
This article was originally published at Information Display Magazine. It is reprinted here with the permission of the Society of Information Display.
Signs that see and understand the actions and characteristics of individuals in front of them can deliver numerous benefits to advertisers and viewers alike. Such capabilities were once only practical in research labs and niche applications. But semiconductor price, performance, and power-consumption trends are now making audience analytics, gesture interfaces, augmented reality, and other features feasible for high-volume mainstream deployments.
by Brian Dipert, Rabindra Guha, Tom Wilson, and Robert Green
The digital-signage market is one of the brightest stars in today’s technology sector, both in replacing legacy static signage in retail and other environments and in expanding the overall market for advertising, information, augmented reality, and other applications. While digital signage has been around for decades in the form of LED-based signs, it has taken off and evolved in recent years due to a variety of factors, including computing technology that is both better and lower cost, and a growing understanding of ROI and content management on the part of deployers. Analyst firm IHS has forecasted that the digital-signage market will reach $17.1 billion by 2017, from $13.2 billion in 2012.1
The integration of vision-processing capabilities within digital signs is a critical element in the market-growth momentum that IHS and other analyst firms forecast. These types of image perception, understanding, and decision-making processes have historically been achievable only using large, heavy, expensive, and power-draining computers and cameras. Thus, computer vision has long been restricted to academic research and relatively low-volume production designs by virtue of the high cost and high power consumption of the required hardware. However, with the emergence of increasingly capable processors, image sensors, and memories, along with robust algorithms, it has become practical and cost-effective to incorporate computer-vision capabilities into a wide range of systems, including digital signs.
Audience Analytics
The ultimate aim of digital signage is to make money for advertisers. In comparison to traditional static posters, even basic digital-signage implementations, which distribute advertisements to network-connected screens, have proven to be effective in attracting audiences to products and services. However, despite compelling content such as frequently updated still images and even high-quality video, conventional digital signage is becoming commonplace, thereby muting its initial wow factor. And such elementary approaches only support “blanket” delivery of a generic set of content, regardless of who is looking at the screen at any particular point in time.
A more compelling approach involves using a camera, either embedded within or located near the display, to determine the age range, gender, ethnicity, and other attributes of the viewer(s), thereby enabling the delivery of audience-tailored content. Emerging technologies such as face detection and audience analytics are making a critical difference in such applications. Targeted advertising holds the viewer’s attention longer, resulting in longer memory retention of the advertisement and translating into higher sales. Other benefits include the ability to track shoppers as they move through the store via multiple signage locations, thereby determining general traffic flow, analyzing interests and bottlenecks, and resulting in optimized store layouts.
Person Discernment
Detecting people in order to count them and subsequently determine more about them is a challenging computing task for a number of reasons. The object of interest can be difficult to discern in poor lighting conditions and in environments containing cluttered backgrounds, for example, and people have a wide range of appearances (including clothing options), body sizes, and poses. But automotive applications have shown that with in-car cameras and analytics algorithms, it is now possible to detect pedestrians with such accuracy that driver-assistance systems are even employed to help control the car and avoid collisions.2 Such algorithms are conceptually also applicable to digital-signage analytics setups.3
Xylon’s logiPDET Pedestrian Detector is an example of an intellectual property (IP) core developed for vision-based applications.4 The techniques employed by logiPDET follow the common principles of all such systems; detect an object, then classify it. In this particular case, the Histogram of Oriented Gradients (HOG) is a feature descriptor that describes the structure of a pedestrian, while the Support Vector Machine (SVM) is a machine-learning algorithm that is trainable to recognize HOG descriptors of people. By means of a movable detection window, logiPDET computes a HOG descriptor at each window position, which then transfers to the SVM in order to determine whether the object should be classified as a person.
Xylon’s logiBAYER Color Camera Sensor Bayer Decoder IP core captures, pre-processes, and stores the input video image in external memory (Fig. 1).
