This article was originally published at John Day's Automotive Electronics News. It is reprinted here with the permission of JHDay Communications.
Cameras located in a vehicle's interior, coupled with cost-effective and power-efficient processors, can deliver abundant benefits to drivers and passengers alike.
By Brian Dipert
Editor-in-Chief
Embedded Vision Alliance
Tom Wilson
Vice President, Business Development
CogniVue
Tim Droz
Vice President and General Manager
SoftKinetic North America
Ian Riches
Director, Global Automotive Practice
Strategy Analytics
Gaurav Agarwal
Automotive ADAS Marketing and Business Development Manager
Texas Instruments
and Marco Jacobs
Vice President, Marketing
videantis
The ADAS (advanced driver assistance systems) market is one of the brightest stars in today's technology sector, with adoption rapidly expanding beyond high-end vehicles into high-volume mainstream implementations. It's also one of the fastest-growing application areas for automotive electronics. Market analysis firm Strategy Analytics, for example, expects that by 2021, automotive OEMs will be spending in excess of $25B USD per year on a diversity of assistance and safety solutions (Figure 1). The integration of image capture and vision processing capabilities is a critical element of ADAS designs, enabling them to offer additional and enhanced features beyond those provided by radar, LiDAR, infrared, ultrasound, and other sensing technologies.
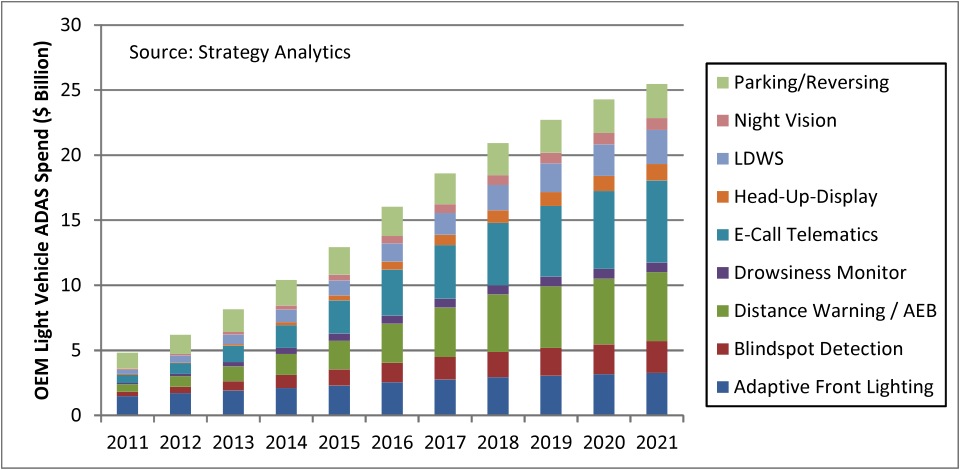
Figure 1. The Advanced Driver Assistance Systems (ADAS) market is expected to grow rapidly in the coming years, and in a diversity of implementation forms.
One area of ADAS that is seeing a particularly significant increase in interest from OEMs is the use of in-cockpit cameras to monitor the driver and passengers. Strategy Analytics sees the potential for over 5 million cameras to be used in such applications per year by 2021, with further growth accelerating beyond that as autonomous technologies become more widely applied. Strategy Analytics has identified two main factors behind this trend:
- As mainstream ADAS technologies increasingly appear in mass-market vehicles, the pressure is on to develop ever-improved solutions for premium brands and models. By monitoring the driver, for example, automated interventions can be specifically tailored to the driver’s attentiveness. This response customization both reduces the likelihood of false warnings when the driver is engaged, and improves responses when the driver is distracted.
- There is large and growing industry interest in the migration of ADAS technologies into increasingly autonomous vehicles. One of the key challenges here is managing the hand-over between autonomous and driver-controlled states. Without accurate information as to how engaged the driver is at any particular point in time, a smooth handover is almost impossible to implement.
