The substantial parallel processing resources available in modern graphics processors makes them a natural choice for implementing vision-processing functions. The rapidly maturing OpenCL framework enables the rapid and efficient development of programs that execute across GPUs and other heterogeneous processing elements within a system. In this article, we briefly review parallelism in computer vision applications, provide an overview the OpenCL programming language, and then dive into optimization techniques for computer vision applications based on OpenCL and leveraging GPU acceleration, along with introducing an industry alliance intended to help product creators incorporate vision capabilities into their designs.
As mentioned in the initial article in this series, significant portions of many computer vision functions are amenable to being run in parallel. As computer vision finds increasing use in a wide range of applications, exploiting parallel processing has become an important technique for obtaining cost-effective and energy-efficient implementations of vision algorithms. GPUs are strong candidates for massively parallel-processing implementations. Recent announcements from graphics processor chip and core suppliers such as AMD, ARM and Intel tout devices containing dozens to hundreds of parallel processing elements, accompanied by abundant on- and off-chip memory and interconnect resources, along with a profusion of high-speed interfaces to maximize data transfer rates between them and other system components.
Of course, not everything can be parallelized; even the most parallelizable vision processing algorithms still contain a significant percentage of serial control and other code, for which a GPU is an inferior implementation option. Fortunately, modern SoCs also embed one or more CPU cores, tightly integrated with the GPU and other on-chip resources, to handle such serial software requirements. And for systems with stand-alone GPUs, a CPU or MCU almost always exists elsewhere in the system.
How, though, can you straightforwardly evaluate various vision algorithm partitioning scenarios between the GPU and other processing resources, ultimately selecting and implementing one that's optimal for your design objectives? That's where OpenCL comes in. Created and maintained by the Khronos Group industry consortium, the OpenCL standard defines a set of programming languages and APIs for heterogeneous parallel programming that can be used for any application that is parallelizable. OpenCL originally targeted heterogeneous systems with CPUs and GPUs but it now supports a variety of other parallel processing architectures, including FPGAs, DSPs, and dedicated-function vision processors.
Some tradeoff between code portability and performance is still inevitable today; creating a highly efficient OpenCL implementation requires knowledge of specific hardware details (either by yourself or the developers of the OpenCL function libraries that you leverage) and may also require the use of vendor-specific extensions. Both of these topics will be explored in more detail in the remainder of this article. And over time, many of these lingering issues will continue to be addressed; note, for example that C++ programming techniques are available in the latest version of OpenCL.
The Evolution of GPGPU
Image processing and computer vision are established fields with ever increasing importance, market relevance, and mass appeal. The core technology has application in multiple vertical markets, from data-mining still images and videos on a server or indexing your own image and video collection on a desktop PC, to implementing natural user interfaces such as gesture control and face-recognition login on a notebook PC. In all of these cases, a fundamental and common need exists to process millions if not billions of pixels' worth of information as quickly as possible. Fortunately, this is a much less daunting task than it used to be. In fact, modern massively parallel processors are more than capable of handling it.
GPUs were originally designed solely to compute pixel values for the purposes of displaying them on the screen. Over time, the industry realized that there is an equally strong benefit to exposing GPU capabilities in a more programmable fashion. As a result, formerly fixed graphics pipelines evolved to become full-fledged massively parallel processors that can be used for general data-parallel tasks, beyond pixel value computations. This approach is commonly known as GPGPU (general purpose computing on graphics processing units), the expanded use of graphics processors for a variety of non-graphics tasks.
GPUs are uniquely suited for data parallelism. Typically, an integrated GPU on a PC processor will have one to several dozen GPU cores, with a discrete PC GPU containing even more. And each AMD GPU core, for example, has 4 SIMD units, with each SIMD cable of concurrently running 64 threads (note that different GPU manufacturers' cores containing varying amounts of per-core integration). The modern trends embodied by GPUs involve employing scalar architectures supporting multiple concurrent threads, with the compiler and associated runtime transforming the GPU performance potential into reality.
Of course, modern CPUs also implement parallelism. First, they support multiple threads and multiple cores. A typical consumer PC processor might have between 2 and 4 CPU cores, with each core running 1 to 2 threads (the latter if hyper-threading is enabled). While this ability is important for task parallelism, it is insufficient for data parallelism. Therefore, many CPUs also support vectorized instructions (also known as integer intrinsics) – examples include Intel’s SSE and AVX. However, taking advantage of a processor's vector capabilities nontrivial, non-automatic task. Moreover, GPU are capable of supporting significantly higher concurrent-thread counts than a CPU simply due to the sheer number of cores and SIMD units.
Although CPUs and GPUs initially evolved independently, the industry has now recognized the value in combining them, to take advantage of their individual strengths. Today, practically all PC CPUs have integrated GPUs, and such multi-core integration is also the de facto approach for application processors tailored for smartphones and other mobile devices. We now live in the era of heterogeneous computing, where CPUs and GPUs are not only integrated on the same die but also efficiently synchronize access and operate on the same data from main memory, without need for redundant copies. And on a PC, you can always supplement an integrated GPU with one or more discrete GPUs for additional parallel processing power.
OpenCL Overview
Consider a simple C program that multiplies the corresponding elements in two 2-dimensional arrays:
void matrix_mul_cpu(const float *a, const float *b, float *c, int l, int h)
{
int i;
for (i=0; i<l; i++)
for (j=0; j<h; j++)
c[i][j] = a[i][j] * b[i][j];
}
The for loop consists of two parts: the vector range (two dimensions containing l*h elements), and a multiplication operation. All loop iterations are independent in that there are no data dependencies between any of them. This means that the multiplication operations can be executed in parallel on the GPU’s numerous threads.