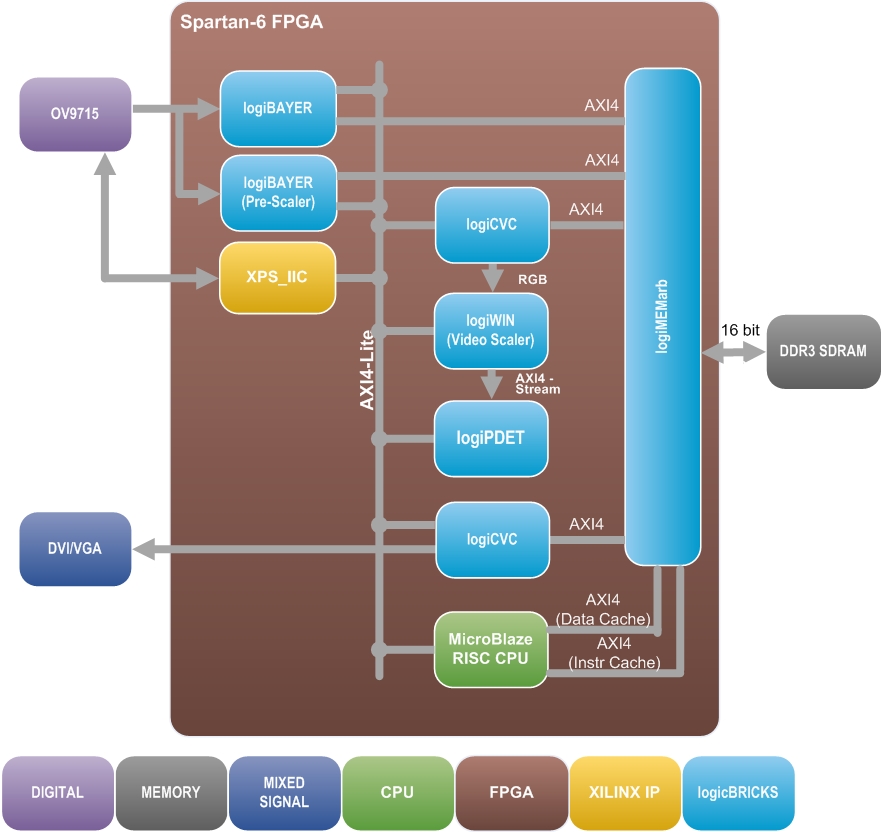
Fig. 1: Xylon’s pedestrian detection reference design is based on Xilinx FPGAs, which combine ASIC-like performance, logic density, and low power consumption with implementation flexibility analogous to that of software running on a CPU – all attractive attributes in vision processing.
LogiPDET then works in combination with the logiCVC-ML Compact Multilayer Video Controller and logiWIN Versatile Video Input IP cores to detect and categorize pedestrians at various sizes, in order to enable detection at various distances. A second logiCVC-ML core then outputs the video of the detected pedestrians to the screen (Fig. 2).

Fig. 2: The logiPDET Pedestrian Detector leverages other Xylon-developed cores to capture and pre-process incoming images, then output results to the display.
Detecting pedestrians in real time is perhaps obviously necessary in automotive driver-assistance systems and is desirable in many digital-signage applications as well. High-speed processing is a key means of ensuring sufficient detection and classification performance. Such performance can also be harnessed in digital-signage designs to enable the simultaneous detection of multiple passersby, with the processor remaining cost-effective and small in footprint, as well as consuming little system power. Low power consumption translates into low heat generation, thereby enabling digital-sign designs that are thinner, lighter, more reliable (no fans), and more economical to manufacture than would otherwise be possible.
Facial Analysis
Face-analysis software is currently able, with impressively high accuracy, to determine signage viewer characteristics such as age range (child, teenager, adult, senior citizen), gender, ethnicity, and even emotional state. In combination with data on the location and time of each viewing, it enables advertisers to discern demographics of the people looking at the digital signs. And the analytics algorithms are then also able to serve up an optimum advertisement or other piece of information to each viewer.5
Detecting the face is a reasonably straightforward exercise since most humans have the same basic eyes, nose, and mouth. Scanning the image frame for areas of dark and light corresponding to similar areas in stored reference images is well within the capabilities of even today’s basic consumer digital still cameras and camera phones. Complications can arise when the viewer wears headgear (scarves, hats, glasses, etc.), but with more reference data and increased algorithm sophistication, a face detector can be taught to identify such a viewer.
As with the HOG/SVM technique, a facial analysis system typically stores and classifies hundreds of low-level visual features, such as dark and light zones and the distances between various reference points on the face. Many combination sets of these zones and distances need to be evaluated by the detection algorithm in order to accurately ascertain gender, ethnicity, and other attributes. Length of hair alone is insufficient to determine whether someone is male or female, for instance. Categorization accuracy depends on how well the algorithm has been “trained” (i.e., the quality of reference images for comparison, for example). It also depends on environmental factors such as lighting conditions, on image sensor quality, and on other factors. For example, it is difficult to accurately discern faces and their expressions when the viewer is not looking directly at the camera; profiles are particularly challenging to analyze.
A face detector is provided for embedded vision applications in the OpenCV (Open Source Computer Vision) library, available for multiple operating systems and processor options.6 The algorithm uses the popular Viola-Jones method of computing an integral image and then performing calculations on areas defined by various black and white detection rectangles to analyze the differences between the dark and light regions of a face, as shown in Fig. 3.7

Fig. 3: This OpenCV face detection example uses the Viola-Jones technique.
