This article was originally published at Imagination Technologies' website, where it is one of a series of articles. It is reprinted here with the permission of Imagination Technologies.
Heterogeneous architectures in embedded computing are fast becoming a reality – we indeed see many leading IP and semiconductor companies today building heterogeneous computing hardware.
In the article below, I’m going to describe one typical use case for heterogeneous computing and the challenges that result from moving to a heterogeneous programming model.
Running a beautification algorithm on a modern SoC
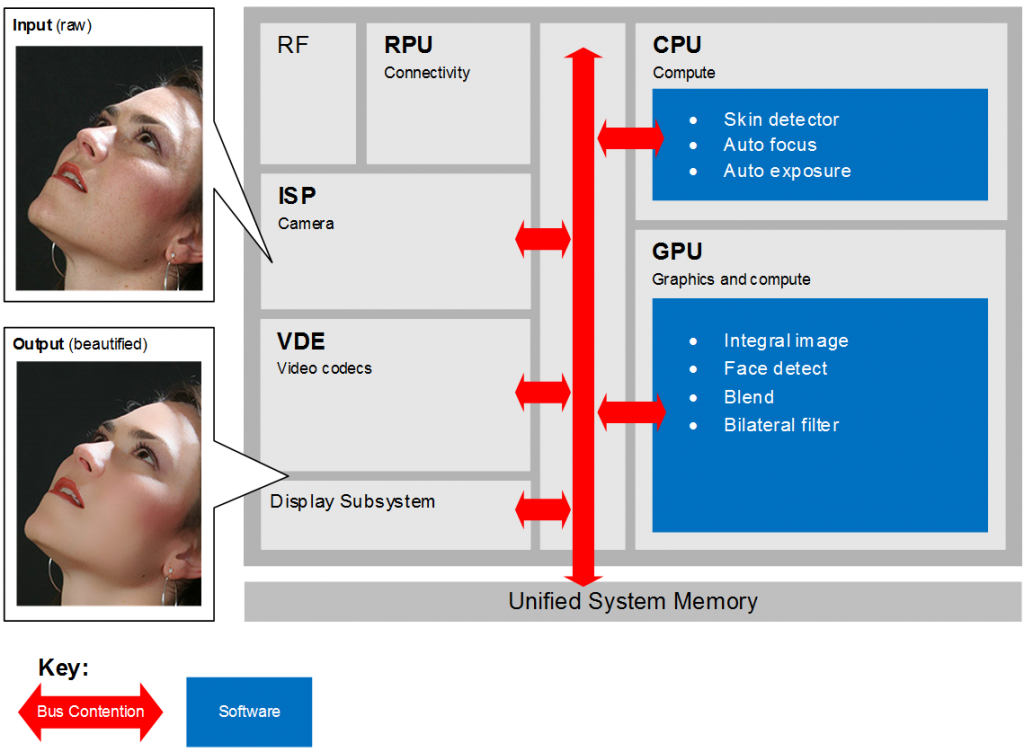
The diagram below illustrates how a video recording application that performs beautification might be implemented using a number of heterogeneous hardware and software components. In this example, input frames captured by the ISP/camera are first inspected by the GPU to determine the position of a face and its individual features (i.e. eyes, lips, nose and possibly others), passing these coordinates along to the CPU which tracks and automatically adjusts the camera focus and exposure to maintain high quality video. The CPU also determines which parts of the face contain skin colour, and the GPU applies a bilinear filter which smooths these textures, removing artefacts that represent blemishes and wrinkles, while preserving sharpness around the edges of the face.
The sequence of transformed images is output to both the hardware encoder for recording to disk and to the display subsystem for rendering in a preview window. As an additional optimization, the CPU could instruct the hardware encoder to encode the face coordinates at higher-fidelity than the background, optimizing both video quality and file size. In this scenario, at least five different hardware components require access to the image data in memory.