OpenCL programs consist of two parts: one that runs on the host CPU, the other running on the GPU. To execute code on the GPU, you first define an OpenCL kernel, which is written in a variant of C with some additional keywords and data types. Continuing with the previous example, an OpenCL kernel that implements a single multiplication is as follows:
_kernel void vector_mul(__global const float *a, __global const float *b, __global float *c)
{
size_t i = get_global_id(0);
size_t j = get_global_id(1);
c[i][j] = a[i][j] * b[i][j];
}
The host program launches (or enqueues) this kernel, spawning a virtual grid of concurrent work-items. The grid is an N-dimensional range where N=1, 2 or 3 (or NDRange). A single work-item executes for each point on the NDRange; each work-item executes the same kernel code but has a unique ID that can be queried and used to determine the data to be processed. This ID is obtained using the built-in function get_global_id. In OpenCL, multiple work-items are grouped together to form workgroups. Work-items in a workgroup can synchronize with one another and share data using local memory.
OpenCL's Evolution
GPGPU has come a long way from the early days of imperfectly expressing general-purpose computational problems in terms of graphics-tailored APIs such as DirectX and OpenGL. In recent years, GPGPU's adoption by the industry has been accelerated by the availability of OpenCL, which was announced in 2008 initially as an open GPGPU standard. Since that time, OpenCL has evolved along with GPUs. More recently OpenCL's utility has further expanded, enabling it to become the leading open standard for heterogeneous computing across a diversity of processor types.
The choice of which OpenCL version to use is primarily dictated by the level of support provided by the vendor of the GPU hardware you plan to use in your design (Table 1). OpenCL has evolved in a backward-compatible manner in order to preserve code investment, with new features seamlessly integrated with legacy features in order to minimize version-transition difficulties.
|
OpenCL Features |
OpenCL Version |
||||
|
1.1 |
1.2 |
2.0 |
2.1 |
2.2* |
|
|
OpenCL 1.1 legacy features |
x |
x |
x |
x |
x |
|
Device partitioning |
|
x |
x |
x |
x |
|
Separate compilation and linking |
|
x |
x |
x |
x |
|
Built-in kernels |
|
x |
x |
x |
x |
|
DirectX interoperability |
|
x |
x |
x |
x |
|
IEEE-754 compliance |
|
x |
x |
x |
x |
|
Shared virtual memory |
|
|
x |
x |
x |
|
Nested parallelism |
|
|
x |
x |
x |
|
Generic address space |
|
|
x |
x |
x |
|
C11 Atomics |
|
|
x |
x |
x |
|
Pipes |
|
|
x |
x |
x |
|
Android Installable Client Driver Extension |
|
|
x |
x |
x |
|
Subgroups |
|
|
|
x |
x |
|
Copying of kernel objects and states |
|
|
|
x |
x |
|
Low-latency device timer queries |
|
|
|
x |
x |
|
SPIR-V 1.0 support |
|
|
|
x |
x |
|
Priority hints |
|
|
|
x |
x |
|
Throttle hints |
|
|
|
x |
x |
|
OpenCL C++ kernel language |
|
|
|
|
x |
|
SPIR-V 1.1 support |
|
|
|
|
x |
|
Sub-group named barriers |
|
|
|
|
x |
*The OpenCL v2.2 specification version is currently in provisional (not final) status.
Table 1. OpenCL versions and their associated features
General OpenCL Optimizations for GPUs
OpenCL delivers functional portability and performance portability, but the latter only to a degree. In order to achieve peak performance on a particular hardware implementation, you must be familiar with and optimize for the specifics of the underlying architecture. It is best in such a case to consult the hardware vendor's OpenCL optimization guides. However, regardless of the architectural differences between hardware vendors, a common set of optimizations exists across most platforms, which can deliver higher performance while retaining portability:
- Minimize host-side overhead
- Minimize host-device transfers
- Maximize device occupancy
- Maximize memory throughput
- Maximize device instruction throughput
- Profile performance
Minimize host-side overhead
Host-side overhead is an often-overlooked aspect of developing applications for OpenCL. All OpenCL host-side API calls come at a performance cost, although the magnitude differs from vendor to vendor. Fortunately, this cost is relatively easy to reduce.
OpenCL includes many resource-intensive APIs that should only be called during application initialization and conversely should never be used in critical-performance portions of your application. You should also move such host-side operations outside of computation loops, performing them only once and with their results reused multiple times. Resource creation examples include:
- Allocation/deallocation of device/host memory
- Context and command queue creation
- Program creation/build
- Kernel creation/build
OpenCL enqueue API calls are generally asynchronous in nature, in order to maximize throughput on the device. To take full advantage of them, you need to avoid needless explicit synchronization between the host and the device. For example:
- Avoid block waiting on every enqueue if possible.
- Parallelize execution on the CPU and the GPU.
Finally, the time between issuing a clFlush() and a clFinish() on the host side can be used to perform other operations in parallel with the graphics processor. If the chain of dependencies between the operations permits it, parallelizing execution on the CPU and the GPU can lead to additional performance gains (Figure 1).
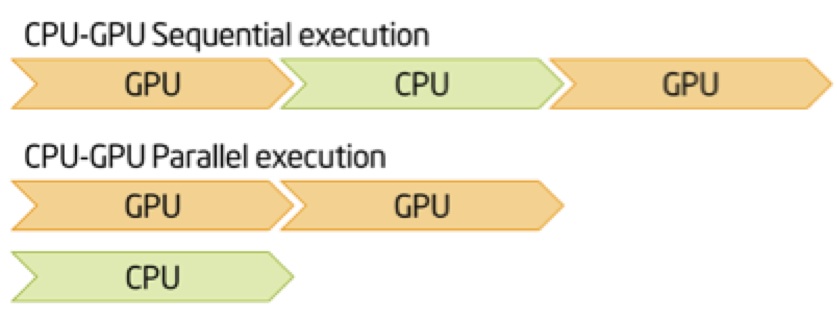
Figure 1. Executing operations in parallel (versus serially) on the CPU and GPU can lead to dramatic performance gains.