A sub-window then scans across the image at various scales to establish if there is a potential face within the window. In the post-processing stage, all the potential faces are checked for overlaps, with multiple potential matches needed to confirm the presence of a face.
After detecting a face, it is then possible to use the same dark- and light-zone measurements to ascertain the viewer’s age, gender, and ethnicity. Technology developer Amscreen, for example, is implementing automated advertising analytics in thousands of gasoline stations and convenience stores across Europe.8 The company claims that its system is capable of monitoring and reporting on consumers’ advertising viewing habits, providing a break-down of the gender, age, date, time, and volume of viewers of various advertisements. Intel and Kraft also recently developed a vending machine that dispenses samples of a pudding product aimed at adults called “Temptations by JELL-O”… but only if the automated facial analysis algorithm running inside the system decides that the user is old enough to fit the target audience demographic.9
Another recent example involves bus-stop-installed billboards from Plan UK, a charity organization that raises funds for educating girls in third-world countries. The billboard will only display a complete promotional clip if it decides (with claimed 90% accuracy) that a female is looking at it. Why? Quoting from the organization, “men and boys are denied the choice to view the full content in order to highlight the fact that women and girls across the world are denied choices and opportunities on a daily basis due to poverty and discrimination.”10
It is even possible to establish viewers’ emotional states.11 This information can be extremely useful when deciding what content should be shown on-screen and in measuring the effectiveness of the content. Primary emotions (6–8 in number, depending on which researcher’s theory you follow) are easiest to measure, with secondary emotions more difficult to determine (Fig. 4).
Fig. 4: Facial expressions are capable of communicating a wide range of emotions; these are some of the primary ones that analysis algorithms strive to discern.
Gesture Interfaces
The previously described applications for digital signage constitute a largely one-way information flow to the advertiser, with the consumer primarily a passive participant in the process. However, digital signage is rapidly also becoming interactive, adopting Natural User Interfaces (NUIs). The focus here is on the gesture aspects of NUIs, although the term also encompasses touch, gaze tracking, and other concepts. Gesture recognition offers the audience the opportunity to directly interact with signage and retail kiosks and, ultimately, the advertiser and retailer (Fig. 5).


Fig. 5: Augmented reality enables you to “try on” new outfits in a virtual dressing room environment, whether for fun (top) or more serious shopping purposes (bottom).
This interaction can control the interface and select among a variety of options or it can provide dynamic feedback.12
There are numerous examples of gesture interfaces gaining ground in the world of digital signage. These instances span a range of use cases and installation scenarios. For example, in late 2013, Quebecor Media and the Société de transport de Montréal installed gesture-controlled digital signage in Montreal bus shelters. Commuters use gestures to navigate through menu items in order to access weather and news information, as well as bus and Metro schedules.
Multiple vision technologies are also coming together to create a more complete user experience. The Grab & Go kiosk, for example, combines gesture recognition and QR codes (i.e., marker detection) in an interactive system. After activating the gesture interface by means of the QR code, consumers can select items promoted on interactive screens and “drag” them into their mobile phones with hand gestures. Once such products or information are gathered, a consumer can then share this information with others over social media, save it on the phone, and even purchase the items directly from the phone.
Augmented Reality
The Grab & Go kiosk’s ability to allow consumers to swipe items from the virtual world of the digital sign directly into their mobile electronics devices is a creative example of yet another vision-processing application, augmented reality (AR).13 The integration of AR experiences with digital signage is accelerating rapidly. One interesting example is a recent campaign by Pepsi in London. Commuters within a bus shelter were treated to an augmented view of the street scene, containing attacking alien ships or rampaging tigers. Promotional campaigns like this one are capturing the imagination of the public and, in the process, demonstrating the promotional value of AR technology. Much of the near-future revenue associated with AR, in fact, is expected to come from advertising.
However, AR has a role to play beyond the standard advertising paradigm.14 Digital signage can combine with AR to enhance the fitting-room experience, allowing shoppers to virtually “try on” clothing, accessories, and makeup.15 Zugara, for example, recently introduced an updated version of a virtual dressing-room experience, where a shopper is able to dynamically alter the color of their clothing via an AR display (Fig. 6).