Memory bandwidth constraints
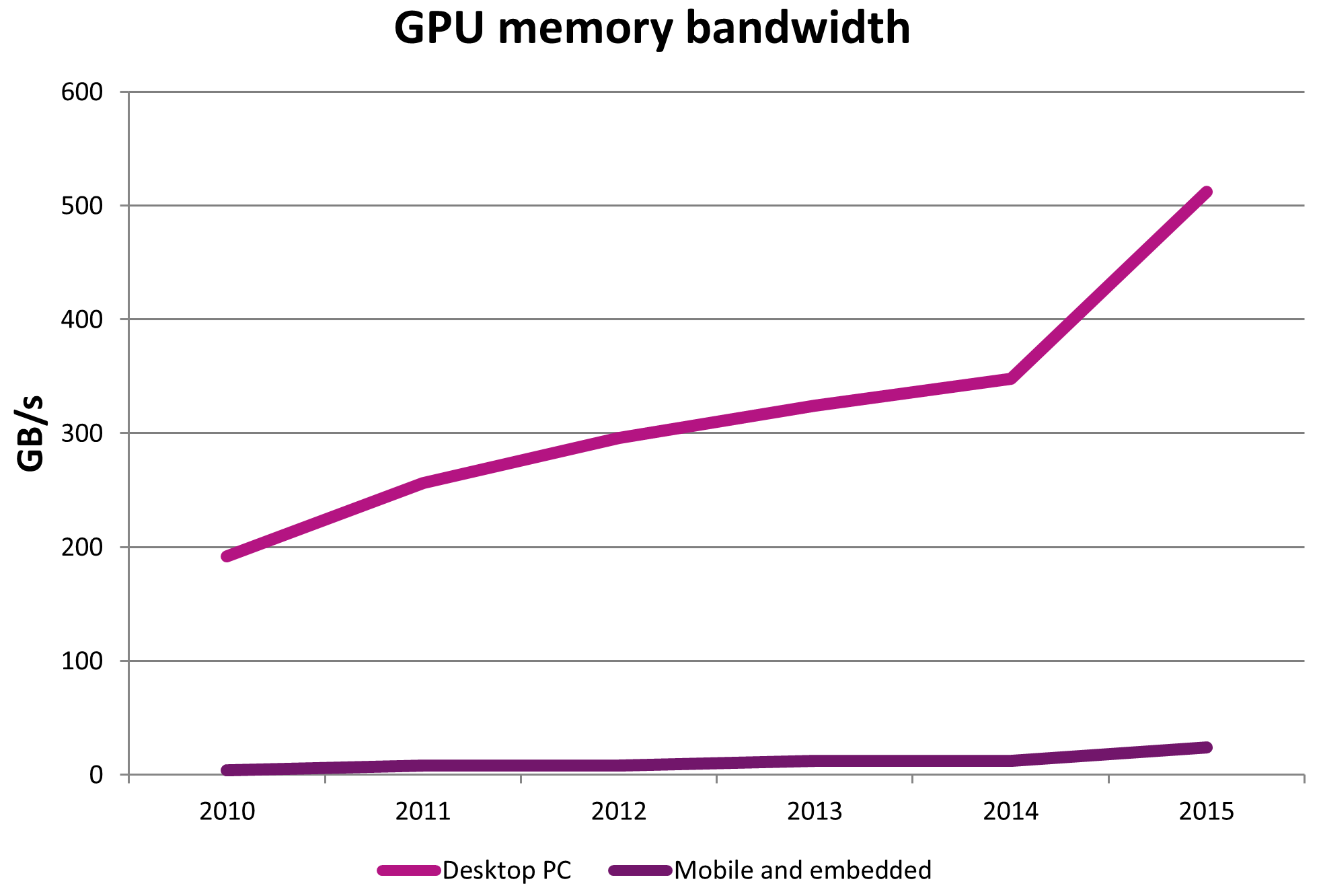
A key characteristic of many SoCs is the presence of a single unified system memory such as an off-chip DDR DRAM, which is shared between all hardware components. These components typically communicate with other components and with memory using a shared bus or interconnect, the bandwidth of which is tightly constrained to limit implementation area and cost. SoC bandwidth is frequently an order of ten times less than is common on desktop-class machines with PCI Express buses, and is a common performance bottleneck–particularly in cases where multiple hardware components attempt to access memory and other I/O at the same time.
Furthermore, when an application passes ownership of data between different hardware components, the underlying operating system may create a duplicate copy of the data in memory. In some cases this may be due to hardware limitations, for example where the GPU requires access to data allocated by the CPU in virtual memory that CPU can page to disk at will. In other cases this may be related to image formats; for example, the ISP produces image sensor data in YUV format but the CPU or GPU needs to filter this data in RGB colour space.
Conversely, some operating system such as Android automatically convert images from YUV to RGB format before presenting the data to developers (for example, as OGLES_TEXTURE_2D textures); this can reduce the efficiency of many vision algorithms that only need to process image luminance data. The inefficiencies introduced by these behind-the-scene copies can be quickly compounded when processing high-resolution image data at video rate.