Image perception, understanding and decision-making processes have historically been achievable only using large, heavy, expensive, and power-draining computers, restricting computer vision's usage to a few niche applications like factory automation. Beyond these few success stories, computer vision has mainly been a field of academic research over the past several decades. However, with the emergence of increasingly capable processors, image sensors, memories, and other semiconductor devices, along with robust algorithms, it's becoming practical to incorporate practical computer vision capabilities into a wide range of systems, including ADAS designs.
A previous article in this series provided an overview of vision processing in ADAS. This article focuses in more detail on in-cockpit ADAS applications, discussing implementation details and the tradeoffs of various approaches. And it introduces an industry alliance created to help product creators incorporate vision capabilities into their ADAS designs, and provides links to the technical resources that this alliance provides.
Driver Monitoring
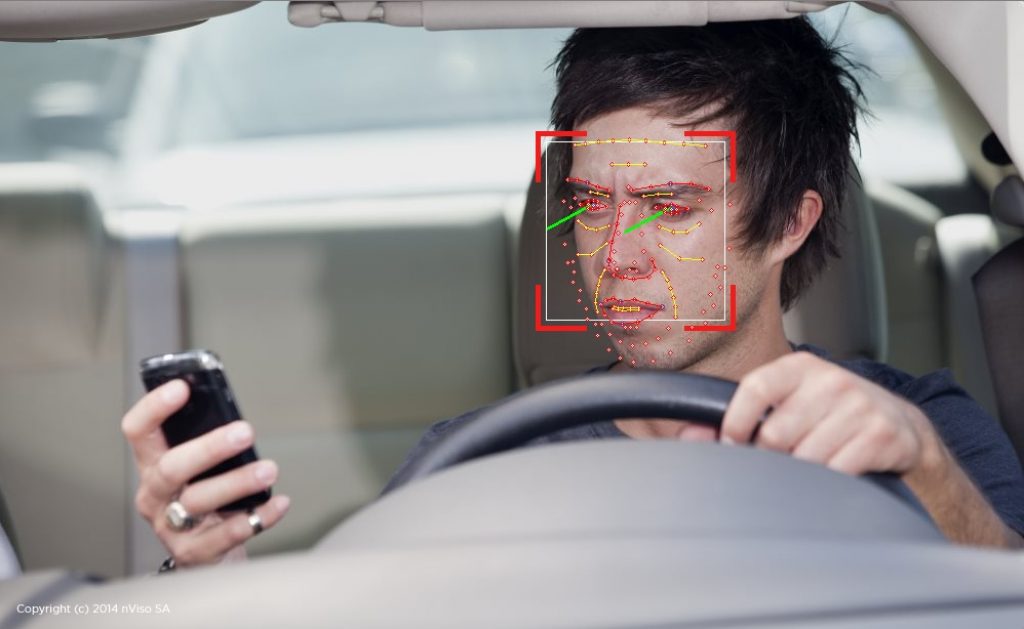
Distracted and drowsy driving is a leading cause of car accidents. According to an American Automobile Association (AAA) study in 2010 (PDF), more than one out of every six accidents can be attributed to distracted and drowsy driving. Today’s in-cockpit ADAS technology can help determine if the driver is distracted or drowsy, and then alert the driver to bring his or her attention back to the driving task at hand. Additionally, by using information about the driver's head and body position provided by this same system, appropriate deployment of the airbag (intensity, location, etc.) can be implemented in crash situations (Figure 2).