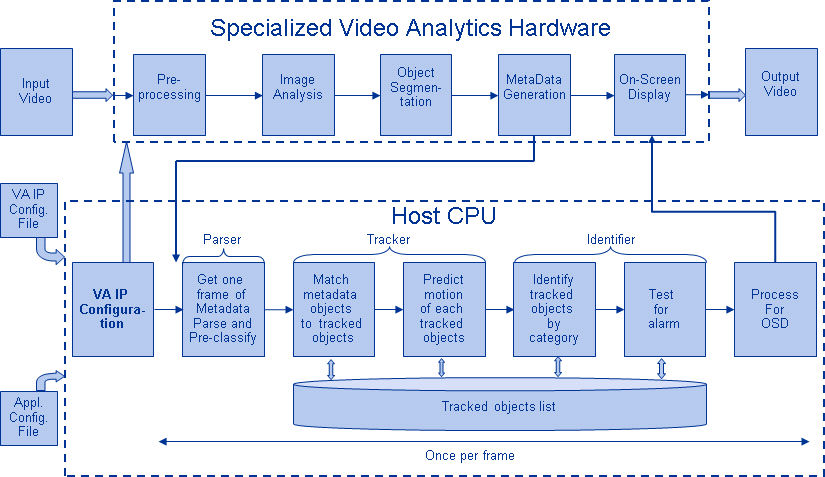
Fig. 6: Gesture interfaces offer the opportunity to directly interact with signage and retail kiosks, in order to control the interface and select among a variety of options and to provide dynamic feedback.
Another example is the FaceCake Swivel system, wherein the consumer interacts with a digital display using gesture recognition to select clothing and accessories. The AR view provided by Swivel lets the shopper instantly visualize how the items would appear in a real setting.
Industry Assistance
Swivel uses a Microsoft Kinect 3D sensor to implement gesture control, but the types of sensors (2-D versus 3-D, and 3-D variant) vary across the systems discussed here.16 Sensor selection, in fact, has a significant impact on the function of the digital-signage application. The Web site of the Embedded Vision Alliance contains an abundance of technical resources on processors, sensors, software, and other aspects of vision-enabled system designs.17
The rapidly expanding use of vision technology in digital signage is part of a much larger trend. From consumer electronics to automotive safety systems, vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. The Embedded Vision Alliance uses the term “embedded vision” to refer to this growing use of practical computer-vision technology in embedded systems, mobile devices, special-purpose PCs, and the cloud, with digital signage being one showcase application.
Vision processing can add valuable capabilities to existing products, such as the vision-enhanced digital-signage systems discussed in this article. And it can provide significant new markets for hardware, software, and semiconductor manufacturers. Implementation challenges remain in some cases, but they are largely no longer defined by a dearth of hardware capability potential. Instead, they usually center on selecting an optimum hardware implementation among contending candidates, along with the development and optimization of software that exploits this hardware potential and resolves often-unique design requirements. The members of the Embedded Vision Alliance, along with other key industry organizations and players, are working hard to address these remaining challenges as quickly and robustly as possible. As such, the future is bright for practical computer vision, both in digital signage and a plethora of other high-volume applications.
About the Embedded Vision Alliance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision-enhanced digital-signage systems into reality (Fig. 7). CogniVue and Xilinx, the co-authors of this article, are members of the Embedded Vision Alliance.
Fig. 7: The embedded-vision ecosystem spans hardware, semiconductor, and software component suppliers, subsystem developers, systems integrators, and end users, along with the fundamental research that makes ongoing breakthroughs possible.
The Alliance’s mission is to provide product creators with practical education, information, and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Alliance maintains a Web site (www.embedded-vision.com) providing tutorial articles, videos, code downloads, and a discussion forum staffed by technology experts. Registered Web site users can also receive the Alliance’s twice-monthly email newsletter (www.embeddedvisioninsights.com), among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy (www.embeddedvisionacademy.com). Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCV. Access is free upon registration.
The Alliance also holds Embedded Vision Summit conferences in Silicon Valley (www.embeddedvisionsummit.com). These are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Alliance member companies. These events are intended to:
- Inspire attendees’ imaginations about the potential applications for practical computer-vision technology through exciting presentations and demonstrations.
- Offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and
- Provide opportunities for attendees to meet and talk with leading vision-technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May, 2014, and a comprehensive archive of keynote, technical tutorial, and product demonstration videos, along with presentation slide sets, is available on the Alliance Web site. The next Embedded Vision Summit will take place on May 12, 2015, in Santa Clara, California.
