UAVs (unmanned aerial vehicles), commonly known as drones, are a rapidly growing market and increasingly leverage embedded vision technology for digital video stabilization, autonomous navigation, and terrain analysis, among other functions. This article reviews drone market sizes and trends, and then discusses embedded vision technology applications in drones, such as image quality optimization, autonomous navigation, collision avoidance, terrain analysis, and subject tracking. It also introduces an industry alliance available to help product creators incorporate robust vision capabilities into their drone designs.
UAVs (unmanned aerial vehicles), which the remainder of this article will refer to by their more common "drone" name, are a key potential growth market for embedded vision. A drone's price point, therefore cost, is always a key consideration, so the addition of vision processing capabilities must not incur a significant bill-of-materials impact. Maximizing flight time is also a key consideration for drones, so low incremental weight and power consumption are also essential for vision processing hardware and software. Fortunately, the high performance, cost effectiveness, low power consumption, and compact form factor of various vision processing technologies have now made it possible to incorporate practical computer vision capabilities into drones, along with many other kinds of systems, and a rapid proliferation of the technology is therefore already well underway.
Note, for example, that vision processing can make efficient use of available battery charge capacity by autonomously selecting the most efficient flight route. More generally, vision processing, when effectively implemented, will incur a notably positive return on your integration investment, as measured both by customer brand and model preference and the incremental price they're willing to pay for a suitably equipped drone design.
Market Status and Forecasts
The market growth opportunity for vision processing in consumer drones, both to expand the total number of drone owners and to encourage existing owners to upgrade their hardware, is notable. Worldwide sales of consumer drones reached $1.9 billion in 2015, according to market analysis firm Tractica, and the market will continue to grow rapidly over the next few years, reaching a value of $5 billion by 2021. Tractica also forecasts that worldwide consumer drone unit shipments will increase from 6.4 million units in 2015 to 67.7 million units annually by 2021 (Figure 1).
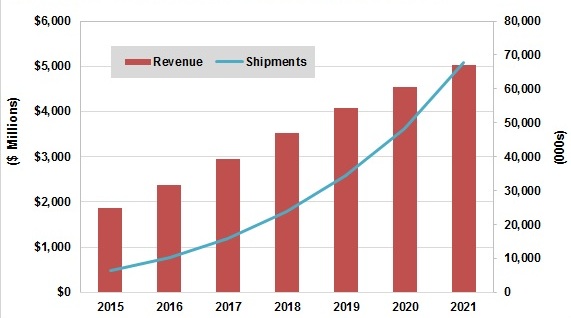

Figure 1. Consumer drone market growth is expected to be dramatic in the coming years (top); drone shipments into commercial applications will also significantly increase (bottom).
The demand for consumer drones, according to Tractica, is driven by the global trends of increasing enthusiasm for high definition imaging for personal use, recreational activities, and aerial games. The possibilities of combining augmented and virtual reality, along with the expanded capabilities of drones and smart devices, is also creating lots of new opportunities in the market. Consumer drones are seeing improved design, quality, and features, while becoming increasingly affordable due to the falling costs of various components, particularly image sensors and the cameras containing them, along with associated imaging and vision processors.
Equally notable, albeit perhaps less widely discussed, is the opportunity for drones to generate value in commercial markets such as film and media, agriculture, oil and gas, and insurance. While the military has been using drones for some time, drones were virtually nonexistent in the commercial market until recently. Decreasing technology costs, leading to decreasing prices, coupled with the emergence of new applications with strong potential return on investment, have created new markets for commercial drones. Although the fleet of commercial drones is currently limited in size, Tractica forecasts that worldwide drone shipments will grow at a rapid pace in the coming decade, rising from shipments of approximately 80,000 units in 2015 to 2.7 million units annually by 2025.
Commercial applications for drones fall into two major categories: aerial imagery and data analysis. Imaging applications involve the utilization of a drone-mounted camera for a multitude of purposes, ranging from the ability to capture aerial footage to the creation of digital elevation maps by means of geo-referencing capabilities. Users have the ability to capture an abundance of images, on their own time schedule and at affordable pricing.
For data analysis applications, one key value of flying a commercial drone happens post-flight. Data collection and image processing capabilities and techniques deliver the ability to produce fine-grained data; anything from crop quantity to water quality can be assessed in a fraction of the time and cost it would take with a low-flying airplane. The reports produced post-flight can offer end users an easy-to-read product that adds value to their operations.
