|
Dear Colleague,
Lattice Semiconductor will deliver the free webinar “Architecting
Always-On, Context-Aware, On-Device AI Using Flexible Low-power FPGAs”
on October 30, 2018 at 9 am Pacific Time, in partnership with the
Embedded Vision Alliance. The webinar will be presented by Deepak
Boppana, the company’s Senior Director of Marketing, and Gordon Hands,
Marketing Director for IP and Solutions (and a highly-rated Embedded Vision Summit presenter). In this webinar, the presenters will
leverage the company’s experience in developing low-cost, low-power,
always-on, vision-based AI solutions to illustrate deep learning
inferencing design tradeoffs and explore optimizations across edge
processing implementations ranging from 1 mW to 1 W and $1 to $10. For
more information, and to register, see the event
page.
The next session of the Embedded Vision Alliance’s in-person,
hands-on technical training class series, Deep Learning for
Computer Vision with TensorFlow, takes place in two weeks
in San Jose, California. These classes give you the critical knowledge
you need to develop deep learning computer vision applications with
TensorFlow. The one-day class takes place on October 4, 2018. Details,
including online registration, can be found here.
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
|
Computer Vision for Augmented Reality in Embedded Designs
Augmented reality (AR) and related
technologies are becoming increasingly popular and
prevalent, led by their adoption in smartphones, tablets and other
mobile computing and communications devices. While developers of more
deeply embedded platforms are also motivated to incorporate AR
capabilities in their products, the comparative scarcity of processing,
memory, storage, and networking resources is challenging, as are cost,
form factor, power consumption and other constraints. However, by
making effective use of available compute capabilities, along with
APIs, middleware and other software toolsets, implementing robust AR in
resource-constrained designs is increasingly feasible.
Building Efficient CNN Models for Mobile and Embedded
Applications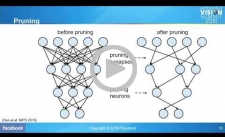
Recent advances in efficient deep learning
models have led to many potential applications in mobile and embedded
devices. In this talk, Peter Vajda, Research Scientist at Facebook,
discusses state-of-the-art model architectures, and introduces
Facebook’s work on real-time style transfer and pose estimation on
mobile phones.
|
|
Generative Sensing: Reliable Recognition from Unreliable
Sensor Data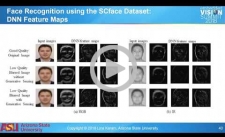
While deep neural networks (DNNs) perform
on par with – or better than – humans on pristine high-resolution
images, DNN performance is significantly worse than human performance
on images with quality degradations, which are frequently encountered
in real-world applications. This talk from Lina Karam, Professor and
Computer Engineering Director at Arizona State University, introduces a
new generative sensing framework which integrates low-end sensors with
computational intelligence to attain recognition accuracy on par with
that attained using high-end sensors. This generative sensing framework
aims to transform low-quality sensor data into higher quality data in
terms of classification accuracy. In contrast with existing methods for
image generation, this framework is based on discriminative models and
aims to maximize recognition accuracy rather than a similarity
measure. This is achieved through the introduction of selective feature
regeneration in a deep neural network.
Neuromorphic Event-based Computer Vision: Sensors, Theory and
Applications
In this presentation, Ryad B. Benosman,
Professor at the University of Pittsburgh Medical Center, Carnegie
Mellon University and Sorbonne Universitas, introduces neuromorphic,
event-based approaches for image sensing and processing.
State-of-the-art image sensors suffer from severe limitations imposed
by their very principle of operation. These sensors acquire visual
information as a series of “snapshots” recorded at discrete points in
time, hence time-quantized at a predetermined frame rate, resulting in
limited temporal resolution, low dynamic range and a high degree of
redundancy in the acquired data. Nature suggests a different approach:
Biological vision systems are driven and controlled by events happening
within the scene in view, and not – like conventional image sensors –
by artificially created timing and control signals that have no
relation to the source of the visual information. Translating the
frameless paradigm of biological vision to artificial imaging systems
implies that control over the acquisition of visual information is no
longer imposed externally on an array of pixels but rather the decision
making is transferred to each individual pixel, which handles its own
information individually. Benosman introduces the fundamentals
underlying such bio-inspired, event-based image sensing and processing
approaches, and explores their strengths and weaknesses. He shows that
bio-inspired vision systems have the potential to outperform
conventional, frame-based vision acquisition and processing systems and
to establish new benchmarks in terms of data compression, dynamic
range, temporal resolution and power efficiency in applications such as
3D vision, object tracking, motor control and visual feedback loops, in
real-time.
|
|
Deep
Learning for Computer Vision with TensorFlow Training Class:
October 4, 2018, San Jose,
California
Lattice Semiconductor Webinar – Architecting
Always-On, Context-Aware, On-Device AI Using Flexible Low-power FPGAs:
October 30, 2018, 9:00 am PT
Embedded
Vision Summit: May 20-23, 2019, Santa Clara,
California
More Events
|