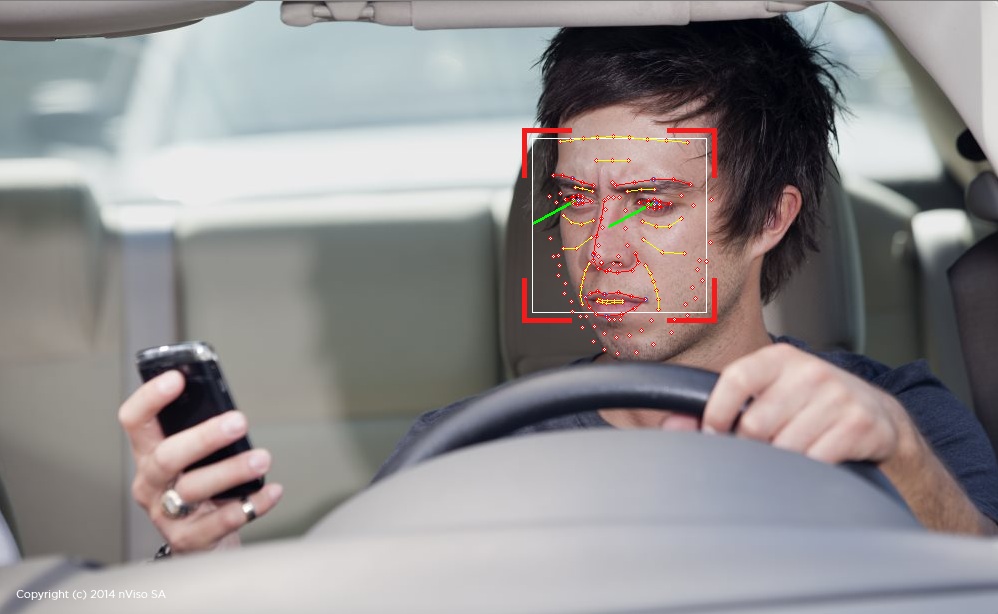
Figure 2. Camera-based gaze tracking is useful in determining when a driver is distracted or drowsy; these same cameras and connected processors can also implement other facial analysis functions, along with gesture interfaces and other features (courtesy nViso).
A variety of vision technologies are being employed to detect distracted and drowsy driving, as well as to discern driver position. Some systems use several conventional 2D cameras located at different position in the dashboard; others use a single 3D (i.e. depth-discerning) camera, or a combination of these approaches. The cameras capture scene information, which is then processed by the engine control unit (ECU) or other computing resources in the vehicle in order to implement driver gaze tracking (a means of assessing degree of attention on the road ahead) as well as provide feedback on head and body position, blink frequency and duration, and intensity of redness in the eyes. These data points are then combined to determine if the driver is distracted or drowsy, with an alert then delivered to the driver if necessary (audible beep, vibration of the steering wheel and/or seat, etc.).
Several challenges exist to implementing vision-based driver monitoring technology. Difficult lighting conditions and occlusion (i.e. intermediary objects that prevent a clear view of the driver) can preclude obtaining robust information, for example, resulting in incorrect conclusions. The resulting false alarms aren't life threatening, but they might still be highly annoying, thereby unfortunately compelling the driver to disable the ADAS features. The combination of 2D and 3D image sensors, for example, along with more robust processing of the images coming from the sensors, can overcome most if not all of these issues.
Facial Analysis
If one or multiple cameras are already pointed at the driver for distraction and drowsiness detection purposes, why not also employ them for other uses? One of the most familiar vision processing applications is face recognition, which continues to be a very active area of computer vision research. While you may associate face recognition with security and biometrics applications, the technology is spreading to a broad range of applications. Face recognition is now found in televisions and game consoles, for example, where a user is identified and his or her specific profile is presented via an automated login feature. This profile may include favorite channels and shows, social media service usernames and passwords, online content provider login credentials, custom wallpaper settings, etc.
Face recognition will likely also become an option in automobiles in the near future. As with the smart TV and game console examples, face recognition can be used as a "user login" driver convenience feature. In the case of the automobile, face recognition would enable the automated selection of a wide range of driver-customized options. These might include obvious settings such as seat, mirror, and steering wheel position, as well as other, less obvious settings like media favorites (Sirius or standard radio, CD player, etc), navigation settings, cluster settings (newer cars will provide the ability to select the cluster color and design), and settings for various ADAS features (e.g. preferred following distance).