The current commercial usage of drones is centered on niche use cases, although Tractica expects that usage will broaden significantly over the next several years, in the process generating a sizable market not just for drone hardware but also for drone-enabled services. Specifically, Tractica forecasts that global drone-enabled services revenue will increase from $170 million in 2015 to $8.7 billion by 2025 (Figure 2). Most drone-enabled services will rely on onboard imaging capabilities; the largest applications will include filming and entertainment, mapping, prospecting, and aerial assessments.
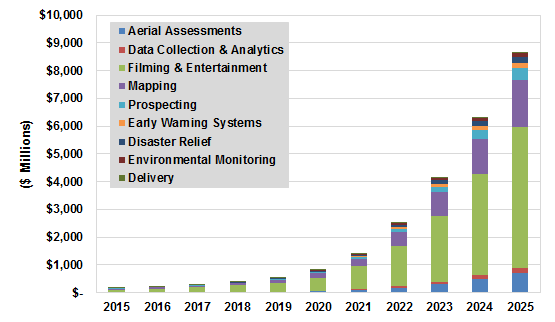
Figure 2. Commercial drone-enabled services revenue will increase in lockstep with hardware sales growth.
In the near term, the four main industries that will lead this market are film, agriculture, media, and oil and gas. The aerial imagery and data analytics functions mentioned previously are the primary drivers for their use in these industries. The capacity to collect, analyze, and deliver information in near real time will continue to be a reason for industries to adopt this technology in their supply chains.
Application Opportunities and Function Needs
Computer vision is a key enabling technology for drone-based applications. Most of these applications today are cloud-based, with imaging data transmitted from the drone via a wireless connection to a backend server where the relevant data is extracted and analyzed. This approach works well if there’s enough bandwidth to send the images over the air with required quality, and if the overall delay between image capture and analysis is acceptable. Newer computer vision applications that run nearly to completely on the drones themselves are promising in opening new markets for drone manufacturers as well as their hardware and software suppliers. Such applications further expand the capabilities of drones to include real-time availability of results, enabling faster decision making by users.
One computer vision-enabled function that's key to these emerging real-time applications for drones is self-navigation. Currently, most drones are flown manually, and battery capacity limits flight time to around 30 to 40 minutes. Vision-based navigation, already offered in trendsetting consumer drones, conversely enables them to chart their own course from point of origin to destination. Such a drone could avoid obstacles, such as buildings and trees, as well as more generally be capable of calculating the most efficient route. Self-navigation will not only obviate the need for an operator in some cases (as well as more generally assist the operator in cases of loss of manual control, when the drone is out of sight, etc.), but will also enable extended battery life, thus broadening the potential applications for drones.
Object tracking is another function where onboard computer vision plays an important role. If a drone is following the movement of a car or a person, it must know what that object looks like and how to track it. Currently, object tracking is largely a manual process; an operator controls the drone via a drone-sourced video feed. In the near future (for commercial applications) and already available (again, in trendsetting consumer drones), conversely, a user can tell the drone to track an object of interest and the drone has sufficient built-in intelligence to navigate itself while keeping the object in sight. Such a function also has the potential to be used in sports, for example, where drones can track the movements of individual players.
Real-time processing is already being used in asset tracking for the construction and mining industries. In such an application, the drone flies over a work site, performs image analysis, identifies movable assets (such as trucks), and notifies the user of their status. Similar technology can also be used in the retail industry to assess inventory levels.
Image Quality Optimization
As previously mentioned, high quality still and video source images are critical to the robust implementation of any subsequent vision processing capabilities. Until recently, correction for the effects of motion, vibration and poor lighting required expensive mechanical components, such as gimbals and customized, multi-element optical lenses. However, new electronic image and video stabilization approaches can eliminate the need for such bulky and complex mechanical components. These new solutions leverage multiple state-of-the-art, real-time image analysis techniques, along with detailed knowledge of drone location, orientation and motion characteristics via accelerometers, gyroscopes, magnetometers and other similar "fusion" sensors, to deliver robust image stabilization performance (Figure 3).