Minimize host-device transfers
Depending on the platform architecture, the host and the device may or may not share the same physical memory. For example, single die-integrated CPU and GPU cores may share a common memory controller, accessing a common pool of system DRAM. Conversely, discrete GPUs may access dedicated graphics memory, separate from the CPU’s system memory. Both cases require attention to minimize the performance cost of such transfers.
For the case when the host and the device share the same physical memory, you should follow vendor-specific guidelines on how to optimize memory transfers. For example, many OpenCL implementations on integrated SoCs ensure zero-copy behavior if you perform them inside a map/unmap pattern, such as in one of the following examples:
Example 1:
malloc() and use CL_MEM_USEss_HOST_PTR
clEnqueueMapBuffer()
buffer operations with zero copy
clEnqueueUnmapMemObject()
Example 2:
use CL_MEM_ALLOC_HOST_PTR
clEnqueueMapBuffer()
buffer operations with zero copy
clEnqueueUnmapMemObject()
Conversely, when the host and the device do not share the same physical memory, the following suggestions are particularly effective:
- Overlap computations with host-device memory transfers
- Avoid needless transfers, such as data from intermediary stages of a processing pipeline
- Avoid numerous small transfers.
Maximize device occupancy
Occupancy is a measure of the number of in-flight device hardware threads divided by the total number of hardware threads available. Phrased in OpenCL terminology, occupancy is a measure of how many available work-items (the basic unit of work on an OpenCL device) are actively performing useful work (arithmetic operations, memory reads/writes, etc) at any given time. Occupancy is very important because it generally relates to how much computation throughput (measured in GFLOPs) we can obtain from the graphics processor, as well as how power-efficient the device is for a particular application problem.
Multiple factors require consideration when striving to maximize occupancy. It's also difficult to predict, prior to analysis, the size of the work-groups or how much work should be allocated per work-item. The following list of guidelines should help narrow down the number of experiments required to maximize occupancy:
- Launch enough work-items to overfill all of the device's hardware threads.
- Launch enough work per work-item to better amortize any thread launch costs and hide latency for memory loads/stores.
- In general, the work-group size is a multiple of a certain value N, which differs from vendor to vendor. Experience suggests that an initial work-group size of 64 is a good cross-vendor choice. Larger work-group sizes may lead to additional performance gains. Leaving the work-group size up to the OpenCL runtime to determine can also be beneficial. Refer to your vendor optimization guide for more details.
- The amount of local memory used per work-item will limit the number of hardware threads active at any point in time. The more local memory allocated per work-item, the fewer the number of active hardware threads.
- It is preferable to allocate local memory inside an OpenCL kernel (versus allocating it on the host), as this approach gives the compiler more information for optimization purposes.
- The number of barriers that can be set can also be a limiting factor on the number of active hardware threads. Again, refer to your vendor optimization guide for more details.
Maximize memory throughput
The first key action you can take in maximizing memory throughput involves maximizing the use of compute unit registers, as they are typically the fastest available type of memory. Implementation suggestions include:
- Avoid writing kernels with a large number of variables
- Recompute values instead of storing them in variables
- Split large kernels into smaller kernels, each requiring fewer registers. In doing so, however, be mindful of the overhead of launching kernels
- Also be mindful of occupancy issues and "spilling." Too much register pressure leads to a lower number of active hardware threads and/or to spilling register contents to global memory, depending on the target architecture. The primary means of detecting such issues is by using vendor-specific profiling tools
Next, strive to minimize the number of cache lines "touched". For example, on Intel Processor Graphics, an L3 cache line is 64 bytes long; you'll want to organize the reads and writes, along with and the data types used, in such a way as to maximize the cache-line-hit ratio by modifying the access pattern to fall within a cache line (Figure 2).





Figure 2. Modifying read and write access patterns, as well as data types used, to align with cache line sizes will maximize the cache-line-hit ratio.
Also, choose a data type that maximizes cache line and register efficiency. Given their common RGBA data structure lineage, many GPUs are optimized for vector float4 data quantities. Using float4 data types instead of smaller scalar float data types may yield better throughput on some architectures. And if you're using banked memory, maximize the number of banks being simultaneously "hit" at any point in time (Figure 3). On Intel Processor Graphics, for example, the local memory is partitioned into 16 banks. Maximum bandwidth is achieved in the absence of bank conflicts, i.e., either when each work-item accesses a different bank, or when accesses from different work-items to the same bank refer to the same address.





Figure 3. Maximize local memory bandwidth utilization by minimizing bank conflicts.
Finally, merge kernels to reduce memory traffic and device hardware thread launch overhead. Many vision algorithms, such as HOG (histogram of oriented gradients) consist of long processing pipelines, and it may be therefore be beneficial on some architectures to merge certain (usually small) consecutive stages. This action can help reduce memory traffic at the cost of increased register pressure and code size. The final set of suggestions in this section includes the following:
- Local memory use may or may not lead to performance gains; refer to vendor-specific optimization guidelines
- For memory alignment considerations and optimum data size when accessing memory, again refer to vendor-specific optimization guidelines
- Experiment with buffers and images. It is sometimes the case that an algorithm will favor one or the other data structure. Use cl_khr_image_2d_from_buffer in OpenCL 1.2 (a core feature in OpenCL 2.0) to convert a linear buffer to an image without a copy, but be aware that some fixed-function kernels cannot work with such images.
