|
Dear Colleague,
We’ve got a lot of exciting things lined up for the 2018
Embedded Vision Summit, newly expanded to a four-day
event taking place May 21-24 in Santa Clara, California. From
80+ technical
sessions, to 100+ technology
demos, to keynote
presentations from industry luminaries Dean Kamen and Dr. Takeo
Kanade—if it has to do with computer vision, you’ll see it at the
Summit! You can still save 15%
off your registration pass with our Early
Bird Discount. Just use promo code NLEVI0313 when you register
online.
Also note that entries for the premier Vision Product of the Year
awards, to be presented at the Summit, are now
being accepted.
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
|
Positions Available for Computer Vision Engineers at DEKA
Research
Inventor Dean Kamen founded DEKA to focus
on innovations aimed to improve lives around the world. DEKA has
deep roots in mobility: Dean invented the Segway out of his work
on the iBot wheel chair. Now DEKA is adding autonomous navigation
to its robotic mobility platform. The company is leveraging advances in
computer vision to address the challenges of autonomous navigation in
urban environments at pedestrian to bicycle speeds on streets, bike
paths, and sidewalks. DEKA is seeking engineers with expertise in
all facets of autonomous navigation and practical computer vision –
from algorithm development to technology selection to system
integration and testing – and who are passionate about building,
designing, and shipping projects that have a positive, enduring impact
on millions of people worldwide. Interested candidates should
send a resume and cover letter to [email protected].
Also see the recent discussion forum postings from Algolux for
jobs located in both Silicon
Valley, California and Montreal,
Canada.
|
|
Data Sets for Machine Learning Model Training
Deep learning and other machine learning
techniques have rapidly become a transformative force in computer
vision. Compared to conventional computer vision techniques, machine
learning algorithms deliver superior results on functions such as
recognizing objects, localizing objects within a frame, and determining
which pixels belong to which object. Even problems like optical flow
and stereo correspondence, which had been solved quite well with
conventional techniques, are now finding even better solutions using
machine learning techniques. The pace of machine learning
development remains rapid. And in comparison to traditional computer
vision algorithms, with machine learning it’s easier to create effective solutions for new
problems without requiring a huge team of specialists. But machine
learning is also resource-intensive, as measured by its compute and
memory requirements. And, as this article from the Embedded Vision
Alliance and member companies AImotive, BDTI, iMerit and Luxoft
explains, for machine learning to deliver its potential,
it requires a sufficient amount of high quality training data, plus
developer knowledge of how to properly use it.
Also see the related presentation “Using
Markerless Motion Capture to Win Baseball Games” from KinaTrax,
which developed a vision-based analytics product for baseball teams.
Unsupervised Everything
The large amount of multi-sensory data
available for autonomous intelligent systems is just astounding, notes
Luca Rigazio, Director of Engineering for the Panasonic Silicon Valley
Laboratory, in this presentation. The power of deep architectures to
model these practically unlimited datasets is limited by only two
factors: computational resources and labels for supervised learning.
Rigazio argues that the need for accurate labels is by far a bigger
problem, as it requires careful interpretation of what to label and
how, especially in complex and multi-sensory settings. At the risk of
stating the obvious, we just want unsupervised learning to work for
everything we do, right now. While this has been a “want” of the
AI/Machine-Learning community for quite some time, unsupervised
learning has recently made an impressive leap. Rigazio discusses the
latest breakthroughs and highlights the massive potential for
autonomous systems, as well as presenting the latest results from his
team.
|
|
Collaboratively Benchmarking and Optimizing Deep Learning
Implementations
For car manufacturers and other OEMs,
selecting the right processors to run deep learning inference for
embedded vision applications is a critical but daunting task. One
challenge is the vast number of options in terms of neural network
models, frameworks (such as Caffe, TensorFlow, Torch), and libraries
such as CUDA and OpenCL. Another challenge is the large number of
network parameters that can affect the computation requirements, such
the choice of training data sets, precision, and batch size. These
challenges also complicate efforts to optimize implementations of deep
learning algorithms for deployment. In this talk, Unmesh Bordoloi,
Senior Researcher at General Motors, presents a methodology and
open-source software framework for collaborative and reproducible
benchmarking and optimization of convolutional neural networks. General
Motors’ software framework, CK-Caffe, is based on the Collective
Knowledge framework and the Caffe framework. GM invites the community
to collaboratively evaluate, design and optimize convolutional neural
networks to meet the performance, accuracy and cost requirements of a
variety of applications – from sensors to self-driving cars.
Approaches for Vision-based Driver Monitoring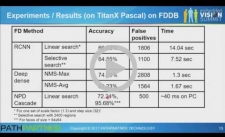
Since many road accidents are caused by
driver inattention, assessing driver attention is important to
preventing accidents. Distraction caused by other activities and
sleepiness due to fatigue are the main causes of driver inattention.
Vision-based assessment of driver distraction and fatigue must estimate
face pose, sleepiness, expression, etc. Estimating these aspects under
real driving conditions, including day-to-night transition, drivers
wearing sunglasses, etc., is a challenging task. A solution using deep
learning to handle tasks from searching for a driver’s face in a given
image to estimating attention would potentially be difficult to realize
in an embedded system. In this talk, Jayachandra Dakala, Technical
Architect at PathPartner Technology, looks at the pros and cons of
various machine learning approaches like multi-task deep networks,
boosted cascades, etc. for this application, and then describes a
hybrid approach that provides the required insights while being
realizable in an embedded system.
|