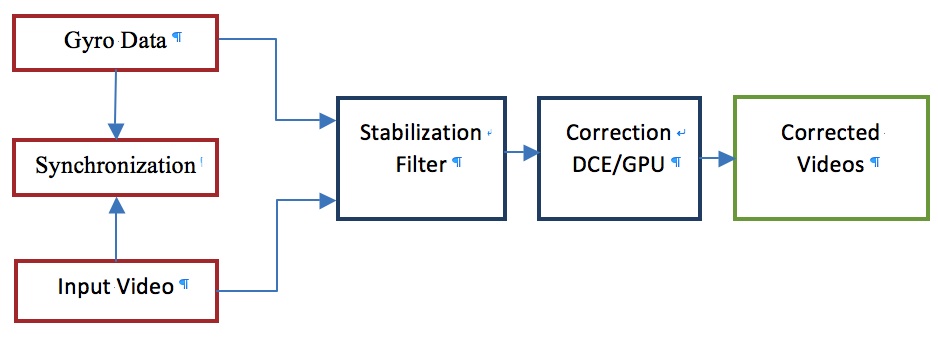
Figure 3. Electronic image stabilization employs multiple data inputs and consists of several function blocks.
Synchronization ensures that the video data and sensor fusion data are time-stamped by the same clock, so that the exact location, orientation and motion of the drone at the time of capture of each video frame are known. This critical requirement needs to be taken into consideration when designing camera platforms.
A dedicated DCE (distortion correction engine) is one an example of a hardware approach to electronic image stabilization. The DCE is a dedicated hardware block (either a chip or silicon IP) that provides flexible 2D image warping capabilities. It supports a wide variety of image deformations, including lens distortion correction, video stabilization (including simultaneous lens geometry correction), perspective correction, and fish eye rectification. Advanced resampling algorithms enable the DCE to deliver high image quality with high-resolution video sources at high frame rates (up to 8K @ 60 FPS) while consuming 18 mW of power.
In the absence of dedicated DCE or equivalent hardware, electronic image stabilization solutions can alternatively leverage the platform’s GPU and/or other available heterogenous computing resources to implement various functions. Such an approach is cost-effective, because it harnesses already existing processors versus adding additional resources to the SoC and/or system design. However, comparative image quality may be sub-optimal, due to capability constraints, and power consumption may also be correspondingly higher.
The adaptive video stabilization filter computes image correction grids, thereby achieving natural looking video across varied recording conditions (Figure 4). It analyzes camera motion and dynamically modifies stabilization characteristics to provide steady shots, as well as reacting quickly when it determines that camera movements are intentional versus inadvertent. Such a filter can leverage motion sensor inputs to address situations in which image analysis alone cannot provide definitive camera motion estimates, thereby further improving stabilization reliability. It also combines lens distortion correction, video stabilization and rolling shutter correction into a unified correction function, in order to minimize the number of image data transfers to and from main memory. The integrated approach also improves image quality without need for multi-sampling.


Figure 4. High frequency rolling shutter artifact removal employs a correction grid (top) to eliminate distortions (bottom).
Autonomous Navigation and Collision Avoidance
Once high quality source images are in hand, embedded vision processing can further be employed to implement numerous other desirable drone capabilities, such as enabling them to fly without earth-bound pilot intervention. A simplified form of autonomous navigation for drones has been available for some time, leveraging GPS localization technologies. Developing an algorithm that tells a drone to travel to a specific set of destination GPS coordinates is fairly simple, and the drone would execute the algorithm in a straighforward and predictable manner…as long as there are no other drones contending for the same airspace, or other impeding object en route.
Unfortunately, many of today's drone owners have discovered the hard way the inherent limitations of GPS-only navigation, after their expensive UAV smashes into a building, bridge, tree, pole, etc. Note, too, that it would be practically impossible to create, far from maintain, sufficiently detailed 3D maps of all possible usage environments, which drones could theoretically use for navigation purposes as do fully autonomous vehicles on a limited-location basis. Fortunately, vision technologies can effectively tackle the navigation need, enabling drones to dynamically react to their surroundings so they can route from any possible origin to destination, while avoiding obstacles along the way.
Collision avoidance is not only relevant for fully autonomous navigation, but also for "copilot" assistance when the drone is primarily controlled by a human being, analogous to today's ADAS (advanced driver assistance systems) features in vehicles. The human pilot might misjudge obstacles, for example, or simply be flying the drone with limited-to-no visibility when it's travelling laterally, backward, or even taking off or landing. In such cases, the pilot might not have a clear view of where the drone is headed; the drone's own image capture and vision processing intelligence subsystems could offer welcome assistance.