References
- http://press.ihs.com/press-release/design-supply-chain-media/global-digital-signage-market-nears-14-billion-spurred-real-
- https://www.embedded-vision.com/platinum-members/embedded-vision-alliance/embedded-vision-training/documents/pages/adas
- https://www.embedded-vision.com/industry-analysis/blog/2014/02/10/embedded-vision-detect-pedestrians
- http://www.logicbricks.com/Solutions/Pedestrian-Detection-LDW-DA-System.aspx
- https://www.embedded-vision.com/industry-analysis/blog/2014/01/27/automated-face-analysis-gets-real
- https://www.embedded-vision.com/platinum-members/bdti/embedded-vision-training/documents/pages/introduction-computer-vision-using-op
- http://www.vision.caltech.edu/html-files/EE148-2005-Spring/pprs/viola04ijcv.pdf
- https://www.youtube.com/watch?v=wvfe8tlhsNA
- https://www.embedded-vision.com/news/2012/01/07/no-pudding-you-kids-intel-and-kraft-may-be-cruel
- https://www.embedded-vision.com/news/2012/02/22/gender-triggered-advertising-embedded-vision-based-chastising
- https://www.embedded-vision.com/platinum-members/embedded-vision-alliance/embedded-vision-training/videos/pages/sept-2012-summit-morning-keynote
- https://www.embedded-vision.com/platinum-members/embedded-vision-alliance/embedded-vision-training/documents/pages/gesture-interface-compelling
- https://www.embedded-vision.com/platinum-members/embedded-vision-alliance/embedded-vision-training/documents/pages/augmented-reality
- https://www.embedded-vision.com/industry-analysis/video-interviews-demos/2012/01/15/bodymetrics-virtual-clothes-shopping-demonstration
- https://www.embedded-vision.com/news/2012/05/10/makeup-selection-embedded-vision-based-determination
- https://www.embedded-vision.com/platinum-members/embedded-vision-alliance/embedded-vision-training/documents/pages/3d-sensors-depth-discernment
- https://www.embedded-vision.com/platinum-members/bdti/embedded-vision-training/documents/pages/implementing-vision-capabilities-embedded
Sidebar: Vision-Based Security and Surveillance Capabilities
Vision processing in digital signage enables dynamic new customer insights, shopping experiences, and user interfaces. Additional opportunities exist to leverage those same cameras and processors in security and surveillance applications.a Such digital signage can be placed where security cameras are not typically located. For example, some digital displays are co-located with Point of Sale (POS) terminals. These terminals typically have two display screens, one facing the cashier and the other facing the shopper. The cashier-facing display allows the operator to monitor his or her transaction actions, while the customer-facing display combines digital signage with a read-out of those same transactions.
Adding a camera to each display screen allows for a new level of security, both for fraud detection (operator side) and theft detection (customer side). Fraud detection can involve recording and time-stamping all cash transactions. In addition, the vision application can monitor the operator’s productivity and activity via analytics. For example, a POS terminal with a facial recognition function can ensure that the operator logged into the system matches the person who is currently in control of the cash drawer.
Such checking prevents thefts that might otherwise occur if the operator has been compromised. The POS terminal will lock down if an unknown operator is accessing the cash drawer. This concept goes beyond theft; it is also pertinent in protecting against malware. In a document titled “DBIR 2014: Point-of-Sale Attack Trends – The State of Security,” Tripwire, a maker of IT and security products, stated that a two-factor authentication of users accessing a POS terminal was listed as a recommended strategy to protect the POS network against malicious software infection.b
Alternately, applications that detect facial emotional cues in the cashier, such as fear or anxiety, can find use in detecting potential criminal situations. Similarly, facial analysis software can be used to detect masks or threatening behavior on the customer-facing camera side. The integration of these small and innocuous cameras within the POS system’s digital signage enables a new range of security and surveillance solutions.
Sidebar References
- http://www.embedded.com/design/real-world-applications/4430389/Vision-based-artificial-intelligence-brings-awareness-to-surveillance
- http://www.tripwire.com/state-of-security/security-data-protection/dbir-2014-point-of-sale-attack-trends/
Brian Dipert is Editor-in-Chief of the Embedded Vision Alliance (www.embedded-vision.com). He is also a Senior Analyst at BDTI (www.bdti.com) and Editor-in-Chief of InsideDSP, the company’s online newsletter dedicated to digital-signal-processing technology (www.insidedsp.com). Rob Green has worked in the programmable logic industry for almost 20 years, the last 14 of them at Xilinx (www.xilinx.com), where he has participated in both the broadcast and consumer vertical markets. Rabin Guha is a Senior Architect and Project Lead at CogniVue (www.cognivue.com), with 20 years of experience in bringing SoC and FPGA products to the enterprise and consumer markets. Tom Wilson is Vice-President of Business Development at CogniVue (www.cognivue.com), with more than 20 years of experience in various applications such as consumer, automotive, and telecommunications. He has held leadership roles in engineering, sales, and product management.