Maximize device instruction throughput
This objective often depends first on maximizing memory throughput. It is sometimes useful to subdivide your algorithm into two portions, memory accesses and so-called "useful work", optimizing them separately. Once you have maximized read and write throughput, you can then move on to implementing your actual algorithm. Suggestions here include:
- Trade accuracy for speed by using native built-ins and/or compiler options (e.g. -cl-fast-relaxed-math and -cl-mad-enable build flags). GPUs often come with hardware support for common math transcendental operations such as sine and cosine; such hardware implementations are significantly faster than their software equivalents for supporting standard OpenCL functions (Figure 4).
Figure 4. Hardware-accelerated OpenCL function versions can be significantly higher performance than their conventional software-only counterparts.
- Vectorize. Although the various OpenCL compilers auto-vectorize to at least some degree, they are often no substitute for manually vectorizing both arithmetic and load/store operations. On some platforms, manual vectorization can improve SIMD utilization; on others, it can improve memory performance. Consult your vendor optimization guide for more details.
- Use OpenCL built-in kernels provided through vendor-specific extensions. Many vendors offer specialized or non-programmable hardware components through vendor-specific extensions that can deliver a significant performance boost.
Profile performance
Understanding how your workload maps onto the graphics processor is vital to achieving optimal code. Profiling tools can help identify exactly where the bottlenecks exist and what subsequently needs to be done to improve your algorithm's performance and efficiency. Even in the absence of more elaborate profiling tools, using OpenCL's profiling events can be invaluable. An event is an object that communicates the status of commands in OpenCL; legal values for an event include:
- CL_QUEUED: a command has been enqueued
- CL_SUBMITTED: a command has been submitted to the compute device
- CL_RUNNING: a compute device is executing the command
- CL_COMPLETE: the command has completed, and
- ERROR_CODE: a negative value, indicating that an error condition has occurred.
OpenCL Optimizations for Server, Desktop and Notebook Computing Platforms
A developer needs to have confidence that he or she can write OpenCL code that runs reasonably well on devices ranging from low-end notebooks to high-end servers while also providing the possibility to further tune the code for optimization on particular devices if the need arises. With PCs, a primary architecture difference to consider is between integrated and discrete GPUs, particularly with respect to their differing data access schemes.
For discrete GPUs, you need to explicitly transfer the data to and from the standalone graphics card, typically over a PCIe bus. In contrast, with integrated GPUs, data is directly accessed via main memory – a significantly faster operation. Therefore, an application may want to include two implementation paths for memory transfers; well-designed software packages will abstract this divergence in order to maintain a uniform data model. OpenCV accomplishes this objective by means of the "Transparent API" (T-API) feature available beginning in OpenCV v3.0.
Using T-API, you can implement a data structure that is responsible for making data available bi-directionally by both the CPU and GPU, based on the capabilities of the underlying platform. In OpenCV this structure is called UMat, for "unified" or "universal" matrix. For devices that support OpenCL 2.0's fine-grain SVM (shared virtual memory), you need use only one data store (pointer) that can be accessed by both the CPU and GPU. When you access the data from the CPU, you may need to trigger synchronization. With a discrete GPU, you will need to trigger a data transfer. You can accomplish both of these objectives via a uniform API call that will work in either case.
It is a good idea to design such capabilities into your software, so that your code will work uniformly on all OpenCL-compliant devices. The open-source computer vision library OpenCV can provide you with ideas on how to accomplish this goal; C++ AMP also defines a conceptually similar approach. More generally, OpenCV is a very good starting point for OpenCL-enabled vision programming. Via T-API, OpenCV supporters have implemented many reusable code blocks for image processing and vision that use OpenCL. OpenCV is also useful for benchmarking and otherwise assessing the scalability of OpenCL algorithms on platforms of varying capabilities.
Beyond data transfers, a number of other optimization suggestions should be kept in mind when developing OpenCL-based code for PCs:
- Use the OpenCL API to discover the capabilities of the device, and take this information into account in your code. This step will by itself go a long way towards creating portable and well-performing code.
- View the performance optimization problem as a global optimization problem. You typically need to find the sweet spot between register usage, on-chip memory ("shared local memory" in OpenCL terminology) usage, global (host) memory accesses, and arithmetic complexity. Use profiling and analysis tools such as AMD’s CodeXL to gain a good understanding of what is worth optimizing, and how to do so. Think about optimizing pipelines, not kernels. In particular, ensure that in a pipeline, most data can be found in either L1 or L2 cache. Achieving this objective may require tiling.
- Maximize occupancy. Keep all of the available GPU cores busy, by either launching a sufficient number of work-groups, or by launching in parallel multiple independent kernels and taking advantage of the CKE (concurrent kernel execution) capabilities of the hardware. The four SIMDs in each AMD compute unit, for example, can independently handle distinct work-groups. Typically, in this case, you'll want to make sure that the number of work-groups you are launching is no less than 4x the number of compute units. Unless you have taken special care in your algorithm to prefetch data, to hide data transfer latency you will want to have at least 2-3 wavefronts (in AMD terminology; the same concept is referred to as a "warp" by NVIDIA, for example) per SIMD. This will enable the scheduler to execute code from other wavefronts while data transfers are occurring. The work-group should be a multiple of the natural wavefront size.
- Be conscious of data transfer latency, and assist the hardware in hiding it. Modern GPUs have an innate ability to fast-switch between wavefronts while data is being fetched (hence the need to have more than one wavefront queued in a SIMD). However, an expert programmer can aid this optimization process. On discrete GPUs, for example, make sure you are transferring the data asynchronously onto device memory. And on all devices, use shared local memory appropriately. Also, be aware of cache line size and make sure that you are prefetching cache lines while current threads are using data that has already been fetched. Minimize data transfers by using shared local memory intelligently. You don’t need to have each thread loading memory, even if it is cached in L2 cache, if the same memory was already loaded by another thread. It is likely better to load memory to shared local memory once, and then have other threads in the workgroup read and write or perform atomic operations from shared local memory.
