor products that enable system designers to upgrade their designs without having to start from scratch.
An example of a vision-oriented ASSP is the PrimeSense PS1080-A2, used in the Microsoft Kinect.
C. Graphics processing unit (GPU) with a CPU
Graphics processing units (GPUs), intended mainly for 3-d graphics, are increasingly capable of being used for other functions, including vision applications. The GPUs used in personal computers today are explicitly intended to be programmable to perform functions other than 3-d graphics. Such GPUs are termed “general-purpose GPUs” or “GPGPUs.”
GPUs have massive parallel processing horsepower. They are ubiquitous in personal computers. GPU software development tools are readily and freely available, and getting started with GPGPU programming is not terribly complex. For these reasons, GPUs are often the parallel processing engines of first resort of computer vision algorithm developers who develop their algorithms on PCs, and then may need to accelerate execution of their algorithms for simulation or prototyping purposes.
GPUs are tightly integrated with general-purpose CPUs, sometimes on the same chip. However, one of the limitations of GPU chips is the limited variety of CPUs with which they are currently integrated, and the limited number of CPU operating systems that support that integration.
Today there are low-cost, low-power GPUs, designed for products like smart phones, tablets. However, these GPUs are generally not GPGPUs, and therefore using them for applications other than 3-d graphics is very challenging.
An example of a GPGPU used in personal computers is the NVIDIA GT240.
D. DSP processor with accelerator(s) and a CPU
Digital signal processors (“DSP processors” or “DSPs”) are microprocessors specialized for signal processing algorithms and applications. This specialization typically makes DSPs more efficient than general-purpose CPUs for the kinds of signal processing tasks that are at the heart of vision applications. In addition, DSPs are relatively mature and easy to use compared to other kinds of parallel processors.
Unfortunately, while DSPs do deliver higher performance and efficiency than general-purpose CPUs on vision algorithms, they often fail to deliver sufficient performance for demanding algorithms. For this reason, DSPs are often supplemented with one or more coprocessors. A typical DSP chip for vision applications therefore comprises a CPU, a DSP, and multiple coprocessors. This heterogeneous combination can yield excellent performance and efficiency, but can also be difficult to program. Indeed, DSP vendors typically do not enable users to program the coprocessors; rather, the coprocessors run software function libraries developed by the chip supplier.
An example of a DSP targeting video applications is the Texas Instruments DM8168
E. Mobile “application processor”
A mobile “application processor” is a highly integrated system-on-chip, typically designed primarily for smart phones but used for other applications. Application processors typically comprise a high-performance CPU core and a constellation of specialized co-processors, which may include a DSP, a GPU, a video processing unit (VPU), a 2-d graphics processor, an image acquisition processor, etc.
These chips are specifically designed for battery powered applications, and therefore place a premium on energy efficiency. In addition, because of the growing importance of and activity surrounding smartphone and tablet applications, mobile application processors often have strong software development infrastructure, including low-cost development boards, Linux and Android ports, etc.
However, as with the DSP processors discussed in the previous section, the specialized co-processors found in application processors are usually not user-programmable, which limits their utility for vision applications.
An example of a mobile application processor is the Freescale i.MX53.
F. Field programmable gate array (FPGA) with a CPU
Field programmable gate arrays (“FPGAs”) are flexible logic chips that can be reconfigured at the gate and block levels. This flexibility enables the user to craft computation structures that are tailored to the application at hand. It also allows selection of I/O interfaces and on-chip peripherals matched to the application requirements. The ability to customize compute structures, coupled with the massive amount of resources available in modern FPGAs, yields high performance coupled with good cost- and energy-efficiency.
However, using FGPAs is essentially a hardware design function, rather than a software development activity. FPGA design is typically performed using hardware description languages (Verilog or VHLD) at the register transfer level (RTL)—a very low level of abstraction. This makes FPGA design time-consuming and expensive, compared to using the other types of processors discussed here.
However using FPGAs is getting easier, due to several factors. First, so called “IP block” libraries—libraries of reusable FPGA design components—are becoming increasingly capable. In some cases, these libraries directly address vision algorithms. In other cases, they enable supporting functionality, such as video I/O ports or line buffers. Second, FGPA suppliers and their partners increasingly offer reference designs—reusable system designs incorporating FPGAs and targeting specific applications. Third, high-level synthesis tools, which enable designers to implement vision and other algorithms in FPGAs using high-level languages, are increasingly effective.
Relatively low-performance CPUs can be implemented by users in the FPGA. In a few cases, high-performance CPUs are integrated into FPGAs by the manufacturer.
An example FPGA that can be used for vision applications is the Xilinx Spartan-6 LX150T.
V. DEVELOPMENT AND TOOLS
Developing embedded vision systems is challenging. One consideration, already mentioned above, is that vision algorithms tend to be very computationally demanding. Squeezing them into low-cost, low-power processors typically requires significant optimization work, which in turn requires a deep understanding of the target processor architecture.
Another key consideration is that vision is a system-level problem. That is, success depends on numerous elements working together, besides the vision algorithms themselves. These include lighting, optics, image sensors, image pre-processing, and image storage sub-systems. Getting these diverse elements working together effectively and efficiently requires multi-disciplinary expertise.
There are numerous algorithms available for vision functions, so in many cases it is not necessary to develop algorithms from scratch. But picking the best algorithm for the job, and ensuring that it meets application requirements, can be a large project in itself.