As cars continue to evolve into personalized consumer electronic devices with a wide range of configurations, the ability of a simple face-recognition login to invoke a large number of user settings will become a great convenience. And beyond providing driver convenience for configuration settings, face recognition for driver identification will become important in order to determine specific privileges. For example, it can be used to identify drivers with previous offenses for driving under the influence (DUI) or other charges. Alternatively, recognizing the teen with a new license in the family might invoke certain restrictions, such as a requirement for an adult of the family to also be in the passenger seat (see "Passenger Implementations").
Regardless of the application, face recognition presents several challenges to ensure high reliability. Occlusion is once again often an issue; hats and glasses, for example, can be problematic. Lighting can also be a problem, since at night the interior of the vehicle may only receive a small amount of ambient lighting from the instrument cluster. For this reason, in-vehicle face recognition implementations will likely use near infrared (NIR) lighting. NIR is not detectable by humans and therefore poses no risk of driver distraction. NIR also utilizes the unique reflectance characteristics of human skin to simplify face detection. Some of the limitations of 2D vision processing can also be circumvented with 3D sensing. Time-of-flight sensors, for example, may be a good option for in-vehicle face recognition and also open new possibilities for gesture control, described in the next section of this article.
Other facial analysis techniques are more likely to be implemented in the near term, as full-blown face recognition continues to evolve toward higher accuracy. It might be simpler to discern, for example, that the person currently sitting in the driver seat is not an already approved driver, thereby enabling ignition lockout. Being able to accurately discern the age range, gender and other general attributes of a vehicle driver or passenger, even in the absence of precise individual identification, is still sufficient for many purposes. And facial analysis is also today already capable of discerning a driver's emotional state with a high degree of reliability. "Road rage" prevention features are one obvious application (of many); researchers at Switzerland's École Polytechnique Fédérale de Lausanne have partnered with PSA Peugeot Citroën and prototyped just such a dashboard-mounted camera.
Gesture Interfaces
Speaking of driver distractions, advanced in-vehicle infotainment systems and system control clusters are becoming ever richer, offering an expanded range of functions. Customized climate control, personalized music and navigation systems, and connections to cell phones already have sophisticated user interfaces which require some degree of driver intervention. And next-generation cars will have digital cockpits and heads-up displays (HUDs) that also will be configurable to a particular user's preference. Driver temptations to use these features while the vehicle is in motion will inevitably lead to distraction and, eventually, accidents.
Gesture-based interfaces may be the solution to this problem. Gesture recognition is already available in TVs, mobile electronics devices, lighting systems and numerous other applications. Gesture systems can be based on a variety of different camera technologies, each with associated strengths and shortcomings, ranging from a single 2D camera to 3D sensors such as stereo, structured light, or time-of-flight, or a combination of 2D and 3D approaches.
Gesture interface technology admittedly comes with several challenges. False-positive detection of hand waves or poses can result in unintended setting changes, for example. Also, the driver has to learn a new gesture “language”, a language that is currently not standardized and can therefore vary based on vehicle manufacturer, model and geography. Rapid gesture detection and decode is also a requirement, so that the driver doesn’t become distracted by the attempt to have a gesture correctly recognized. Despite these challenges, gesture-based interface are becoming increasingly popular (and robust) in a variety of applications, and their sooner-or-later presence in vehicles as an easy-to-use interface for reducing driver distraction is therefore also likely.
Passenger Implementations
The in-cockpit vision processing applications discussed in this article have so far been focused on the driver. However, many of them are equally applicable to other vehicle occupants. Vision-based airbag deployment control, for example, is one key opportunity for improved passenger sensing. Occupant detection for airbag deployment is currently implemented via in-seat pressure sensors or e-field sensors. Both technologies have limitations, however, particularly regarding being able to accurately determine passenger position. In contrast, a 3D image sensor can accurately determine the passenger’s head and torso position and can adjust front and side airbag deployment appropriately. In addition, the deployment can be adjusted based on the height and size of the passenger.