The technologies that implement collision avoidance functions are based on the use of one or more cameras coupled to processors that perform the image analysis, extracting the locations, distances and sizes of obstacles and then passing this information to the drone’s autonomous navigation system. The challenges to integrating such technologies include the need to design an embedded vision system that performs quickly and reliably enough to implement foolproof collision avoidance in line with the speed of the drone, in 3 dimensions, and not only when the drone travels along a linear path but also in combination with various rotations.
The vision subsystems cost, performance, power consumption, size and weight all need to be well matched to the drone’s dimensions and target flight time and capabilities. Different embedded vision camera, processor and other technologies will deliver different tradeoffs in all of these areas. Keep in mind, too, that beyond the positional evaluation of the static obstacles that's now becoming available in trendsetting drones, the "holy grail" of collision avoidance also encompasses the detection of other objects in motion, such as birds and other drones. Such capabilities will require even more compute resources than are necessary today, as the reaction time will need to be significantly improved, as well as the need to detect much smaller objects. And as the speeds of both the drone and potential obstacles grows, the need for precision detection and response further increases, since the drone will need to discern objects that are even smaller and farther away than before.
Terrain Analysis and Subject Tracking
For both drone flight autonomy and environment analysis purposes, at least some degree of terrain understanding is necessary. At the most basic level, this information may comprise altitude and/or longitude and latitude, derived from an altimeter (barometer) and/or a GPS receiver. Embedded vision, however, can deliver much more advanced terrain analysis insights.
Downward-facing image sensors, for example, can capture and extract information that can provide a drone with awareness of its motion relative to the terrain below it. By using approaches such as optical flow, where apparent motion is tracked from frame to frame, a downward facing camera and associated processor can even retrace a prior motion path. This awareness of position relative to the ground is equally useful, for example, in circumstances where a GPS signal is unavailable, or where a drone needs to be able to hover in one place without drifting.
As previously mentioned, terrain is increasingly being mapped for commercial purposes, where not only traditional 2D, low-resolution satellite data is needed, but high-resolution and even 3D data is increasingly in demand. A number of techniques exist to capture and re-create terrain in detail. Traditional image sensors, for example, can find use in conjunction with a technique known as photogrammetry in order to "stitch" multiple 2D still images into a 3D map. Photogrammetry not only involves capturing a large amount of raw image data, but also requires a significant amount of compute horsepower. Today, cloud computing is predominantly utilized to generate such 3D models but, as on-drone memory and compute resources become more robust in the future, real-time drone-resident photogrammetry processing will become increasingly feasible.
Alternatives to photogrammetry involve approaches such as LIDAR (laser light-based radar), which can provide extremely high-resolution 3D representations of a space at the expense of the sensor's substantial size, weight, and cost. Mono or stereo pairs of RGB cameras can also be utilized for detecting structure from motion (further discussed in the next section of this article), generating 3D point clouds that are then used to create mesh models of terrain. Such an approach leverages inexpensive conventional image sensors, at the tradeoff of increased necessary computational requirements. Regardless of the image capture technology chosen, another notable consideration for terrain mapping involves available light conditions. Whether or not reliable ambient light exists will determine if it's possible to use a passive sensor array, or if a lighting source (visible, infrared, etc) must be supplied.
A related function to terrain mapping is subject tracking, such as is seen with the “follow me” functions in consumer and prosumer drones. Autonomous vision-based approaches tend to outperform remote-controlled and human-guided approaches here, due to both comparative tracking accuracy and the ability to function without the need for a transmitter mounted to the subject. Subject tracking can be achieved through computer vision algorithms that extract “features” from video frames. Such features depend on the exact approach but are often salient points such as corners, areas of high contrast, and edges. These features can be assigned importance either arbitrarily, i.e. by drawing a bounding box around the object that the user wants the drone to track, or via pre-tracking object classification.
3D Image Capture and Data Extraction
One of the key requirements for a drone to implement any or all of the previously discussed functions is that it have an accurate and complete understanding of its surroundings. The drone should be aware of where other objects are in full 3D space, as well as its own location, direction and velocity. Such insights enable the drone to calculate critical metrics such as distance to the ground and other objects, therefore time to impact with these objects. The drone can therefore plan its course in advance, as well as take appropriate corrective action en route.