- Optimize host-to-device transfers. On discrete GPUs, asynchronously prefetch data on the device. On integrated GPUs, use zero-copy as much as possible, to eliminate data copies. For OpenCL 1.2 capable devices, preferably allocate system memory by creating a buffer on the device with CL_MEM_ALLOC_HOST_PTR. On OpenCL 2.0 devices (typically integrated GPUs) that support SVM (shared virtual memory), leverage this feature. Doing so will completely eliminate data transfers and will allow you to efficiently interleave CPU and GPU execution. Finally, prioritize the use of fine-grain SVM if this resource is available.
- Consider using a texture sampler when linear interpolation is needed, or if your memory access is fairly random. Also, if your data access is random, consider packing the data in the CPU before handing it off to the GPU.
- Maximize the amount of arithmetic complexity per data access. One way to accomplish this objective is to merge kernels if each of them performs just a few arithmetic operations. However, when you do so, make sure that you are not increasing register use beyond hardware limits, as this will "spill" registers and reduce occupancy. Typically the compiler will do a good job of reusing registers, but verify its actions with profiling tools such as CodeXL.
- Trade accuracy for speed by using built-ins or compiler options (-cl-fast-relaxed-math and -cl-mad-enable).
- Minimize OpenCL API calls. If your imaging pipeline execute the same sequence of code in a loop, for example, set up the arguments to your kernels only once, and outside the loop. In the same spirit, minimize the use of synchronization points with the CPU.
- Use lock-free algorithms where appropriate. In particular, the excessive use of atomic operations may slow down performance. If you need to do atomic operations, do them in shared local memory if possible.
- Finally, with discrete GPUs, minimize access of the CPU. If context-sensitive decisions are required, use "dynamic parallelism" (i.e. GPU enqueue) to accomplish them.
Figure 5 and Table 2 present the uplift (x-factor) of running OpenCV 3.0 image processing module performance tests on three AMD GPUs, baselined to running the same tests purely on an AMD Radeon RX-427B CPU, and with an image resolution of 3840×2160 pixels. The AMD Radeon RX-427B is an embedded integrated GPU platform, the AMD Radeon E8860 is an embedded discrete GPU, and the AMD Radeon R9-290X is a desktop discrete GPU.

Figure 5. Uplift results for various GPU-inclusive platforms compare favorably to baseline CPU-only performance.
Table 2 details the cumulative uplift results.
|
Platform |
Uplift |
|
AMD Radeon RX-427B OpenCL iGPU |
5.6x |
|
AMD Radeon™ E8860 OpenCL dGPU |
15.5x |
|
AMD Radeon™ R9-290X OpenCL dGPU |
65.5x |
Table 2. The cumulative uplift of GPU-accelerated OpenCV image module code can become even more dramatic as image resolutions increase.
The data shows that OpenCL algorithms scale well with the capabilities of the underlying platform. This scaling becomes more prominent for larger images. Given the current trend toward support for higher resolutions, this is good news.
OpenCL Optimizations for Smartphones, Tablets and other Mobile Platforms
While accelerating computer vision pipelines on the GPU is now commonplace on PCs, only recently has this capability also been feasible on mobile platforms. The GPU, a now-standard feature on most mobile devices, has to date primarily found use for 3D graphics and user-interface acceleration, but modern SoC and system designs now also support GPU Compute (i.e. GPGPU).
An integrated mobile GPU differs from a PC GPU in several key ways. Mobile SoC designers have significantly less power and silicon area available to them, and no fans are available to disperse excess heat, so energy efficiency is a primary concern. On the other hand, as the SoC always contains both CPU and GPU in a single package, main memory can be shared. Used carefully, this can be a welcome benefit. A few key examples showcase times when should you consider using such a GPU for something as sophisticated and complex as computer vision on mobile device.
Consider, for example, the image pyramid algorithm (Figure 6). Widely employed in computer vision as part of feature extraction, stereo vision, object detection and other functions, the pyramid algorithm creates a set of sub-sampled images, typically applying a smoothing filter that sub-sampling in both dimensions. High performance is quite important, since use cases employing the pyramid algorithm will typically need to work in real time.
Figure 6. The image pyramid algorithm is widely used in computer vision.
As the image pyramid algorithm requires none of the target pixels to be dependent on any of the others, it is "embarrassingly parallel" – and therefore in principal a good candidate for GPU acceleration. But be careful in making this assumption, as reality is not always the case. Take a look at the following diagram, which is conceptual, i.e., not to scale (Figure 7):
Figure 7. Setup and teardown overhead may overshadow any algorithm kernel acceleration delivered by a GPU.
In comparing against the baseline time taken to compute the pyramid algorithm on the CPU, you may well see a significant performance increase when using an optimized OpenCL implementation running on a mobile GPU. But you need to fully understand what’s being measured. If all you’re doing is running a single instance of the pyramid function, you need to take into account the overall execution time for a fair comparison with a CPU-only implementation.
In particular, keep in mind the overhead necessary in preparing a job for the GPU, including driver and kernel preparation. The individual CPU and GPU caches will also need to be synchronized, both before and after executing the kernel. Although the above diagram exaggerates this overhead somewhat, it can be a very real issue. Bottom line: for whatever work you propose offloading to the GPU, the benefits you get need to more than outweigh the cost of setting the work up.