Today, there are many computer vision experts who know little about embedded systems, and many embedded system designers who know little about computer vision. Many projects die in the chasm between these groups. To help bridge this gap, BDTI recently founded the Embedded Vision Alliance [1], an industry partnership dedicated to providing SoC and embedded system engineers with practical know-how they need to incorporate vision capabilities into their designs. The Alliance’s web site, www.Embedded-Vision.com, is growing rapidly with video seminars, technical articles, coverage of industry news, and discussion forums. For example, the site offers a free set of basic computer vision demonstration programs that can be downloaded and run on any Windows computer. [2]
A. Personal Computers
The personal computer is both a blessing and a curse for embedded vision development. Most embedded vision systems—and virtually all vision algorithms—are initially developed on a personal computer. The PC is a fabulous platform for research and prototyping. It is inexpensive, ubiquitous, and easy to integrate with cameras and displays. In addition, PCs are endowed with extensive application development infrastructure, including basic software development tools, vision-specific software component libraries, domain-specific tools (such as MATLAB), and example applications. In addition, the GPUs found in most PCs can be used to provide parallel processing acceleration for PC-based application prototypes or simulations.
However, the PC is not an ideal platform for implementing most embedded vision systems. Although some applications can be implemented on an embedded PC (a more compact, lower-power cousin to the standard PC), many cannot, due to cost, size, and power considerations. In addition, PCs lack sufficient performance for many real-time vision applications.
And, unfortunately, many of the same tools and libraries that make it easy to develop vision algorithms and applications on the PC also make it difficult to create efficient embedded implementations. For example vision libraries intended for algorithm development and prototyping often do not lend themselves to efficient embedded implementation.
B. OpenCV
OpenCV is a free, open source computer vision software component library for personal computers, comprising over two thousand algorithms. [3] Originally developed by Intel, now maintained by Willow Garage. The OpenCV library, used along with Bradski and Kahler’s book, is a great way to quickly begin experimenting with computer vision.
However, OpenCV is not a solution to all vision problems. Some OpenCV functions work better than others. And OpenCV is a library, not a standard, so there is no guarantee that it functions identically on different platforms. In its current form, OpenCV is not particularly well suited to embedded implementation. Ports of OpenCV to non-PC platforms have been made, and more are underway, but there’s currently little coherence to these efforts.
C. Some Promising Developments
While embedded vision development is challenging, some promising recent industry developments suggest that it is getting easier. For example, the Microsoft Kinect is becoming very popular for vision development. Soon after its release in late 2010, the API for the Kinect was reverse-engineered, enabling engineers to use the Kinect with hosts other than the Xbox 360 game console. The Kinect has been used with PCs and with embedded platforms such as the Beagle Board.
The XIMEA Currera integrates an embedded PC in a camera. It’s not suitable for low-cost, low-power applications, but can be a good fit for low-volume applications like manufacturing inspection.
Several embedded processor vendors have begun to recognize the magnitude of the opportunity for embedded vision, and are developing processors specifically targeted embedded vision applications. In addition, smart phones and tablets have the potential to become effective embedded vision platforms. Application software platforms are emerging for certain EV applications, such as augmented reality and gesture-based UIs. Such software platforms simplify embedded vision application development by providing many of the utility functions commonly required by such applications.
VI. CONCLUSIONS
With embedded vision, we believe that the industry is entering a “virtuous circle” of the sort that has characterized many other digital signal processing application domains. Although there are few chips dedicated to embedded vision applications today, these applications are increasingly adopting high-performance, cost-effective processing chips developed for other applications, including DSPs, CPUs, FPGAs, and GPUs. As these chips continue to deliver more programmable performance per dollar and per watt, they will enable the creation of more high-volume embedded vision products. Those high-volume applications, in turn, will attract more attention from silicon providers, who will deliver even better performance, efficiency, and programmability.
ACKNOWLEDGMENTS
The author gratefully acknowledges the assistance of Shehrzad Qureshi in providing information on lens distortion correction used in this paper.
REFERENCES
[1] www.Embedded-Vision.com
[2] https://www.embedded-vision.com/industry-analysis/video-interviews-demos/2011/09/09/introduction-computer-vision-using-opencv
[3] OpenCV: http://opencv.willowgarage.com/wiki/ Bradski and Kaehler, “Learning OpenCV: Computer Vision with the OpenCV Library”, O’Reilly, 2008
[4] MATLAB/Octave: “Machine Vision Toolbox”, P.I. Corke, IEEE Robotics and Automation Magazine, 12(4), pp 16-25, November 2005. http://petercorke.com/Machine_Vision_Toolbox.html P. D. Kovesi. “MATLAB and Octave Functions for Computer Vision and Image Processing.” Centre for Exploration Targeting, School of Earth and Environment, The University of Western Australia. http://www.csse.uwa.edu.au/~pk/research/matlabfns.
[5] Visym (beta): http://beta.visym.com/overview
[6] “Predator” self-learning object tracking algorithm: Z. Kalal, K. Mikolajczyk, and J. Matas, “Forward-Backward Error: Automatic Detection of Tracking Failures,” International Conference on Pattern Recognition, 2010, pp. 23-26.
http://info.ee.surrey.ac.uk/Personal/Z.Kalal/
[7] Vision on GPUs: GPU4vision project, TU Graz:
http://gpu4vision.icg.tugraz.at
[8] Lens distortion correction: Luis Alvarez, Luis Gomez and J. Rafael Sendra. “Algebraic Lens Distortion Model Estimation.” Image Processing On Line, 2010. DOI:10.5201/ipol.2010.ags-alde: http://www.ipol.im/pub/algo/ags_algebraic_lens_distortion_estimation