It’s common to believe that humans exclusively use their two eyes to sense depth information. Analogously, various techniques exist to discern distance in the computer vision realm, using special cameras. Stereo camera arrays, for example, leverage correspondence between two perspective views of the same scene to calculate depth information. LIDAR measures the distance to an object by illuminating a target with a laser and analyzing the reflected light. Time-of-flight cameras measure the delay of a light signal between the camera and the subject for each point of the image. And the structured light approach projects onto the scene a pattern that is subsequently captured, with distortions extracted and interpreted to determine depth information.
Keep in mind, however, that humans are also easily able to catch a ball with one eye closed. In fact, research has shown that humans primarily use monocular vision to sense depth, via a cue called motion parallax. As we move around, objects that are closer to us move farther across our field of view than do more distant objects. This same cue is leveraged by the structure from motion algorithm to sense depth in scenes captured by conventional mono cameras (see sidebar "Structure from Motion Implementation Details").
With the structure from motion approach, active illumination of the scene (which can both limit usable range and preclude outdoor use) is likely not required. Since a conventional camera (likely already present in the drone for traditional image capture and streaming purposes) suffices, versus a more specialized depth-sensing camera, cost is significant reduced. Leveraging existing compact and lightweight cameras also minimizes the required size and payload of the implementation, thereby maximizing flight time for a given battery capacity.
In comparing 3D sensor-based versus monocular approaches, keep in mind that the former can often provide distance information without any knowledge of the object in the scene. With a stereo camera approach, for example, you only need to know the relative "pose" between the two cameras. Conversely, monocular techniques need to know at least one distance measurement in the scene, i.e. between the scene the camera, in order to resolve any particular scene object's distance and speed. In the example of the ball, for example, a human can catch it because he or she can estimate the size of the ball from past experience with them. Some embedded vision systems will therefore employ both monocular and 3D sensor approaches, since stereo vision processing (for example) can be costly in terms of processing resources but may be more robust in the results it delivers.
Deep Learning for Drones
Traditional post-capture and -extraction image analysis approaches are now being augmented by various machine learning techniques that can deliver notable improvements in some cases. Tracking is more robust across dynamic lighting, weather and other environmental conditions commonly experienced by drones, vehicles and in other applications, for example, along with reliably accounting for changes in the subject being tracked (such as a person who change posture or otherwise moves). Deep learning, a neural network-based approach to machine learning, is revolutionizing the ways that we think about autonomous capabilities and, more generally, solving problems in a variety of disciplines that haven’t been previously feasible in such a robust manner.
Deep learning-based approaches tend to work well with unfamiliar situations, as well as being robust in the face of noisy and otherwise incomplete inputs. Such characteristics make them a good choice for drones and other situations where it is not possible to control the environment or otherwise completely describe the problem to be solved in advance across all possible scenarios. The most studied to-date application of deep learning is image classification, i.e. processing an image and recognizing what objects it contains. Deep learning has been shown to notably perform better than traditional computer vision approaches for this particular task, in some cases even better than humans.
As an example of the power of deep learning in image classification, consider the ImageNet Challenge. In this yearly competition, researchers enter systems that can classify objects in images. In 2012, the first-ever deep learning-based system included in the ImageNet Challenge lowered the error rate versus traditional computer vision-based approaches by nearly 40%, going from a 26% error rate to a 16% error rate. Since then, deep learning-based approaches have dominated the competition, delivering a super-human 3.6% error rate in 2015 (human beings, in comparison, score an approximate 4.9% error rate on the same image data set).
Common real-world drone applications that benefit from deep learning techniques include:
- Image classification: Detecting and classifying infrastructure faults during routine inspections
- Security: Identifying and tracking people of interest, locating objects, and flagging unusual situations
- Search and rescue: Locating people who are lost
- Farm animal and wildlife management: Animal tracking
Deep learning is also a valuable capability in many other applications, such as power line detection, crop yield analysis and improvement and other agriculture scenarios, and stereo matching and segmentation for navigation.
Deep learning-based workflows are notably different (and in many ways simpler) than those encountered in traditional computer vision. Conventional approaches require a software engineer to develop vision algorithms and pipelines that are capable of detecting the relevant features for the problem at hand. This requires expertise in vision algorithms, along with a significant time investment to iteratively fine-tune performance and throughput toward the desired result.