Another popular computer vision algorithm, Canny edge detection, is designed to extract edges from images (Figure 8). It has four main stages:
- A Gaussian filter to reduce noise
- A Sobel filter to identify candidate edges
- A pixel removal phase to remove unnecessary detail, and
- A hysteresis thresholding phase to form high-quality edges.
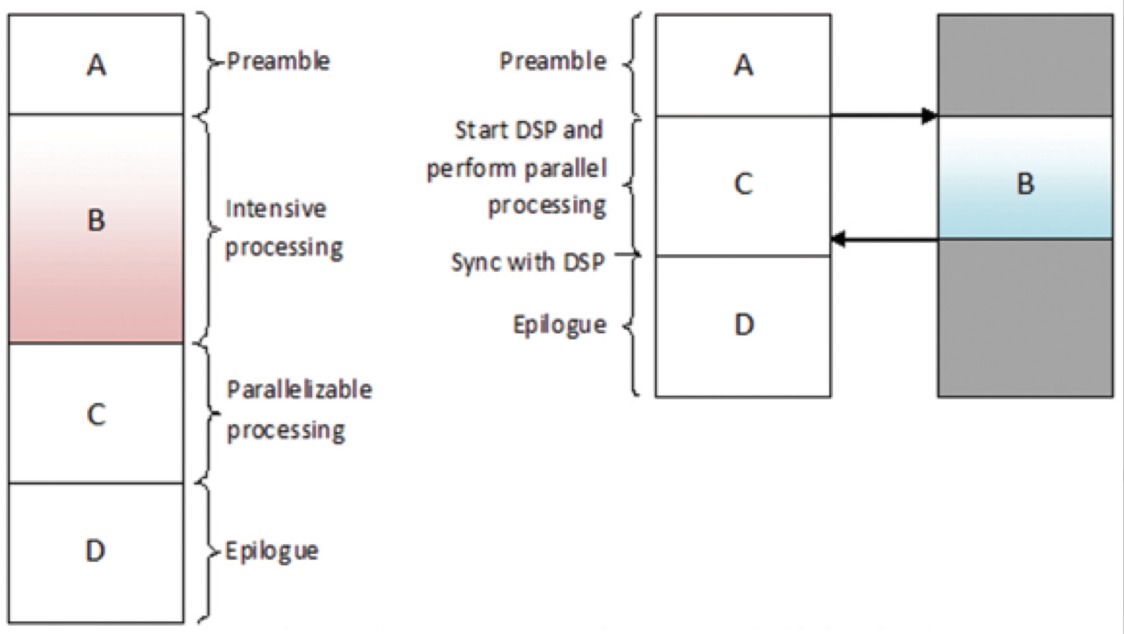
Figure 8. The Canny edge detection algorithm is comprised of several distinct stages.
Overall, these stages map well to GPU acceleration. For example, the Sobel phase – a convolution filter – is easily parallelized and vectorized. And although the hysteresis phase is highly serial in nature, it represents a relatively minor part of the overall computation cycle. Compared to a reference CPU implementation – and again measuring the kernel execution time only – we again see a solid performance boost courtesy of the mobile GPU, even more so once the usual optimization techniques have been applied (Table 3).
|
Resolution |
CPU reference |
Speed-up (native port) |
Speed-up (optimized port) |
|
720p HD |
1 |
7.48x |
37.2x |
|
1800p HD |
1 |
7.24x |
41.1x |
|
4K |
1 |
8.3x |
56.9x |
Table 3. Canny edge detection is a compelling candidate for GPU acceleration.
Specific OpenCL optimizations will depend on the architecture you are targeting. In the case of ARM’s Mali mobile GPU, for example, these optimizations would include vectorization for both arithmetic and load-store operations, along with others. But as before, if all you want to do is process a single frame, the cost of setting up the job and preparing the respective processor caches becomes significant (Figure 9).
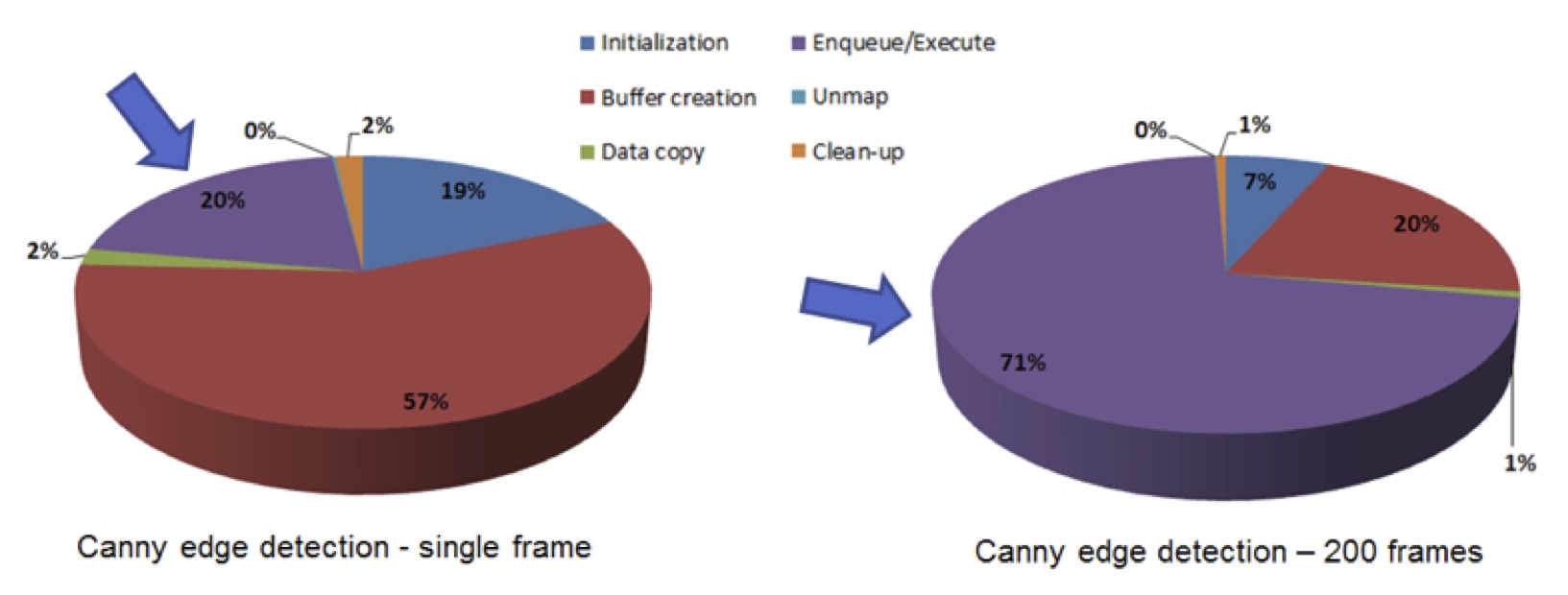
Figure 9. GPU acceleration benefits are only practically achievable when amortized across a large number of processed frames.