Occupancy tracking is also important for the back seat; feedback could be provided to the driver, for example, if passengers are not in their correct positions (supplementing already-mainstream seatbelt usage sensors). This is perhaps obviously very useful information to parents of small children, as is the related no-leave-behind reminder that sleeping, silent kids are still inside when the vehicle is parked and exited. And speaking of children, gesture-based interfaces are of intuitive use for all vehicle occupants, not just the driver. Passengers would also likely like to have gesture control of the infotainment system, for example; access privileges might be controlled through face recognition. A child in the front passenger seat might have limited gesture control for volume and media selection, but no access to navigation settings. And children in the back seat who are too small to reach touchscreen controls would alternatively have access to gesture-based control for their seatback-installed media.
As the amount of vision processing multiplies through the car, it may quickly become unmanageable to burden the infotainment processor with all of the possible vision processing tasks, especially if one designs for a worst case scenario where all vision processing is happening at once. In addition, if all of the embedded vision processing were to be performed in the infotainment ECU, raw video data might need to be sent to the ECU, likely in an encoded format (see sidebar "Ethernet AVB Reduces Cable Costs"). The amount of video decoding alone becomes substantial, not to mention the vision processing of that video.
A distributed system of small smart low power cameras is a scalable alternative approach; each camera can perform the necessary vision processing and only send generated metadata over a low bandwidth link to the infotainment ECU. Performance-per-watt will be a critical parameter in these smart peripheral cameras; a new generation of application processors containing dedicated vision processing cores is one means (of several) of addressing such concerns. The website of the Embedded Vision Alliance contains an abundance of technical resources on processor options, as well as sensors, software, and other aspects of vision-enabled system designs
The same centralized-vs-distributed processing tradeoffs hold true for vehicle-exterior ADAS cameras (to be discussed in greater detail in a future article in this series), some of which may use stereo vision for depth perception purposes. Performing the vision processing "heavy lifting" at the camera for functions such as stereo matching or optical flow, with only metadata and compressed video being subsequently sent to the ECU, is once again an implementation alternative.
Empowering Product Creators to Develop "Machines That See"
The opportunity for vision technology to expand the capabilities of automotive safety systems is part of a much larger trend. Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. The Embedded Vision Alliance uses the term “embedded vision” to refer to this growing use of practical computer vision technology in embedded systems, mobile devices, special-purpose PCs, and the cloud, with ADAS being one very exciting application.
Vision processing can add valuable capabilities to existing products. And it can provide significant new markets for hardware, software and semiconductor suppliers. The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform this potential into reality. CogniVue, SoftKinetic, Texas Instruments and videantis, the co-authors of this article, are members of the Embedded Vision Alliance.
First and foremost, the Alliance's mission is to provide product creators with practical education, information, and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Alliance’s twice-monthly email newsletter, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCV. Access is free to all through a simple registration process.
The Alliance also holds Embedded Vision Summit conferences in Silicon Valley. Embedded Vision Summits are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Alliance member companies. These events are intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May, 2014, and a comprehensive archive of keynote, technical tutorial and product demonstration videos, along with presentation slide sets, is available on the Alliance website. The next Embedded Vision Summit will take place on May 12, 2015 in Santa Clara, California; please reserve a spot on your calendar and plan to attend.
Sidebar: Ethernet AVB Reduces Cable Costs
There’s a clear trend towards more cameras to the car, enabling a safer and more comfortable ride for driver and passengers alike. These inward- and outward-looking cameras carry significant cost , however. And it’s not only the camera that adds cost, but also the cabling that transmits the video data from the camera module to the dashboard. Shipping uncompressed digital video from the camera to the central processing unit, for example, requires expensive point-to-point low voltage differential signaling (LVDS) cabling.
An emerging alternative involves compressing the video inside the camera module, allowing distribution of the resulting bitstream over lower-bandwidth, Ethernet-based twisted-pair wiring. This wiring is much less expensive than shielded LVDS cabling. The Ethernet Audio Video Bridging (AVB) standard provides the capability to flexibly route multimedia and other data throughout the car, also comprehending QoS (quality-of-service) and real-time processing-and-response requirements. Control data networks such as CAN and Flexray can also be consolidated into the Ethernet network, further reducing cabling cost. BMW was first to market with this concept, introducing Ethernet on the X5 SUV in the fall of 2013. Other vehicle manufacturers are sure to follow in BMW's footsteps.