With deep learning, conversely, a data scientist designs the topology of the neural network, subsequently exposing it to a large dataset (consisting of, for the purposes of this article's topics, a collection of images), in an activity known as training. During training, the neural network automatically learns the important features for the dataset, without human intervention. Algorithm advances in conjunction with the availability of cost-effective high-capacity storage and highly parallel processing architectures mean that a network that previously would have taken weeks or months to train can now be developed in mere hours or days.
The resulting neural network model is then deployed on the drone or other target system, which is then exposed to new data, from which it autonomously draws conclusions; classifying objects in images captured from an onboard camera, for example. This post-training activity, known as inferencing, is not as computationally intensive as training but still requires significant processing capabilities. As with training, inference typically benefits greatly from parallel processing architectures; it can also optionally take place on the drone itself, in the "cloud" (if latency is not a concern), or partitioned across both. In general, increased local processing capabilities tend to translate into both decreased latency and increased overall throughput, assuming memory subsystem bandwidth and other system parameters are equally up to the task.
Conclusion
Drones are one of the hottest products in technology today, and their future is bright both in the current consumer-dominated market and a host of burgeoning commercial applications. Vision processing-enabled capabilities such as collision avoidance, broader autonomous navigation, terrain analysis and subject tracking are key features that will transform today's robust drone market forecasts into tomorrow's reality. And more generally, vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products. And it can provide significant new markets for hardware, software and semiconductor suppliers (see sidebar "Additional Developer Assistance").
Sidebar: Structure from Motion Implementation Details
The structure from motion algorithm consists of three main steps:
- Detection of feature points in the view
- Tracking feature points from one frame to another
- Estimation of the 3D position of these points, based on their motion
The first step is to identify candidate points in a particular image that can be robustly tracked from one frame to the next (Figure A). Features in texture-less regions such as blank walls and blue skies are difficult to localize. Conversely, many objects in a typical scene contain enough texture and geometry data to enable robust tracking from one frame to another. Locations in the captured image where you find gradients in two significantly different orientations, for example, are good feature point candidates. Such features show up in the image as corners or other places where two lines come together. Various feature detection algorithms exist, many of which have been widely researched in the computer vision community. The Harris feature detector, for example, works well in this particular application.
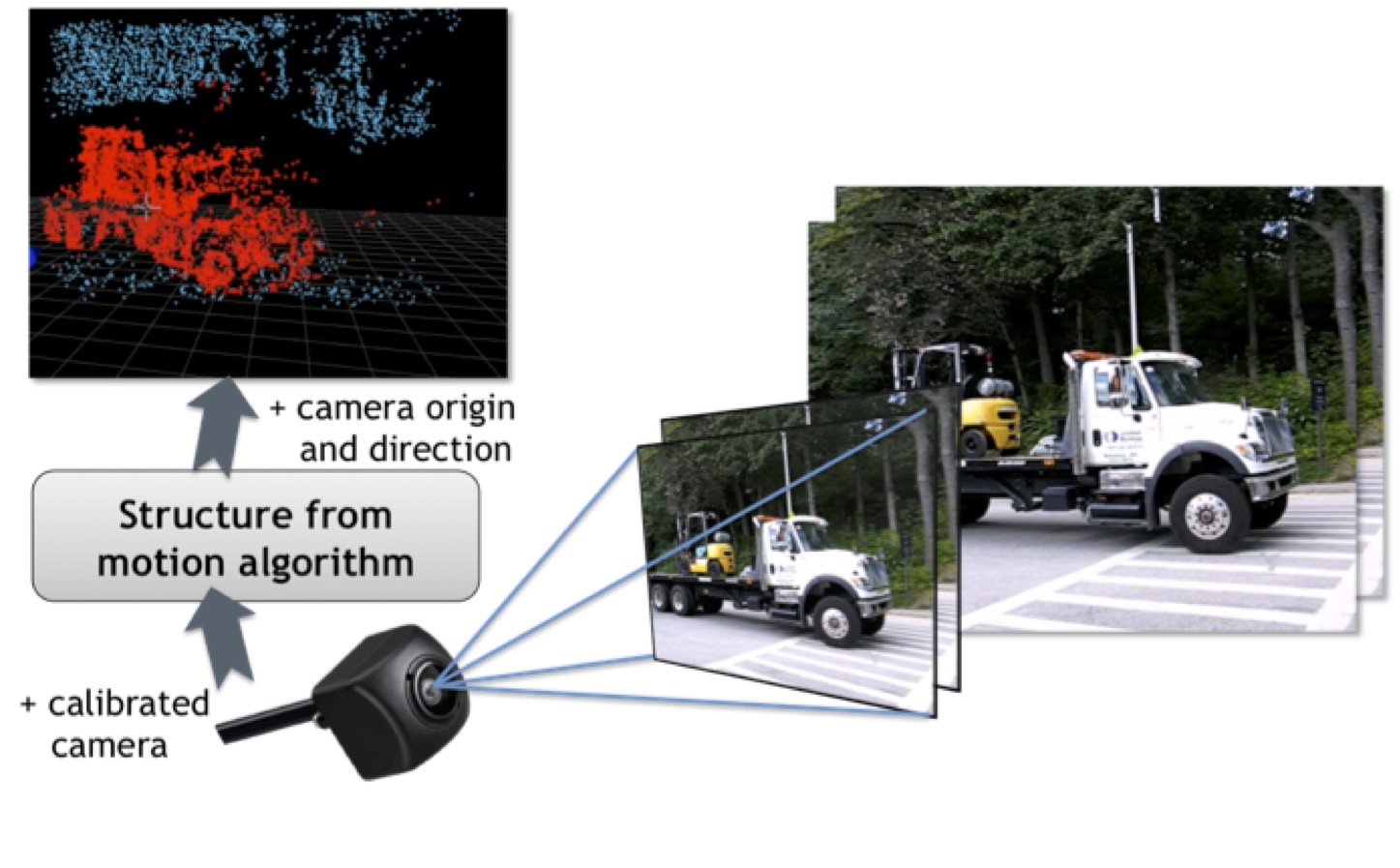
Figure A. The first step in the structure from motion algorithm involves identifying reliable frame-to-frame tracking feature point candidates (courtesy VISCODA).