On the left, where only a single frame is being processed, you can see that the actual kernel execution only accounts for 20% of the overall time. Conversely, when processing 200 frames as seen on the right, the kernel execution percentage increases to 71%, providing a clearer benefit for GPU-based processing. In general, your computational workload will need to overshadow the overhead, which will often be different than what developers might be used to in PC environments.
One final example will showcase a more ambitious and complex imaging pipeline. The Histogram of Gradients – or HoG – is often employed as part of image recognition pipelines (Figure 10).

Figure 10. HoG is a common algorithm leveraged in computer vision for image recognition.
Each of these stages was implemented and optimized for the Mali GPU. Some further optimizations were also possible; for example, the phase and magnitude calculations require the use of arctangent, which on the CPU is relatively slow, although though it can improved by using an approximation that speeds things up by around 2x. On the other hand, this particular Mali GPU has a built-in and fully accurate arctangent version that runs around 6x faster. Another built-in GPU function – sqrt – also shows similar benefits. In summary, these optimizations lead to significant performance improvements on the GPU, though the scale of improvement depends on the size of the images being processed. As the graph shows, anywhere from a 3x to 8.2x speedup is possible as the image size increases (Figure 11).
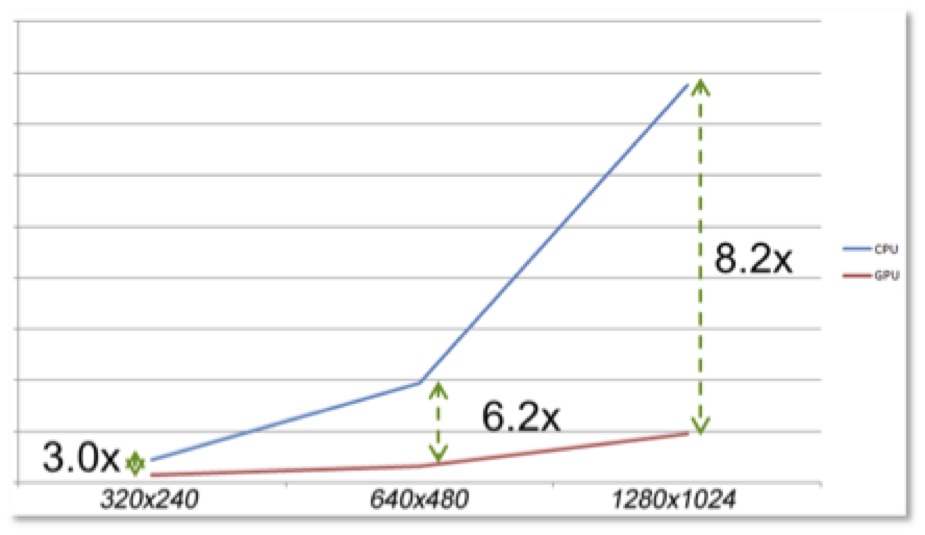
Figure 11. GPU-accelerated speed-ups accelerate with increases in image sizes.
