|
The OpenVX Computer Vision and Neural Network Inference Library Standard for Portable, Efficient Code
OpenVX is an industry-standard computer vision and neural network inference API designed for efficient implementation on a variety of embedded platforms. The API incorporates the concept of a dataflow graph, which enables processor and tool developers to apply a range of optimizations appropriate to their architectures, such as image tiling and kernel fusion. Application developers can use this API to create high-performance computer vision and AI applications quickly, without having to perform complex device-specific optimizations for data management and kernel execution, since these optimizations are handled by the OpenVX implementation provided by the processor vendor. This presentation from Radhakrishna Giduthuri describes the current status of OpenVX, with particular focus on neural network inference capabilities and the most recent enhancements. The talk concludes with summary of the currently available implementations and an overview of the roadmap for the OpenVX API and its implementations.
The Evolution and Maturation of the OpenVX Standard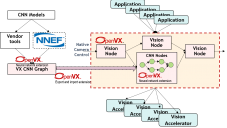
A newly published two-article series from the Alliance and member companies Cadence, Intel, NXP Semiconductors and VeriSilicon details the latest developments related to Khronos' OpenVX standard for cross-platform acceleration of computer vision applications. "OpenVX Enhancements, Optimization Opportunities Expand Vision Software Development Capabilities" covers recent updates to OpenVX, including the latest v1.2 specification and associated conformance tests, along with the recently published set of optional extensions. It also discusses the optimization opportunities available to make use of increasingly common heterogeneous computing architectures. And "OpenVX Implementations Deliver Robust Computer Vision Applications" showcases several detailed OpenVX design examples in various applications, leveraging multiple hardware platforms along with both traditional and deep learning computer vision algorithms.
|
|
Programming Techniques for Implementing Inference Software Efficiently
When writing software to deploy deep neural network inferencing, developers are faced with an overwhelming range of options, from a custom-coded implementation of a single model to using a deep learning framework like TensorFlow or Caffe. If you custom code your own implementation, how do you balance the competing needs of performance, portability and capability? If you use an off-the-shelf framework, how do you get good performance? Andrew Richards, CEO and Founder of Codeplay Software, and his company have been building and standardizing developer tools for GPUs and AI accelerators for over 15 years. This talk from Richards explores the approaches available for implementing deep neural networks in software, from the low-level details of how to map software to the highly parallel processors needed for AI all the way up to major AI frameworks. He starts with the LLVM compiler chain used to compile for most GPUs, through the OpenCL, HSA and SYCL programming standards (including how they compare with CUDA), all the way up to TensorFlow and Caffe and how they affect key metrics like performance.
Machine Learning Inference In Under 5 mW with a Binarized Neural Network on an FPGA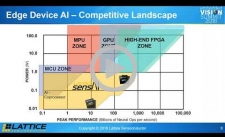
The demand for always-on intelligence is rapidly increasing in various applications. You can find cameras that are always watching for anomalies in a manufacturing line, monitoring vehicle speeds on roads, or looking for a specific gesture or person. Since these cameras have to be always on, security and power consumption become concerns. Users don’t want the captured images to be sent to the cloud (available for hackers to access) and therefore item or anomaly detection must occur locally vs. in the cloud. This increases local computational requirements, which potentially increases power consumption – a major issue for battery-powered products. This presentation from Abdullah Raouf, Senior Marketing Manager at Lattice Semiconductor, provides an overview of how FPGAs, such as Lattice’s iCE40 UltraPlus, are able to implement multiple binarized neural networks in a single 2 mm x 2 mm package to provide always-on intelligence without relying on cloud computation.
|