Next, the structured motion algorithm needs to track these feature points from frame to frame, in order to find out how much they've moved in the image. The Lucas-Kanade optical flow algorithm is typically used for this task. The Lucas-Kanade algorithm first builds a multi-scale image pyramid, where each image is a smaller scaled image of the originally captured frame. The algorithm then searches in the vicinity of the previous frame’s feature point location for a match in the current image frame. When the match is found, this position becomes the initial estimate for the feature's location in the next-larger image in the pyramid; the algorithm travels through the pyramid until it reaches the original image resolution version. This way, it's also possible to track larger feature displacements.
The result consists of two lists of corresponding feature points, one for the previous image and one for the current image. From these point pairs, the structured motion algorithm can define and solve a linear system of equations that determines the camera motion, and consequently the distance of each point from the camera (Figure B). The result is a sparse 3D point cloud in "real world" coordinates that covers the camera’s viewpoint. Subsequent consecutive image frames typically add additional feature points to this 3D point cloud, combining it into a point database that samples the scene more densely. Multiple cameras each capturing its own point cloud, are necessary in order to capture the drone's entire surroundings. These individual-perspective point clouds can then be merged into a unified data set, capable of functioning as a robust input to a subsequent path planning or collision avoidance algorithm.

Figure B. After identifying corresponding feature points in consecutive image frames, solving a system of linear equations can determine motion characteristics of the camera and/or subject, as well as the distance between them (courtesy VISCODA).
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. FotoNation, Movidius, NVIDIA, NXP and videantis, co-authors of this article, are members of the Embedded Vision Alliance. The Embedded Vision Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other deep learning frameworks. Access is free to all through a simple registration process.
The Embedded Vision Alliance also holds Embedded Vision Summit conferences. Embedded Vision Summits are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. These events are intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May 2016, and a comprehensive archive of keynote, technical tutorial and product demonstration videos, along with presentation slide sets, is available on the Embedded Vision Alliance website and YouTube channel. The next Embedded Vision Summit, along with accompanying workshops, is currently scheduled take place on May 1-3, 2017 in Santa Clara, California. Please reserve a spot on your calendar and plan to attend.
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Kevin Chen
Senior Director, Senior Director, Technical Marketing, FotoNation
Jack Dashwood
Marketing Communications Director, Movidius
Jesse Clayton
Product Manager of Autonomous Machines, NVIDIA
Stéphane François
Software Program Manager, NXP Semiconductors
Anand Joshi
Senior Analyst, Tractica
Manoj Sahi
Research Analyst, Tractica
Marco Jacobs
Vice President of Marketing, videantis