Let’s look at possible further improvements. Looking at each of the five pipeline stages, you can see that some take less time than others (Figure 12). Specifically, both the magnitude and normalize stages account for a very small part of the overall computation, so perhaps you could see improvement by moving them back to the CPU:
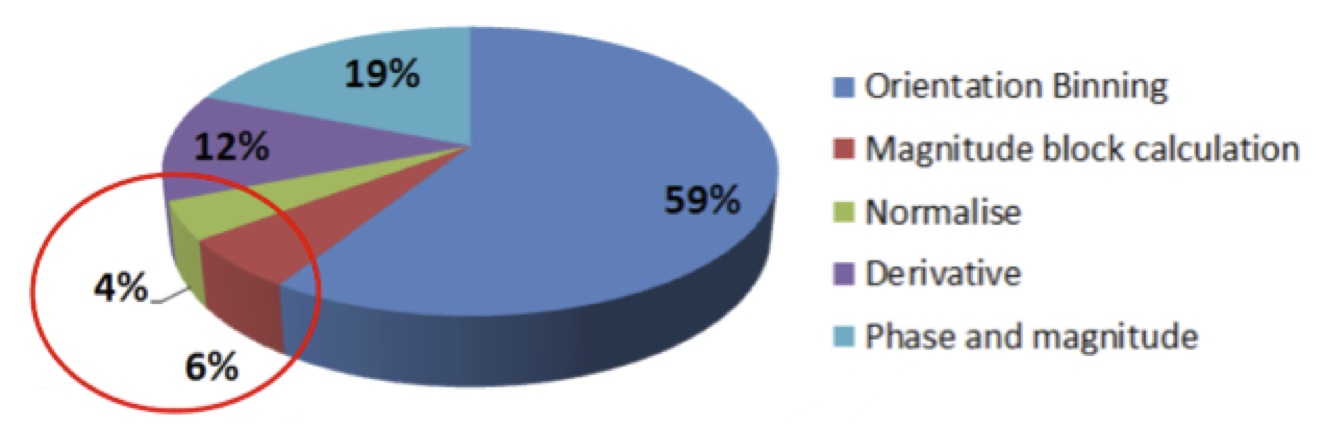
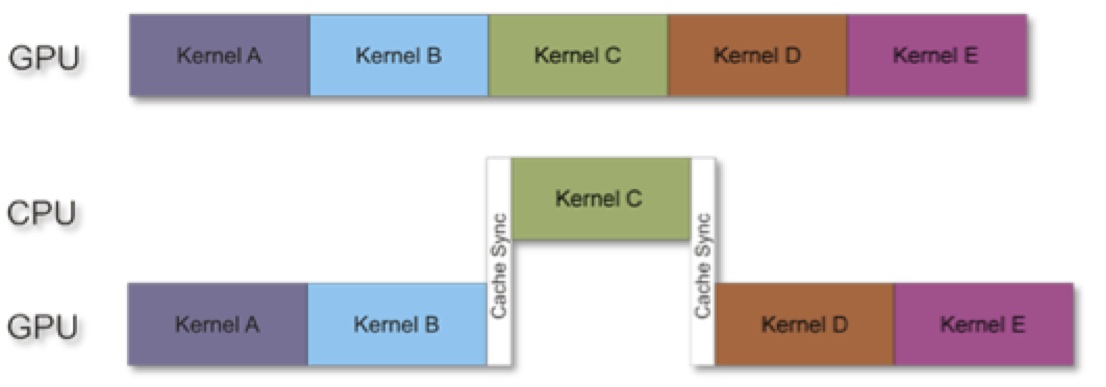
Figure 12. Less complex image processing stages (top) are conceptually attractive candidates for in-parallel execution on the CPU (bottom), but beware of cache synchronization and other resulting overhead.
Unfortunately this re-allocation can cause problems. As the diagram shows, moving a portion of the pipeline back to the CPU could deliver benefits for a particular stage, but in aggregate any additional required cache synchronization might increase the overall execution time.
The final step when optimizing pipelines for mobile heterogeneous platforms is to consider efficient pipelining. For complex vision algorithms that make use of multiple processor types, you need to consider how the different stages in your algorithm are shared within the SoC. This analysis can be a complex and time-consuming process, affected by many variables. A key aim of the effort is to minimize the amount of time any individual processor has to wait for another to complete. These "stall" points represent inefficiencies and are natural targets for optimizing a pipeline as a whole. The aim wherever possible is to keep processing working in parallel, moving from serialized CPU and GPU activity to a more interleaved approach. Thankfully, some great profiling tools, such as ARM's DS5 Streamline performance analyzer, are appearing to assist with this task.
Conclusion
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products. And it can provide significant new markets for hardware, software and semiconductor suppliers. The substantial parallel processing resources available in modern GPUs makes them a natural choice for implementing vision-processing functions. And the OpenCL framework enables the rapid and efficient development of programs that execute across GPUs and other heterogeneous processing elements within a system.
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. AMD, ARM, Imagination Technologies and Intel, the co-authors of this article, are members of the Embedded Vision Alliance. First and foremost, the Embedded Vision Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV. Access is free to all through a simple registration process.
The Embedded Vision Alliance also holds Embedded Vision Summit conferences. Embedded Vision Summits are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. These events are intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May 2016, and a comprehensive archive of keynote, technical tutorial and product demonstration videos, along with presentation slide sets, is available on the Embedded Vision Alliance website and YouTube channel. The next Embedded Vision Summit, along with accompanying workshops, is currently scheduled take place on May 1-3, 2017 in Santa Clara, California. A Europe-based Embedded Vision Summit is also planned for October 12-13, 2017 in Stuttgart, Germany. Please reserve a spot on your calendar and plan to attend.
Additional References:
- Developer Documents for Intel® Processor Graphics
- OpenCL™ Developer Guide for Intel® Processor Graphics
- Ashbaugh, Ben, 2013. Taking Advantage of Intel® Graphics with OpenCL. Retrieved from: https://software.intel.com/en-us/articles/taking-advantage-of-intel-graphics-with-opencl
- Lake, Adam, 2014. How to Increase Performance by Minimizing Buffer Copies on Intel® Processor Graphics. Retrieved from: https://software.intel.com/en-us/articles/getting-the-most-from-opencl-12-how-to-increase-performance-by-minimizing-buffer-copies-on-intel-processor-graphics
- Intel® VTune™ Amplifier XE: Getting started with OpenCL™ performance analysis on Intel® HD Graphics
- Intel® OpenCL™ Code Builder
- Khronos OpenCL Registry
- AMD* OpenCL™ Optimization Guide
- ARM* Mali-T600 Series GPU OpenCL™ Developer Guide
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Harris Gasparakis
OpenCV Manager, AMD
Tim Hartley
Product Manager, Visual Computing, ARM
Dan Petre
Graphics Software Engineer, Intel
with additional contributions from Adam Lake (Intel), Allen Hux (Intel), Deepti Joshi (Intel), John Wiegert (Intel), Tim Bauer (Intel), Robert Ioffe (Intel), Stephen Junkins (Intel), Jerry R. Baugh (Intel), Aaron Kunze (Google), and Murali Sundaresan
Additional contributions from Doug Watt
Multimedia Strategy Manager, Imagination Technologies