First-generation Ethernet-based systems now on the market use motion JPEG compression, resulting in artifacts and high-bitrate streams. The alternative H.264 coding standard, specifically its High Intra profile option, compresses much more efficiently than JPEG and adds support for 10 or 12 bit samples, resulting in higher quality images. Highest-possible picture quality is especially important for computer vision algorithms, which can be negatively impacted by coding artifacts.
Another important design constraint is the latency that the transmission of video introduces. This delay needs to be carefully managed; codecs, for example, need to be optimized for low-latency transmission. Additional delay reduces the responsiveness of the driver assistance safety systems, where speed is of the essence. Ethernet AVB's high bandwidth and low protocol complexity are also helpful in this regard. For these and other reasons, Ethernet AVB has the potential to greatly simplify and reduce the cost of data distribution in the car. It’s well positioned to become the de factor standard in automotive.
Brian Dipert is Editor-In-Chief of the Embedded Vision Alliance. He is also a Senior Analyst at BDTI (Berkeley Design Technology, Inc.), which provides analysis, advice, and engineering for embedded processing technology and applications, and Editor-In-Chief of InsideDSP, the company's online newsletter dedicated to digital signal processing technology. Brian has a B.S. degree in Electrical Engineering from Purdue University in West Lafayette, IN. His professional career began at Magnavox Electronics Systems in Fort Wayne, IN; Brian subsequently spent eight years at Intel Corporation in Folsom, CA. He then spent 14 years at EDN Magazine.
Tom Wilson is Vice President of Business Development at CogniVue Corporation, with more than 20 years of experience in various applications such as consumer, automotive, and telecommunications. He has held leadership roles in engineering, sales and product management, and has a Bachelor’s of Science and PhD in Science from Carleton University, Ottawa, Canada.
Tim Droz is Senior Vice President and General Manager of SoftKinetic North America, delivering 3D time-of-flight (TOF) image sensors, 3D cameras, and gesture recognition and other depth-based software solutions. Prior to SoftKinetic, he was Vice President of Platform Engineering and head of the Entertainment Solutions Business Unit at Canesta, acquired by Microsoft. Tim earned a BSEE from the University of Virginia, and a M.S. degree in Electrical and Computer Engineering from North Carolina State University.
Ian Riches is a Director in the Global Automotive Practice at Strategy Analytics. He heads a research team that covers all aspects of embedded automotive electronic systems, semiconductors and sensors on a worldwide basis, including high-growth areas such as hybrid and electric vehicles and advanced driver assistance systems. With over eighteen years of experience, he is one of the foremost industry analysts in the automotive electronics sector. Ian holds an MA in engineering from Cambridge University, UK.
Gaurav Agarwal is currently responsible for Texas Instruments' ADAS processor business in Asia. Previously, he has led several other businesses for TI, including Wi-Fi Display, HMI (human-machine interface), and OMAP for end equipment. He has written several white papers, blogs and peer-reviewed articles in the fields of machine vision and automotive vision. He also holds two U.S. patents. Gaurav has a Bachelors of Science degree from IIT Kanpur, India, a Masters of Science from the University of Maryland, College Park, and a MBA from the McCombs School of Business at the University of Texas, Austin.
Marco Jacobs, Vice President of Marketing at videantis, has over 15 years of experience in the semiconductor IP industry and multimedia applications. At videantis, he is responsible for corporate and product marketing and works with Tier 1 semiconductor manufacturers to bring novel, higher-quality video and vision applications to their customers. Prior to joining videantis, Marco was VP of Marketing at Vector Fabrics, Director of Multimedia Marketing at ARC, held management positions at semiconductor startups Silicon Hive and BOPS, and was a software architect at Philips. Marco studied computer science at the Delft University of Technology in the Netherlands and at the University of North Carolina, Chapel Hill. He holds 7 issued patents.